It wasn't 35x to 72x, but 70x to 72x, in debug. While this also shows a clear impact on the applications overall performance, its not as good as it originally seemed :(
I also forgot one important step: In the old brute-force algorithm, I could still check for the masks early on to skip some potential matched, and even remove some reported collisions, which would result in (empty) script-calls. Doing that, now the brute-force is catching up at halfway, reaching 71x.
So at those numbers, it would be important to actually measure the timings of just those two algorithms under different Ns, to get a better feeling for how much the binning actually wins. Which I'll probably do later, also have to work on the game in between
Juliean said: Wuut? Are you sure that you didn't introduce some suble error in the algorithm for eigther case? I mean, it does find the same number of elements, but even I would not have expected this to happen for that many objects.
No. didn't change anything.
Juliean said: Alternatively, maybe its because with that many elements, the cells all become “satured”
No, shouldn't be.
But likely yes. I will do some statistics on the grid to see if there is some bug. Likely there is a bug. I was already confused about having written all the stuff (excluding BVH) in short time and one go, and there was no little problem i had to mess around with.
um, does this give the same performance as int all = 0b11111, and old school bit math?
Your code really makes me feel old. I can't read it. It's too fancy modern. <: )
My bug was easy to find. I have transformed the point to grid space, but then accidentally used the original point to get grid coordinates. After that, the usual suspects of one off errors and boundary conditions came up. So i felt at home with damn grids. But world is sane again. Perf. is now as expected.
But now i have the other problem i forgot about: With grid methods it's no longer guaranteed A finds B, and B also finds A. So i can't simply compare address to find out if the collision is already processed. I will add an index per object, and use N^2 bits for a look up. This sucks, but i never came up with a better solution for this issue.
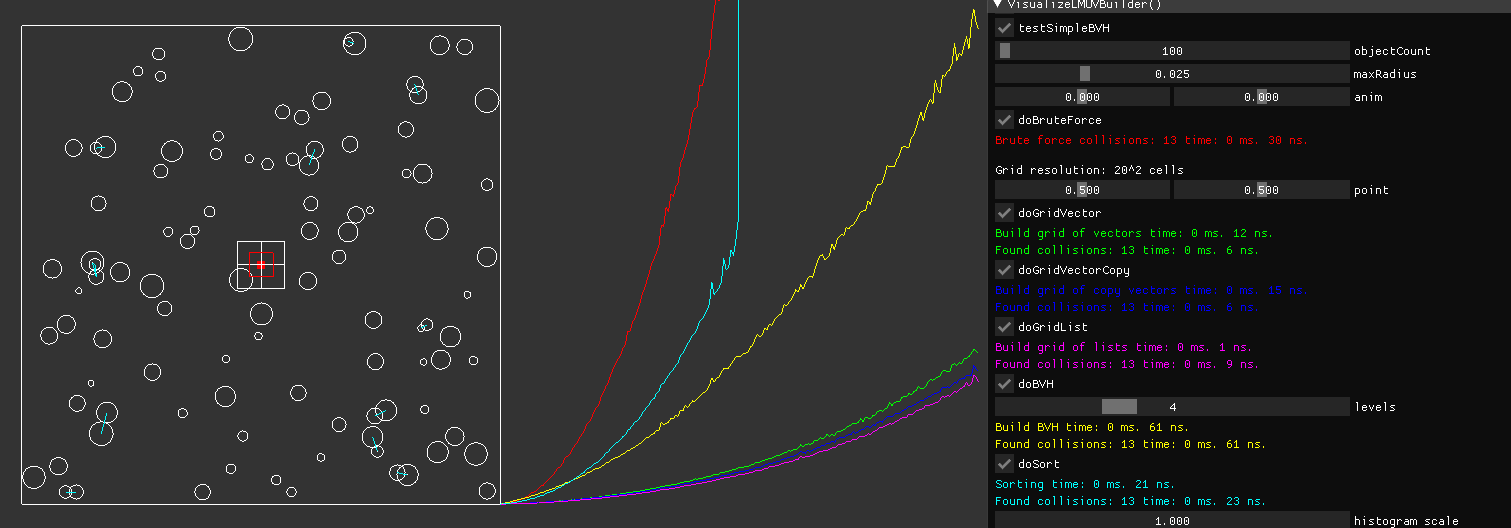
And i have added a nice histogram to visualize timing results with increasing N : ) Currently grids do all very similar, 4-5 * faster than BVH, and brute force sky rockets. Still need to add the sorting method.
Sorry for the confusion from before. But the histogram is a nice compensation for that, i hope. ; ) It shows the timings from 0 - 10000 objects from left to right. I have disabled brute force and sorting graphs after 5000 objects, because frame rate became too bad to fill histogram while dragging the slider.
The only problem is that the results are now pretty boring, without surprises. List per grid cell wins, followed by vector of objects per cell, then vector of pointers. BVH isn't that bad, if you can't afford huge grids. Quadtree should be pretty similar i guess.
@ivica kolic Please take a look at the sorting code and propose improvement. I do not understand how to benefit from sorting by size additionally, or having both start and end point sorted. I did just a trivial search around the current object, and assume there's a some way?
