
edit:
Seeing this has been linked outside of game-development circles: "ECS" (this wikipedia page is garbage, btw -- it conflates EC-frameworks and ECS-frameworks, which aren't the same...) is a faux-pattern circulated within game-dev communities, which is basically a version of the relational model, where "entities" are just ID's that represent a formless object, "components" are rows in specific tables that reference an ID, and "systems" are procedural code that can modify the components. This "pattern" is always posed as a solution to an over-use of inheritance, without mentioning that an over-use of inheritance is actually bad under OOP guidelines. Hence the rant. This isn't the "one true way" to write software. It's getting people to actually look at existing design guidelines.
Inspiration
This blog post is inspired by Aras Pranckevičius' recent publication of a talk aimed at junior programmers, designed to get them to come to terms with new "ECS" architectures. Aras follows the typical pattern (explained below), where he shows some terrible OOP code and then shows that the relational model is a great alternative solution (but calls it "ECS" instead of relational). This is not a swipe at Aras at all - I'm a fan of his work and commend him on the great presentation! The reason I'm picking on his presentation in particular instead of the hundred other ECS posts that have been made on the interwebs, is because he's gone through the effort of actually publishing a git repository to go along with his presentation, which contains a simple little "game" as a playground for demonstrating different architecture choices. This tiny project makes it easy for me to actually, concretely demonstrate my points, so, thanks Aras!
You can find Aras' slides at http://aras-p.info/texts/files/2018Academy - ECS-DoD.pdf and the code at https://github.com/aras-p/dod-playground.
I'm not going to analyse the final ECS architecture from that talk (yet?), but I'm going to focus on the straw-man "bad OOP" code from the start. I'll show what it would look like if we actually fix all of the OOD rule violations.
Spoiler: fixing the OOD violations actually results in a similar performance improvement to Aras' ECS conversion, plus it actually uses less RAM and requires less lines of code than the ECS version!
TL;DR: Before you decide that OOP is shit and ECS is great, stop and learn OOD (to know how to use OOP properly) and learn relational (to know how to use ECS properly too).
I've been a long-time ranter in many "ECS" threads on the forum, partly because I don't think it deserves to exist as a term (spoiler: it's just a an ad-hoc version of the relational model), but because almost every single blog, presentation, or article that promotes the "ECS" pattern follows the same structure:
- Show some terrible OOP code, which has a terribly flawed design based on an over-use of inheritance (and incidentally, a design that breaks many OOD rules).
- Show that composition is a better solution than inheritance (and don't mention that OOD actually teaches this same lesson).
- Show that the relational model is a great fit for games (but call it "ECS").
This structure grinds my gears because:
(A) it's a straw-man argument.. it's apples to oranges (bad code vs good code)... which just feels dishonest, even if it's unintentional and not actually required to show that your new architecture is good,
but more importantly:
(B) it has the side effect of suppressing knowledge and unintentionally discouraging readers from interacting with half a century of existing research. The relational model was first written about in the 1960's. Through the 70's and 80's this model was refined extensively. There's common beginners questions like "which class should I put this data in?", which is often answered in vague terms like "you just need to gain experience and you'll know by feel"... but in the 70's this question was extensively pondered and solved in the general case in formal terms; it's called database normalization. By ignoring existing research and presenting ECS as a completely new and novel solution, you're hiding this knowledge from new programmers.
Object oriented programming dates back just as far, if not further (work in the 1950's began to explore the style)! However, it was in the 1990's that OO became a fad - hyped, viral and very quickly, the dominant programming paradigm. A slew of new OO languages exploded in popularity including Java and (the standardized version of) C++. However, because it was a hype-train, everyone needed to know this new buzzword to put on their resume, yet no one really groked it. These new languages had added a lot of OO features as keywords -- class, virtual, extends, implements -- and I would argue that it's at this point that OO split into two distinct entities with a life of their own.
I will refer to the use of these OO-inspired language features as "OOP", and the use of OO-inspired design/architecture techniques as "OOD". Everyone picked up OOP very quickly. Schools taught OO classes that were efficient at churning out new OOP programmers.... yet knowledge of OOD lagged behind.
I argue that code that uses OOP language features, but does not follow OOD design rules is not OO code. Most anti-OOP rants are eviscerating code that is not actually OO code.
OOP code has a very bad reputation, I assert in part due to the fact that, most OOP code does not follow OOD rules, thus isn't actually "true" OO code.
