Juliean said:
If you ever end up having time to revisit this again, I'd be interested in one last thing. If you removed the “list” linking inside the objects themself and place them in a separate structure (to simulate the example that I mentioned where you can't store such a link in the objects themselves), how much does that affect performance for the list-case? No hurry, just something I'm curious about.
Pretty sure no difference would show. I try such things here and there, but mostly it does not matter. Probably because CPUs have multiple ‘cache streams’, or how's that called. The objects and the links would have the same access pattern, so ther should be little effect. But yeah, would be interesting to try.
More interesting it would be to reorder the objects. After the lists are build, we would iterate grid cells, traverse the list of the cell and copy the particle in this order to a new, nicely sorted vector. So we have just one random access per object.
The list is no longer needed, just a begin and end index of objects per cell.
For the collision detection, we now iterate over sequential memory per cell, so this should make it noticeable faster.
But i doubt it's a win here. The bandwidth cost of reordering is worst case. So this adds a system wide bottleneck, if you do some multi threading.
And even worse: Such optimization is only worth it if we have many objects per cell, so the sorted sequences have some length to show a net benefit.
For particle fluid simulations (or my dense example with high object count) that's worth it, but for game objects likely not. On average you will have less than one object per cell, making such ideas pointless.
In my experience there is always very little benefit from optimizing for memory access patterns, if we compare against optimizing to reduce work.
I also ended up creating an array<vector>
This would be actually interesting to compare with the alternative, after i saw nested vectors don't do that bad.
The alternative, which i call binning, is to loop over the objects two times. First, we sum up the count which goes into each bin. We also store the current count for each object.
Then we do a prefix sum over the bin counts, which gives us begin and end for each bins list in one compacted array which has the same size as the objects.
Second, we iterate over objects again, adding their local count to the bucket begin and place the objects at this index.
The BVH build is an actual example of this. It does just that to reorder objects from parent bins to new child bins as we add a tree level, similar to how some in place sorting algorithm works.
The advantage is it works with constant memory and avoids any allocations, and the time complexity is still O(1) per object, plus O(N) where N is the bin count. It's also parallelizable easily, and works well on GPU, where the bin cost reduces to O(log n).
This binning became a nice building block for me, which i use really often. Way more often than sorting. It's faster and often good enough for the same purpose.
And it did beat nested vectors in any case, whenever i've tried to compare. But that was some years ago, on my old computer, with older compilers and libraries. So no longer sure. Likely it ‘depends’.
Juliean said:
Debug-performance for running the tests did improve to something like 70x→75x
You know… somebody needs to tell you this, ahem…
‘Using debug mode for profiling is pointless, even more so if you use stl.’
But i guess you knew that already : )
If i could run my editor in debug, that would be very nice, really.
But actually it takes minutes just o load a fricking mesh. Even filling a std::vector<bool> with zeroes takes 2 minutes, the fuck! And no, i won't do my own bool vector. Too lazy.
So when the hell do they finally intend to fix this? How many billions per year are lost world wisde, just because Microsofts STL sucks in debug mode (at least)?
And while i'm at it, that's not the worst thing. I mean, idon't absolutely need a debugger. I can guess, and log…
No. The worst thing is this:
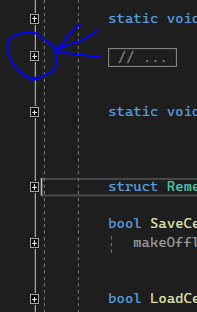
This is how a proper h file has to look like. (If it's 30k lines of code, um)
I have to collapse all those little bastards, except one, or two.
So i go through all those 30k lines, and click to make each - a nice, collapsed +
Then i type a letter. You know, coding.
But then: Damn shitty VS uncollapses all those + again! At least dozens of them. I do not even see the place where my cursor is. I see some random, unrelated other function i don't want to see.
So i go through all those 30k lines again, and click to make each - a nice, collapsed +
Then i type a letter. You know, coding. But more angry this time.
But then - again the same, infinite loop of clicking all those little - bastards……
I do this all day long. Every day. Since many, many years.
This, and only this is the biggest problem with programming. Coding style doesn't matter. Bjarnes new book doesn't help. And they will never ever fix this bug, nor will they provide a useful way to auto collapse h files.
ahh, sigh, i feel better now. I never told this anybody before. Maybe there is some plug in? If anybody knows - help me! \>:o/