Btw, in the past i have tried to sort by morton code, to get some multi-dimension improvement. But that's bad. Depending on query position, you might need to go through all objects.
@juliean I did not mind to make a local references on other static variables. Usually i never use them, only in such small test snippets. Now i need to ask again: Does each access to static variables include a check if they are already initialized? Even every time in a loop, for example? If so, i should for sure change this, as most data here is static vectors.
Edit: code updated with faster tiled BVH approach
static bool testSimpleBVH = 1; ImGui::Checkbox("testSimpleBVH", &testSimpleBVH);
if (testSimpleBVH)
{
// make some random objects
static bool init = true;
static float maxRadius = 0.025f;
static int objectCount = 0;
if (ImGui::SliderInt ("objectCount", &objectCount, 0, 10000)) init = true;
if (ImGui::SliderFloat ("maxRadius", &maxRadius, 0.001f, 0.1f)) init = true;
static vec2 anim(0.f, 0.f); ImGui::SliderFloat2("anim", (float*)&anim, -1.f,1.f);
struct Object
{
vec2 pos;
float radius;
Object *next = 0; // used only for the grid list
int index = 0;
Object()
{
pos = vec2( float(std::rand()) / float(RAND_MAX), float(std::rand()) / float(RAND_MAX));
pos += anim * maxRadius;
pos[0] = max(maxRadius*1.01f, min(1.f-maxRadius*1.1f, pos[0]));
pos[1] = max(maxRadius*1.01f, min(1.f-maxRadius*1.1f, pos[1]));
radius = (1.f + 3.f * float(std::rand()) / float(RAND_MAX)) * .25f * maxRadius;
}
};
static std::vector<Object> objects;
static std::vector<bool> pairMask;
if (init)
{
objects.resize(objectCount);
pairMask.resize(objectCount*objectCount);
}
std::srand(1);
for (int i=0; i<objects.size(); i++)
{
auto &obj = objects[i];
obj = Object();
obj.index = i;
RenderCircle(obj.radius, obj.pos, vec(0,0,1), 1,1,1);
}
auto Intersects = [](const Object &o0, const Object &o1)
{
float sqDist = vec2(o0.pos - o1.pos).SqL();
float dist = sqrt(sqDist);
return (dist < o0.radius + o1.radius);
};
auto IntersectsG = [&](const Object &o0, const Object &o1)
{
int i0 = o0.index;
int i1 = o1.index;
if (i0 == i1)
return false;
if (i0 > i1) std::swap(i0, i1);
int bitIndex = i0*objectCount + i1;
if (pairMask[bitIndex])
return false; // already processed
pairMask[bitIndex] = true;
float sqDist = vec2(o0.pos - o1.pos).SqL();
float dist = sqrt(sqDist);
return (dist < o0.radius + o1.radius);
};
// brute force
static bool doBruteForce = 0; ImGui::Checkbox("doBruteForce", &doBruteForce);
uint64_t timeBruteForce = ULLONG_MAX;
if (doBruteForce && objects.size()<5000) // too slow to fill histogram with larger number
{
uint64_t time = SystemTools::GetTimeNS();
timeBruteForce = time;
const int count = objects.size();
int collCount = 0;
for (int i=0; i<count-1; i++)
for (int j=i+1; j<count; j++)
{
const auto &o0 = objects[i];
const auto &o1 = objects[j];
if (Intersects(o0, o1))
collCount++, RenderLine(o0.pos, o1.pos, 1,0,0); // appends vertices and color to a buffer
}
ImGui::TextColored(ImVec4(1,0,0,1), "Brute force collisions: %i time: %s", collCount, SystemTools::GetDurationStringAndRestart(time).c_str());
timeBruteForce = time-timeBruteForce;
}
// grid...