Background
As mentioned above, the 1990's was the peak of the "OO fad", and it's during this time that "bad OOP" was probably at its worst. If you studied OOP during this time, you probably learned "The 4 pillars of OOP":
- Abstraction
- Encapsulation
- Polymorphism
- Inheritance
I'd prefer to call these "4 tools of OOP" rather than 4 pillars. These are tools that you can use to solve problems. Simply learning how a tool works is not enough though, you need to know when you should be using them... It's irresponsible for educators to teach people a new tool without also teaching them when it's appropriate to use each of them. In the early 2000's, there was a push-back against the rampant misuse of these tools, a kind of second-wave of OOD thought. Out of this came the SOLID mnemonic to use as a quick way to evaluate a design's strength. Note that most of these bits of advice were well actually widely circulated in the 90's, but didn't yet have the cool acronym to cement them as the five core rules...
- Single responsibility principle. Every class should have one reason to change. If class "A" has two responsibilities, create a new class "B" and "C" to handle each of them in isolation, and then compose "A" out of "B" and "C".
- Open/closed principle. Software changes over time (i.e. maintenance is important). Try to put the parts that are likely to change into implementations (i.e. concrete classes) and build interfaces around the parts that are unlikely to change (e.g. abstract base classes).
- Liskov substitution principle. Every implementation of an interface needs to 100% comply the requirements of that interface. i.e. any algorithm that works on the interface, should continue to work for every implementation.
- Interface segregation principle. Keep interfaces as small as possible, in order to ensure that each part of the code "knows about" the least amount of the code-base as possible. i.e. avoid unnecessary dependencies. This is also just good advice in C++ where compile times suck if you don't follow this advice
- Dependency inversion principle. Instead of having two concrete implementations communicate directly (and depend on each other), they can usually be decoupled by formalizing their communication interface as a third class that acts as an interface between them. This could be an abstract base class that defines the method calls used between them, or even just a POD struct that defines the data passed between them.
- Not included in the SOLID acronym, but I would argue is just as important is the:
Composite reuse principle. Composition is the right default™. Inheritance should be reserved for use when it's absolutely required.
This gives us SOLID-C(++) ?
From now on, I'll refer to these by their three letter acronyms -- SRP, OCP, LSP, ISP, DIP, CRP...
A few other notes:
- In OOD, interfaces and implementations are ideas that don't map to any specific OOP keywords. In C++, we often create interfaces with abstract base classes and virtual functions, and then implementations inherit from those base classes... but that is just one specific way to achieve the idea of an interface. In C++, we can also use PIMPL, opaque pointers, duck typing, typedefs, etc... You can create an OOD design and then implement it in C, where there aren't any OOP language keywords! So when I'm talking about interfaces here, I'm not necessarily talking about virtual functions -- I'm talking about the idea of implementation hiding. Interfaces can be polymorphic, but most often they are not! A good use for polymorphism is rare, but interfaces are fundamental to all software.
- As hinted above, if you create a POD structure that simply stores some data to be passed from one class to another, then that struct is acting as an interface - it is a formal data definition.
- Even if you just make a single class in isolation with a public and a private section, everything in the public section is the interface and everything in the private section is the implementation.
- Inheritance actually has (at least) two types -- interface inheritance, and implementation inheritance.
- In C++, interface inheritance includes abstract-base-classes with pure-virtual functions, PIMPL, conditional typedefs. In Java, interface inheritance is expressed with the implements keyword.
- In C++, implementation inheritance occurs any time a base classes contains anything besides pure-virtual functions. In Java, implementation inheritance is expressed with the extends keyword.
- OOD has a lot to say about interface-inheritance, but implementation-inheritance should usually be treated as a bit of a code smell!
And lastly I should probably give a few examples of terrible OOP education and how it results in bad code in the wild (and OOP's bad reputation).
- When you were learning about hierarchies / inheritance, you probably had a task something like:
Let's say you have a university app that contains a directory of Students and Staff. We can make a Person base class, and then a Student class and a Staff class that inherit from Person!
Nope, nope nope. Let me stop you there. The unspoken sub-text beneath the LSP is that class-hierarchies and the algorithms that operate on them are symbiotic. They're two halves of a whole program. OOP is an extension of procedural programming, and it's still mainly about those procedures. If we don't know what kinds of algorithms are going to be operating on Students and Staff (and which algorithms would be simplified by polymorphism) then it's downright irresponsible to dive in and start designing class hierarchies. You have to know the algorithms and the data first. - When you were learning about hierarchies / inheritance, you probably had a task something like:
Let's say you have a shape class. We could also have squares and rectangles as sub-classes. Should we have square is-a rectangle, or rectangle is-a square?
This is actually a good one to demonstrate the difference between implementation-inheritance and interface-inheritance.- If you're using the implementation-inheritance mindset, then the LSP isn't on your mind at all and you're only thinking practically about trying to reuse code using inheritance as a tool.
From this perspective, the following makes perfect sense:
struct Square { int width; }; struct Rectangle : Square { int height; };
A square just has width, while rectangle has a width + height, so extending the square with a height member gives us a rectangle!- As you might have guessed, OOD says that doing this is (probably) wrong. I say probably because you can argue over the implied specifications of the interface here... but whatever.
A square always has the same height as its width, so from the square's interface, it's completely valid to assume that its area is "width * width".
By inheriting from square, the rectangle class (according to the LSP) must obey the rules of square's interface. Any algorithm that works correctly with a square, must also work correctly with a rectangle. - Take the following algorithm: std::vector<Square*> shapes; int area = 0; for(auto s : shapes) area += s->width * s->width;
This will work correctly for squares (producing the sum of their areas), but will not work for rectangles.
Therefore, Rectangle violates the LSP rule.
- As you might have guessed, OOD says that doing this is (probably) wrong. I say probably because you can argue over the implied specifications of the interface here... but whatever.
- If you're using the interface-inheritance mindset, then neither Square or Rectangle will inherit from each other. The interface for a square and rectangle are actually different, and one is not a super-set of the other.
- So OOD actually discourages the use of implementation-inheritance. As mentioned before, if you want to re-use code, OOD says that composition is the right way to go!
- For what it's worth though, the correct version of the above (bad) implementation-inheritance hierarchy code in C++ is:
struct Shape { virtual int area() const = 0; };
struct Square : public virtual Shape { virtual int area() const { return width * width; }; int width; };
struct Rectangle : private Square, public virtual Shape { virtual int area() const { return width * height; }; int height; };- "public virtual" means "implements" in Java. For use when implementing an interface.
- "private" allows you to extend a base class without also inheriting its interface -- in this case, Rectangle is-not-a Square, even though it's inherited from it.
- I don't recommend writing this kind of code, but if you do like to use implementation-inheritance, this is the way that you're supposed to be doing it!
- For what it's worth though, the correct version of the above (bad) implementation-inheritance hierarchy code in C++ is:
- If you're using the implementation-inheritance mindset, then the LSP isn't on your mind at all and you're only thinking practically about trying to reuse code using inheritance as a tool.
TL;DR - your OOP class told you what inheritance was. Your missing OOD class should have told you not to use it 99% of the time!
Entity / Component frameworks
With all that background out of the way, let's jump into Aras' starting point -- the so called "typical OOP" starting point.
Actually, one last gripe -- Aras calls this code "traditional OOP", which I object to. This code may be typical of OOP in the wild, but as above, it breaks all sorts of core OO rules, so it should not all all be considered traditional.
I'm going to start from the earliest commit before he starts fixing the design towards "ECS": "Make it work on Windows again" 3529f232510c95f53112bbfff87df6bbc6aa1fae
// -------------------------------------------------------------------------------------------------
// super simple "component system"
class GameObject;
class Component;
typedef std::vector<Component*> ComponentVector;
typedef std::vector<GameObject*> GameObjectVector;
// Component base class. Knows about the parent game object, and has some virtual methods.
class Component
{
public:
Component() : m_GameObject(nullptr) {}
virtual ~Component() {}
virtual void Start() {}
virtual void Update(double time, float deltaTime) {}
const GameObject& GetGameObject() const { return *m_GameObject; }
GameObject& GetGameObject() { return *m_GameObject; }
void SetGameObject(GameObject& go) { m_GameObject = &go; }
bool HasGameObject() const { return m_GameObject != nullptr; }
private:
GameObject* m_GameObject;
};
// Game object class. Has an array of components.