int gridDim = (int)ceil(.5f / maxRadius);
float gridRes = float(gridDim);
float cellSize = 1.f / gridRes;
ImGui::Text("\nGrid resolution: %i^2 cells", gridDim);
auto PointToGridCoords = [&](int &x, int &y, const vec2 &p)
{
vec2 pg = p * gridRes;// + vec2(.5f);
x = (int) pg[0];
y = (int) pg[1];
assert (x>=0 && x<gridDim &&
y>=0 && y<gridDim);
};
if (1) // debug grid
{
auto VisCell = [=](int x, int y)
{
vec2 p0 (float(x) / gridRes, float(y) / gridRes);
vec2 p1 (float(x+1) / gridRes, float(y+1) / gridRes);
RenderAABBox (p0, p1, 1,1,1);
};
RenderAABBox (vec2(0,0), vec2(1,1), 1,1,1);
static vec2 point(0.5f, 0.5f); ImGui::SliderFloat2("point", (float*)&point, maxRadius*1.1f, 1.f-maxRadius*1.1f);
int x, y; PointToGridCoords (x, y, point);
VisCell (x,y);
vec2 bmin = point - vec2(maxRadius, maxRadius);
vec2 bmax = point + vec2(maxRadius, maxRadius);
int minX, minY; PointToGridCoords (minX, minY, bmin);
int maxX, maxY; PointToGridCoords (maxX, maxY, bmax);
for (int y=minY; y<=maxY; y++)
for (int x=minX; x<=maxX; x++)
{
VisCell (x,y);
}
RenderPoint(point, 1,0,0);
RenderAABBox (bmin, bmax, 1,0,0);
}
// grid of std::vector, adding each object to multiple cells
static bool doGridVector = 0; ImGui::Checkbox("doGridVector", &doGridVector);
uint64_t timeGridV = ULLONG_MAX;
if (doGridVector)
{
#if 0
uint64_t time = SystemTools::GetTimeNS();
std::vector<std::vector<Object*>> grid;
grid.resize(gridDim*gridDim);
#else
static std::vector< std::vector<Object*> > gridGlobal;
if (init || !gridGlobal.size()) gridGlobal.resize(gridDim*gridDim);
std::fill(pairMask.begin(), pairMask.end(), false); // excluding from measurement, becasue that's soemtimes ridiculously slow and should be replaced
uint64_t time = SystemTools::GetTimeNS();
timeGridV = time;
auto& grid = gridGlobal;
for (auto &list : grid) list.clear();
#endif
for (auto &obj : objects)
{
int minX, minY; PointToGridCoords (minX, minY, obj.pos - vec2(obj.radius, obj.radius));
int maxX, maxY; PointToGridCoords (maxX, maxY, obj.pos + vec2(obj.radius, obj.radius));
assert (maxX-minX<2 && maxY-minY<2);
for (int y=minY; y<=maxY; y++)
for (int x=minX; x<=maxX; x++)
{
grid[x + y*gridDim].push_back(&obj);
//VisCell (x, y);
}
}
ImGui::TextColored(ImVec4(0,1,0,1), "Build grid of vectors time: %s", SystemTools::GetDurationStringAndRestart(time).c_str());
int collCount = 0;
for (const auto &o0 : objects)
{
int x, y; PointToGridCoords (x, y, o0.pos);
auto &list = grid[x + y*gridDim];
for (const auto *o1 : list)
{
if (IntersectsG(o0, *o1))
collCount++, RenderLine(o0.pos, o1->pos, 0,1,0);
}
}
ImGui::TextColored(ImVec4(0,1,0,1), "Found collisions: %i time: %s", collCount, SystemTools::GetDurationStringAndRestart(time).c_str());
timeGridV = time - timeGridV;
}
// grid of std::vector, adding a copy of each object to multiple cells
static bool doGridVectorCopy = 0; ImGui::Checkbox("doGridVectorCopy", &doGridVectorCopy);
uint64_t timeGridVC = ULLONG_MAX;
if (doGridVectorCopy)
{
static std::vector< std::vector<Object> > gridGlobal;
if (init || !gridGlobal.size()) gridGlobal.resize(gridDim*gridDim);
std::fill(pairMask.begin(), pairMask.end(), false);
uint64_t time = SystemTools::GetTimeNS();
timeGridVC = time;
auto& grid = gridGlobal;
for (auto &list : grid) list.clear();
for (auto &obj : objects)
{
int minX, minY; PointToGridCoords (minX, minY, obj.pos - vec2(obj.radius, obj.radius));
int maxX, maxY; PointToGridCoords (maxX, maxY, obj.pos + vec2(obj.radius, obj.radius));
assert (maxX-minX<2 && maxY-minY<2);
for (int y=minY; y<=maxY; y++)
for (int x=minX; x<=maxX; x++)
{
grid[x + y*gridDim].push_back(obj);
}
}
ImGui::TextColored(ImVec4(0,0,1,1), "Build grid of copy vectors time: %s", SystemTools::GetDurationStringAndRestart(time).c_str());
if (0) // grid statistics
{
int sum = 0;
int maxCount = 0;
for (auto &list : grid)
{
sum += list.size();
maxCount = max(maxCount, list.size());
//ImGui::Text(" size: %i", list.size());
}
ImGui::Text(" sum of all counts: %i", sum);
ImGui::Text(" average count per cell: %f", float(sum) / float(grid.size()));
ImGui::Text(" max count: %i", maxCount);
uint64_t time = SystemTools::GetTimeNS();
timeGridVC = time - timeGridVC;
}
int collCount = 0;
for (const auto &o0 : objects)
{
int x, y; PointToGridCoords (x, y, o0.pos);
auto &list = grid[x + y*gridDim];
for (const auto &o1 : list)
{
if (IntersectsG(o0, o1))
collCount++, RenderLine(o0.pos, o1.pos, 1,1,1);
}
}
ImGui::TextColored(ImVec4(0,0,1,1), "Found collisions: %i time: %s", collCount, SystemTools::GetDurationStringAndRestart(time).c_str());
timeGridVC = time - timeGridVC;
}
// grid of lists, adding each object to only one cell
static bool doGridList = 0; ImGui::Checkbox("doGridList", &doGridList);
uint64_t timeGridL = ULLONG_MAX;
if (doGridList)
{
static std::vector<Object*> grid;
if (init || !grid.size()) grid.resize(gridDim*gridDim);
std::fill(pairMask.begin(), pairMask.end(), false);
uint64_t time = SystemTools::GetTimeNS();
timeGridL = time;
std::fill (grid.begin(), grid.end(), nullptr);
for (auto &obj : objects)
{
int x, y; PointToGridCoords (x, y, obj.pos);
Object* &cell = grid[x + y*gridDim];
obj.next = cell;
cell = &obj;
}
ImGui::TextColored(ImVec4(1,0,1,1), "Build grid of lists time: %s", SystemTools::GetDurationStringAndRestart(time).c_str());
int collCount = 0;
for (const auto &o0 : objects)
{
int minX, minY; PointToGridCoords (minX, minY, o0.pos - vec2(o0.radius, o0.radius));
int maxX, maxY; PointToGridCoords (maxX, maxY, o0.pos + vec2(o0.radius, o0.radius));
for (int y=minY; y<=maxY; y++)
for (int x=minX; x<=maxX; x++)
{
Object *o1 = grid[x + y*gridDim];
while (o1)
{
if (IntersectsG(o0, *o1))
collCount++, RenderLine(o0.pos, o1->pos, 1,1,1);
o1 = o1->next;
}
}
}
ImGui::TextColored(ImVec4(1,0,1,1), "Found collisions: %i time: %s", collCount, SystemTools::GetDurationStringAndRestart(time).c_str());
timeGridL = time - timeGridL;
}
// BVH
static bool doBVH = 1; ImGui::Checkbox("doBVH", &doBVH);
uint64_t timeBVH = ULLONG_MAX;
if (doBVH)
{
std::fill(pairMask.begin(), pairMask.end(), false); // needed only for the tiling approach
// we use an axis aligned bounding box for our bounding volume
struct AABox
{
vec2 minmax[2];
void Init ()
{
minmax[0] = vec2 (FLT_MAX, FLT_MAX);
minmax[1] = vec2 (-FLT_MAX, -FLT_MAX);
}
void Extend (const AABox &b)
{
minmax[0][0] = min (minmax[0][0], b.minmax[0][0]);
minmax[0][1] = min (minmax[0][1], b.minmax[0][1]);
minmax[1][0] = max (minmax[1][0], b.minmax[1][0]);
minmax[1][1] = max (minmax[1][1], b.minmax[1][1]);
}
vec2 Center () const
{
return (minmax[0] + minmax[1]) * 0.5f;
}
bool BoundsPoint (const vec2 point) const
{
for (int i=0; i<2; i++)
{
if (point[i] < minmax[0][i] || point[i] > minmax[1][i])
return false;
}
return true;
}
bool IntersectsBox (const AABox &box) const
{
for (int i=0; i<2; i++)
{
if (box.minmax[1][i] < minmax[0][i] || box.minmax[0][i] > minmax[1][i])
return false; // disjoint
}
return true; // intersecting
}
static AABox& Empty()
{
static AABox empty = {vec2 (FLT_MAX, FLT_MAX), vec2 (-FLT_MAX, -FLT_MAX)};
return empty;
}
};
// BVH
struct BVHNode
{
AABox bound;
int firstChild; // if negative, it's an index to a triangle
int childCount;
};
// build BVH
uint64_t time = SystemTools::GetTimeNS();
timeBVH = time;
static int levels = 5; ImGui::SliderInt ("levels", &levels, 1, 10);
// create leaf per object, and make them all children of the root
std::vector<BVHNode> leafNodes (objects.size());
std::vector<BVHNode> tree (1);
constexpr int rootIndex = 0;
BVHNode &root = tree[rootIndex];
root.bound.Init();
for (int i=0; i<(int)objects.size(); i++)
{
Object &obj = objects[i];
BVHNode &leaf = leafNodes[i];
leaf.bound.minmax[0] = obj.pos - vec2(obj.radius, obj.radius);
leaf.bound.minmax[1] = obj.pos + vec2(obj.radius, obj.radius);
leaf.firstChild = -1 - i;
leaf.childCount = 0;
// extend root box
root.bound.Extend(leaf.bound);
}
root.firstChild = 0;
root.childCount = objects.size();
//RenderAABBox (root.bound.minmax[0], root.bound.minmax[1], 1,0,0);
// build internal hierarchy
std::vector<int> stack;
stack.push_back(rootIndex); // add root to process
int head = 0;
int tail = 1;
std::vector<BVHNode> reorderedLeafs (objects.size()); // temporary buffer storing leafs in sorted order
for (int level=0; level<levels; level++) // for each iteration adding one new level of hierarchy
{
int sortedIndex = 0; // we use this to reorder leafs to the newly sorted state after adding the level
for (int i=head; i<tail; i++) // process all nodes of the current level, now becoming parents to subdivide
{
int parentIndex = stack[i];
BVHNode &parent = tree[parentIndex];
vec2 parentCenter = parent.bound.Center();
// we make a simple BVH4, so subdividing children into quadrants from the center of the parent bound
int qCount[4] = {0,0,0,0}; // for each quadrant, count how many leafs are in
AABox qBox[4] = {AABox::Empty(), AABox::Empty(), AABox::Empty(), AABox::Empty()}; // for each quadrant make a new bound