class GameObject
{
public:
GameObject(const std::string&& name) : m_Name(name) { }
~GameObject()
{
// game object owns the components; destroy them when deleting the game object
for (auto c : m_Components)
delete c;
}
// get a component of type T, or null if it does not exist on this game object template<typename T> T* GetComponent()
{
for (auto i : m_Components)
{
T* c = dynamic_cast<T*>(i);
if (c != nullptr)
return c;
}
return nullptr;
}
// add a new component to this game object
void AddComponent(Component* c)
{
assert(!c->HasGameObject());
c->SetGameObject(*this);
m_Components.emplace_back(c);
}
void Start()
{
for (auto c : m_Components)
c->Start();
}
void Update(double time, float deltaTime)
{
for (auto c : m_Components)
c->Update(time, deltaTime);
}
private:
std::string m_Name;
ComponentVector m_Components;
};
// The "scene": array of game objects.
static GameObjectVector s_Objects;
// Finds all components of given type in the whole scene
template<typename T> static ComponentVector FindAllComponentsOfType()
{
ComponentVector res;
for (auto go : s_Objects)
{
T* c = go->GetComponent<T>();
if (c != nullptr)
res.emplace_back(c);
}
return res;
}
// Find one component of given type in the scene (returns first found one)
template<typename T> static T* FindOfType()
{
for (auto go : s_Objects)
{
T* c = go->GetComponent<T>();
if (c != nullptr)
return c;
}
return nullptr;
}Ok, 100 lines of code is a lot to dump at once, so let's work through what this is... Another bit of background is required -- it was popular for games in the 90's to use inheritance to solve all their code re-use problems. You'd have an Entity, extended by Character, extended by Player and Monster, etc... This is implementation-inheritance, as described earlier (a code smell), and it seems like a good idea to begin with, but eventually results in a very inflexible code-base. Hence that OOD has the "composition over inheritance" rule, above. So, in the 2000's the "composition over inheritance" rule became popular, and gamedevs started writing this kind of code instead.
What does this code do? Well, nothing good :D
To put it in simple terms, this code is re-implementing the existing language feature of composition as a runtime library instead of a language feature. You can think of it as if this code is actually constructing a new meta-language on top of C++, and a VM to run that meta-language on. In Aras' demo game, this code is not required (we'll soon delete all of it!) and only serves to reduce the game's performance by about 10x.
What does it actually do though? This is an "Entity/Component" framework (sometimes confusingly called an "Entity/Component system") -- but completely different to an "Entity Component System" framework (which are never called "Entity Component System systems" for obvious reasons). It formalizes several "EC" rules:
- the game will be built out of featureless "Entities" (called GameObjects in this example), which themselves are composed out of "Components".
- GameObjects fulfill the service locator pattern - they can be queried for a child component by type.
- Components know which GameObject they belong to - they can locate sibling componets by querying their parent GameObject.
- Composition may only be one level deep (Components may not own child components, GameObjects may not own child GameObjects).
- A GameObject may only have one component of each type (some frameworks enforced this, others did not).
- Every component (probably) changes over time in some unspecified way - so the interface includes "virtual void Update".
- GameObjects belong to a scene, which can perform queries over all GameObjects (and thus also over all Components).
This kind of framework was very popular in the 2000's, and though restrictive, proved flexible enough to power countless numbers of games from that time and still today.
However, it's not required. Your programming language already contains support for composition as a language feature - you don't need a bloated framework to access it... Why do these frameworks exist then? Well to be fair, they enable dynamic, runtime composition. Instead of GameObject types being hard-coded, they can be loaded from data files. This is great to allow game/level designers to create their own kinds of objects... However, in most game projects, you have a very small number of designers on a project and a literal army of programmers, so I would argue it's not a key feature. Worse than that though, it's not even the only way that you could implement runtime composition! For example, Unity is based on C# as a "scripting language", and many other games use alternatives such as Lua -- your designer-friendly tool can generate C#/Lua code to define new game-objects, without the need for this kind of bloated framework! We'll re-add this "feature" in a later follow-up post, in a way that doesn't cost us a 10x performance overhead...
Let's evaluate this code according to OOD:
- GameObject::GetComponent uses dynamic_cast. Most people will tell you that dynamic_cast is a code smell - a strong hint that something is wrong. I would say that it indicates that you have an LSP violation on your hands -- you have some algorithm that's operating on the base interface, but it demands to know about different implementation details. That's the specific reason that it smells.
- GameObject is kind of ok if you imagine that it's fulfilling the service locator pattern.... but going beyond OOD critique for a moment, this pattern creates implicit links between parts of the project, and I feel (without a wikipedia link to back me up with comp-sci knowledge) that implicit communication channels are an anti-pattern and explicit communication channels should be preferred. This same argument applies to bloated "event frameworks" that sometimes appear in games...