int firstChild = parent.firstChild;
int childCount = parent.childCount;
for (int n=0; n<childCount; n++)
{
int leafIndex = firstChild + n;
BVHNode &leaf = leafNodes[leafIndex];
vec2 diff = leaf.bound.Center() - parentCenter;
int quadrant = (diff[0] > 0) | ((diff[1] > 0)<<1);
leaf.childCount = (qCount[quadrant]<<2) | quadrant; // we alias this variable to store the leafs new subindex + quadrant
qCount[quadrant]++;
qBox[quadrant].Extend(leaf.bound);
}
// create new children from quadrants
int firstQuadrantIndex[4];
int newFirstChild = -1;
int newChildCount = 0;
for (int q=0; q<4; q++) if (qCount[q])
{
int newChildIndex = (int)tree.size();
if (newFirstChild == -1)
newFirstChild = newChildIndex;
newChildCount++;
tree.push_back(BVHNode());
BVHNode &newChild = tree.back();
newChild.bound = qBox[q];
newChild.childCount = qCount[q];
newChild.firstChild = sortedIndex;
firstQuadrantIndex[q] = sortedIndex;
sortedIndex += qCount[q];
stack.push_back(newChildIndex); // refine further
}
tree[parentIndex].firstChild = newFirstChild;
tree[parentIndex].childCount = newChildCount;
// iterate children again, to calculate their final newly sorted index and reordering them accordingly
for (int n=0; n<childCount; n++)
{
int leafIndex = firstChild + n;
BVHNode &leaf = leafNodes[leafIndex];
int quadrant = (leaf.childCount & 3);
int subIndex = (leaf.childCount)>>2;
int newIndex = firstQuadrantIndex[quadrant] + subIndex;
assert(newIndex < (int)leafNodes.size());
//leaf.childCount = newIndex; // alias again to store the leafs newly sorted index
reorderedLeafs[newIndex] = leaf;
}
}
// reorder the leafs
/*for (int i=0; i<(int)leafNodes.size(); i++)
{
BVHNode &leaf = leafNodes[i];
int newIndex = leaf.childCount;
assert(newIndex < (int)reorderedLeafs.size());
reorderedLeafs[newIndex] = leaf;
}*/
std::swap(reorderedLeafs, leafNodes);
head = tail;
tail = (int)stack.size();
//ImGui::Text("build level %i completed. head %i tail %i", level, head, tail);
}
// add leafs to tree
int offset = (int)tree.size();
std::copy(leafNodes.begin(), leafNodes.end(), std::back_inserter(tree));
for (int i=head; i<tail; i++)
{
int parentIndex = stack[i];
BVHNode &parent = tree[parentIndex];
parent.firstChild += offset;
}
ImGui::TextColored(ImVec4(1,1,0,1), "Build BVH time: %s", SystemTools::GetDurationStringAndRestart(time).c_str());
// visually proof sorted order from color pattern
vec2 prevCenter;
if (0) for (int i=0; i<(int)leafNodes.size(); i++)
{
BVHNode &leaf = leafNodes[i];
float t = float(i) / float(leafNodes.size()) * 0.66f;
vec2 center = leaf.bound.Center();
RenderPoint(center, Vis::RainbowR(t), Vis::RainbowG(t), Vis::RainbowB(t));
if (i) RenderLine(center, prevCenter, Vis::RainbowR(t), Vis::RainbowG(t), Vis::RainbowB(t));
prevCenter = center;
}
#if 0 // collision detection - traversal per object
int collCount = 0;
for (const auto &o0 : objects)
{
AABox query;
query.minmax[0] = o0.pos - vec2(o0.radius, o0.radius);
query.minmax[1] = o0.pos + vec2(o0.radius, o0.radius);
stack.clear();
stack.push_back(rootIndex);
head = 0;
tail = 1;
for (int level=0; level<=levels; level++) // each iteration traverses one level of the hierarchy in breadth first order
{
for (int i=head; i<tail; i++) // traverse all nodes of the current level
{
int parentIndex = stack[i];
const BVHNode &parent = tree[parentIndex];
int firstChild = parent.firstChild;
int childCount = parent.childCount;
for (int n=0; n<childCount; n++)
{
int childIndex = firstChild + n;
const BVHNode &child = tree[childIndex];
if(!child.bound.IntersectsBox(query))
continue;
//float t = float(level) / float(levels) * 0.66f;
//RenderAABBox (child.bound.minmax[0], child.bound.minmax[1], Vis::RainbowR(t), Vis::RainbowG(t), Vis::RainbowB(t));
if (level<levels)
stack.push_back(childIndex);
else
{
int objectIndex = -child.firstChild -1;
const Object &o1 = objects[objectIndex];
if (&o0 < &o1 && Intersects(o0, o1))
collCount++, RenderLine(o0.pos, o1.pos, 1,1,1);
}
}
}
head = tail;
tail = (int)stack.size();
}
}
ImGui::TextColored(ImVec4(1,1,0,1), "Found collisions: %i time: %s", collCount, SystemTools::GetDurationStringAndRestart(time).c_str());
timeBVH = time - timeBVH;
#else // collision detection - traversal per brute force tile
std::vector<Object> objectRange;
static int tiles = 8; ImGui::SliderInt("tile res", &tiles, 4, 20);
int collCount = 0;
for (int y=0; y<tiles; y++)
for (int x=0; x<tiles; x++)
{
AABox query;
query.minmax[0] = vec2(float(x) / float(tiles), float(y) / float(tiles));
query.minmax[1] = vec2(float(x+1) / float(tiles), float(y+1) / float(tiles));
//RenderAABBox(query.minmax[0],query.minmax[1], 0,1,0);
objectRange.clear();
stack.clear();
stack.push_back(rootIndex);
head = 0;
tail = 1;
for (int level=0; level<=levels; level++) // each iteration traverses one level of the hierarchy in breadth first order
{
for (int i=head; i<tail; i++) // traverse all nodes of the current level
{
int parentIndex = stack[i];
const BVHNode &parent = tree[parentIndex];
int firstChild = parent.firstChild;
int childCount = parent.childCount;
for (int n=0; n<childCount; n++)
{
int childIndex = firstChild + n;
const BVHNode &child = tree[childIndex];
if(!child.bound.IntersectsBox(query))
continue;
//float t = float(level) / float(levels) * 0.66f;
//RenderAABBox (child.bound.minmax[0], child.bound.minmax[1], Vis::RainbowR(t), Vis::RainbowG(t), Vis::RainbowB(t));
if (level<levels)
stack.push_back(childIndex);
else
{
int objectIndex = -child.firstChild -1;
objectRange.push_back(objects[objectIndex]);
}
}
}
head = tail;
tail = (int)stack.size();
}
//ImGui::Text("o: %i", objectRange.size());
const int count = objectRange.size();
for (int i=0; i<count-1; i++)
for (int j=i+1; j<count; j++)
{
const auto &o0 = objectRange[i];
const auto &o1 = objectRange[j];
if (IntersectsG(o0, o1))
collCount++, RenderLine(o0.pos, o1.pos, 1,1,0); // appends vertices and color to a buffer
}
}
ImGui::TextColored(ImVec4(1,1,0,1), "Found collisions: %i time: %s", collCount, SystemTools::GetDurationStringAndRestart(time).c_str());
timeBVH = time - timeBVH;
#endif
}
// Sorting per dimension
static bool doSort = 0; ImGui::Checkbox("doSort", &doSort);
uint64_t timeSort = ULLONG_MAX;
if (doSort && objects.size()<5000) // Ivica Kolic, https://www.gamedev.net/forums/topic/713512-what-kind-of-coding-standard-do-you-prefer/5453647/?page=4
{
std::fill(pairMask.begin(), pairMask.end(), false);
std::vector<int> _sortedObjects[2]; // For each dimension we have object indices sorted by start position. This is our acceleration structure
// Tmp stuff to be persisted in a permanent memory context object just so we don't allocate these local vectors all the time
std::vector<float> objectKeys; // tmp vector (but reuse vector for every time) - I should ommit this and just use objects with lambda for specifying sorting key (which can be start position, end position or size).
std::vector<int> swapBuffer; // Nice to have persisted so that radix sort doesn't have to use its own memory allocations on each use
_sortedObjects[0].resize(objects.size());
_sortedObjects[1].resize(objects.size());
// Let's update accelleration structure:
objectKeys.reserve(objects.size());
swapBuffer.resize(objects.size()); // Usefull preallocated tmp memory
uint64_t time = SystemTools::GetTimeNS();
timeSort = time;
// For each dimension we will first sort by size (or maybe end position)
for (int dim = 0; dim < 2; ++dim)
{
// // Sort by size:
// objectKeys.clear();
// //for (auto& o : objects) objectKeys.push_back(o.GetMax()[dim] - o.getMin()[dim]); // This should be lambda but...
// for (auto& o : objects) objectKeys.push_back(o.radius * 2.f); // This should be lambda but...
// RadixSortIndexed<float, int>(_sortedObjects[dim].data(), objectKeys.data(), objects.size(), true, swapBuffer.data());
// Sort by start pos:
objectKeys.clear();
//for (auto& o : objects) objectKeys.push_back(o.GetMin()[dim]); // This should be lambda but...
for (auto& o : objects) objectKeys.push_back(o.pos[dim]/* - o.radius*/); // This should be lambda but...
RadixSortIndexed<float, int>(_sortedObjects[dim].data(), objectKeys.data(), objects.size(), true, swapBuffer.data());
}
ImGui::TextColored(ImVec4(0,1,1,1), "Sorting time: %s", SystemTools::GetDurationStringAndRestart(time).c_str());
//int D=1;
//for (int i=1; i<_sortedObjects[D].size(); i++)
//{
// int i0 = _sortedObjects[D][i-1];
// int i1 = _sortedObjects[D][i];
// RenderLine(objects[i0].pos, objects[i1].pos, 1,0,1);
//}
int collCount = 0;
for (int D=0; D<2; D++) // instead proposed binary search to find an onject in selscted dimension sort sequence, iterate per dimansion to spare the search
{
const auto &seq = _sortedObjects[D];
const int seqSize = seq.size();
for (int i=0; i<seqSize; i++)
{
int sortedI0 = seq[i];
const auto &o0 = objects[sortedI0];
// select dimension
int d = ((12829 * o0.index)>>3) & 1; // Should choose the shorter dimension of object bounding box, but since using spheres, we use a random dim.
// Density histogram might be better than object box, but does not make sense here either.
if (d!=D)
continue; // process only if choice matches
// search for potential collision range in sorted sequence
float rangeMin = o0.pos[D] - o0.radius - maxRadius;
int rangeI = i;
while (--rangeI >= 0)
{
int sortedI1 = seq[rangeI];
const auto &o1 = objects[sortedI1];
if (o1.pos[D] < rangeMin)
break;
if (IntersectsG(o0, o1))
collCount++, RenderLine(o0.pos, o1.pos, 0,1,1);
}
float rangeMax = o0.pos[D] + o0.radius + maxRadius;
rangeI = i;
while (++rangeI < seqSize)
{
int sortedI1 = seq[rangeI];
const auto &o1 = objects[sortedI1];
if (o1.pos[D] > rangeMax)
break;
if (IntersectsG(o0, o1))
collCount++, RenderLine(o0.pos, o1.pos, 0,1,1);
}
}
}
ImGui::TextColored(ImVec4(0,1,1,1), "Found collisions: %i time: %s", collCount, SystemTools::GetDurationStringAndRestart(time).c_str());
timeSort = time - timeSort;
}
// histogram of timings
{
constexpr int R = 200;
static std::vector< std::array<uint64_t,6> > histogram(R, std::array<uint64_t,6>({ULLONG_MAX,ULLONG_MAX,ULLONG_MAX,ULLONG_MAX,ULLONG_MAX,ULLONG_MAX}));
int i = min(R-1, objects.size() * (R-1) / 10000);
ImGui::Text("hbin: %i", i);
histogram[i][0] = min(histogram[i][0], timeBruteForce);
histogram[i][1] = min(histogram[i][1], timeGridV);
histogram[i][2] = min(histogram[i][2], timeGridVC);
histogram[i][3] = min(histogram[i][3], timeGridL);
histogram[i][4] = min(histogram[i][4], timeBVH);
histogram[i][5] = min(histogram[i][5], timeSort);
static float scale = 1.f; ImGui::DragFloat("histogram scale", &scale, 0.01f);
for (int j=1; j<R; j++)
{
float t0 = float(j-1) / (R-1);
float t1 = float(j) / (R-1);
for (int i=0; i<6; i++)
{
float k0 = float(histogram[j-1][i]) * 0.00000002f * scale;
float k1 = float(histogram[j][i]) * 0.00000002f * scale;
RenderLine (vec2(t0+1, k0), vec2(t1+1, k1), i==0||i==3||i==4, i==1||i==4||i==5, i==2||i==5||i==3);
}
}
}
//if (objectCount<10000) objectCount+=10;
init = 0;
}
JoeJ said: @ivica kolic Please take a look at the sorting code and propose improvement. I do not understand how to benefit from sorting by size additionally, or having both start and end point sorted. I did just a trivial search around the current object, and assume there's a some way?
Sorting by size makes no sense here. I've used when sorting triangles of a mesh where many triangles have the same start position (start vertex) and if I exclude the largest one (left search) I can skip all the triangles with the same starting position since I know that they are shorter. The problem with the Radix code that I've given you is that it resets indices at every sort (to 0, 1 , 2, 3, 4) so there is no pointing in double sorting.
In any case, I think you've proven that this isn't good data structure for physic engine. It is good enough for triangle meshes for finding all triangles within some bounding box (it handles long triangles better than octrees (except if you decimate triangles which takes too long).
JoeJ said: @juliean I did not mind to make a local references on other static variables. Usually i never use them, only in such small test snippets. Now i need to ask again: Does each access to static variables include a check if they are already initialized? Even every time in a loop, for example?
Well I did just test it in godbolt, and in my simple examples I couldn't reproduce a difference (in generated ASM). So eigther compiler got smarter about this, or you need a more complicated examples for this to make a difference.
JoeJ said: um, does this give the same performance as int all = 0b11111, and old school bit math?
Interesting question. I did do another quick comparison in godbolt, using std::bitset for the integer-math (this is ought to get optimized to the same as integer-math you suggested, but feel free to add this yourself in the link, I just don't feel doing that :P):
I have added a tiled approach for the BVH. Because grids are rarely an option in 3D, i want to show BVH can do nearly as good.
It's a very simple apporach: Instead doing a traversal for each object, i tile the space and do one traversal per tile. Copies of found objects are then processed with brute force efficiently. This could be improved in many ways, but actually i think a sparse grid would be generally better for the problem.
The actual timings on the right are for 10000 objects on a single core, so we can estimate what's about practical. Ofc. the scene is much too dense to make sense, as collision count is 16x higher than object count, but still.
But now i must stop this, and go back to real work… :D
JoeJ said: The actual timings on the right are for 10000 objects on a single core, so we can estimate what's about practical. Ofc. the scene is much too dense to make sense, as collision count is 16x higher than object count, but still. But now i must stop this, and go back to real work… :D Will update the code in the former post.
If you ever end up having time to revisit this again, I'd be interested in one last thing. If you removed the “list” linking inside the objects themself and place them in a separate structure (to simulate the example that I mentioned where you can't store such a link in the objects themselves), how much does that affect performance for the list-case? No hurry, just something I'm curious about.
----------------------------------------------
I have now finished my own implementation of the bucket-sorted collision masks, and well, its so-and-so.
I did end up changing a few things about it: I did cache the buckets, using my already existing entity-cache dirty notification mechanism. This still creates it a few times too often then really need be, because there are cases where the cache gets flagged dirty and those buckets wouldn't need to. But this is still something that could be improved in the future. In general, this seems to be faster than recreating the buckets each frame, even if I now have to calculate some data more times during the actual collision check. Also, this change was sorta necessary for the integration of this system for actual collision, as there are multiple points in a frame where the actual content of the buckets could need to change. I also ended up creating an array<vector> for seeing which buckets need to be checked after all - it seems to be at least as fast, but requires less if/nestings. Also somelike this would be required if I started to un-hardcode the settings and allow it to be configured via the editor, as for what can collide with what.
Debug-performance for running the tests did improve to something like 70x→75x for complicated recordings, which is definately a nice thing. cuts the time needed to run a 17 minute recording down by a few seconds, which is neat I guess (no, really, this does matter in practice as I run the editor mainly in debug, and run those tests often).
Now for release, after everything is done, I cannot really say that anything has improved. Differences in timings for executing the full release-recording between the old brute-force and the new version are all in a range with enough fluctuation between runs, that I cannot really say eigther one is faster. At least the new system is not noticable slower, but it doesn't seem to improve much for this case. Probably because bottlenecks are on other places. At a relative speed of 10 seconds per frame(!), there are lot of switches between scenes happening each frame, meaning I might be locked by those. Would need to profile to find out more.
Unfortunately I introduced a bug somewhere in the legacy-code, so I cannot easily test the case of “mask, but no buckets” anymore. But I'd guess its somewhere in the middle. Certain parts of the code already didn't really execute in O(N^2), due to most entities being flagged “inactive” and thus not running their own pass through the array at all.
One case that did noticably improve is the “how many player-characters can I have in a scene?"-benchmark I run every few months. That one is a bit more interesting (albeit for now purely hypothetical in nature for now). With the new system, I can have about 4096 “player” objects in the scene while running at 14ms (in release), without any additional modifications. Previously, I could have around the same, but I had to deactivate collision/triggers on all of them, otherwise I'd end up with 400ms. This is a little bit "cheated", because well, by the way the new system works, no player needs to collide with another (this is by design), and since no buckets have to be recreated, the runtime-overhead of collision/triggers are now, well, 0. Though it is also a nice application of this feature, and kind of reflects what this system (in practice) does for my game (even though speedups are not that apparent). In the game, most things only need to check collision with a few things. Player needs to trigger enemies (and vice versa), projectiles only need to trigger eigther player or enemy, depending on who shoots them, etc… So for my max-load object counts, with ~100 projectiles and one player, this means that I only need to do one check for each projectile. Additional clarifiction: The player-objects are complex, in fact the most complex object of the game. They have a dynamic ARPG-controller with lots of different actions/interactions which, in this implementation at least, require lots of additional checks/queries to be executed each frame, via custom scripts.
So, maybe a grid could bring this even further down, but since we already went from O(N^2) to a realistic O(N) with minimal updates to the buckets, with no real-world improvement… I don't think I'm going to go further. Grid would be more complicated, we would need to mark it dirty many more times when entities changes their properties or transform. I'm still kind of on the fence about if it was “worth” it. I guess I can now judge the performance of my engine with my player-object overload-test without having to turn off specific systems, which is nice. And in a few years down the line, those seconds I save on running tests might make up for the time I had to spend changing this ? And maybe I'll be doing a 2d-game with more objects in eve more years, who knows. At least I now got a (theoretically configurable) mask for excluding collisions for specific types, which is something that I was lacking. Though I still stand that in terms of if it was really worth to implement the buckets per se, no - even though they should yield a reduction of complexity for this specific case that is similar to what a grid would do in other scenarios. The gains are to marginal to really justify investing any time at all, if I have to be blunt. Because even if the individual collision-systems now were infinitely more effective, its still just a small part of a complex system. Sure, the cap of how many objects can be had (at least assuming they don't need to collide with each other) has now increased by a large margin, as been shown in my synthetical test. But even then, doubling the objects would still barely run the required fromrate due to other overhead in scripts, etc… So its not like the gigant difference of x32 in execution speed that I got from going bytecode, or the x2-5 additional speed I got from my JIT- though those also took way more than just two half-days of work to complete ?