- I would argue that Component is a SRP violation because its interface (virtual void Update(time)) is too broad. The use of "virtual void Update" is pervasive within game development, but I'd also say that it is an anti-pattern. Good software should allow you to easily reason about the flow of control, and the flow of data. Putting every single bit of gameplay code behind a "virtual void Update" call completely and utterly obfuscates both the flow of control and the flow of data. IMHO, invisible side effects, a.k.a. action at a distance, is the most common source of bugs, and "virtual void Update" ensures that almost everything is an invisible side-effect.
- Even though the goal of the Component class is to enable composition, it's doing so via inheritance, which is a CRP violation.
- The one good part is that the example game code is bending over backwards to fulfill the SRP and ISP rules -- it's split into a large number of simple components with very small responsibilities, which is great for code re-use.
However, it's not great as DIP -- many of the components do have direct knowledge of each other.
So, all of the code that I've posted above, can actually just be deleted. That whole framework. Delete GameObject (aka Entity in other frameworks), delete Component, delete FindOfType. It's all part of a useless VM that's breaking OOD rules and making our game terribly slow.
Frameworkless composition (AKA using the features of the #*@!ing programming language)
If we delete our composition framework, and don't have a Component base class, how will our GameObjects manage to use composition and be built out of Components. As hinted in the heading, instead of writing that bloated VM and then writing our GameObjects on top of it in our weird meta-language, let's just write them in C++ because we're #*@!ing game programmers and that's literally our job.
Here's the commit where the Entity/Component framework is deleted: https://github.com/hodgman/dod-playground/commit/f42290d0217d700dea2ed002f2f3b1dc45e8c27c
Here's the original version of the source code: https://github.com/hodgman/dod-playground/blob/3529f232510c95f53112bbfff87df6bbc6aa1fae/source/game.cpp
Here's the modified version of the source code: https://github.com/hodgman/dod-playground/blob/f42290d0217d700dea2ed002f2f3b1dc45e8c27c/source/game.cpp
The gist of the changes is:
- Removing ": public Component" from each component type.
- I add a constructor to each component type.
- OOD is about encapsulating the state of a class, but since these classes are so small/simple, there's not much to hide -- the interface is a data description. However, one of the main reasons that encapsulation is a core pillar is that it allows us to ensure that class invariants are always true... or in the event that an invariant is violated, you hopefully only need to inspect the encapsulated implementation code in order to find your bug. In this example code, it's worth us adding the constructors to enforce a simple invariant -- all values must be initialized.
- I rename the overly generic "Update" methods to reflect what they actually do -- UpdatePosition for MoveComponent and ResolveCollisions for AvoidComponent.
- I remove the three hard-coded blocks of code that resemble a template/prefab -- code that creates a GameObject containing specific Component types, and replace it with three C++ classes.
- Fix the "virtual void Update" anti-pattern.
- Instead of components finding each other via the service locator pattern, the game objects explicitly link them together during construction.
The objects
So, instead of this "VM" code:
// create regular objects that move
for (auto i = 0; i < kObjectCount; ++i)
{
GameObject* go = new GameObject("object");
// position it within world bounds
PositionComponent* pos = new PositionComponent();
pos->x = RandomFloat(bounds->xMin, bounds->xMax);
pos->y = RandomFloat(bounds->yMin, bounds->yMax);
go->AddComponent(pos);
// setup a sprite for it (random sprite index from first 5), and initial white color SpriteComponent* sprite = new SpriteComponent();
sprite->colorR = 1.0f;
sprite->colorG = 1.0f;
sprite->colorB = 1.0f;
sprite->spriteIndex = rand() % 5;
sprite->scale = 1.0f;
go->AddComponent(sprite);
// make it move
MoveComponent* move = new MoveComponent(0.5f, 0.7f);
go->AddComponent(move);
// make it avoid the bubble things
AvoidComponent* avoid = new AvoidComponent();
go->AddComponent(avoid);
s_Objects.emplace_back(go);
}We now have this normal C++ code:
struct RegularObject
{
PositionComponent pos;
SpriteComponent sprite;
MoveComponent move;
AvoidComponent avoid;
RegularObject(const WorldBoundsComponent& bounds) : move(0.5f, 0.7f) // position it within world bounds
, pos(RandomFloat(bounds.xMin, bounds.xMax),
RandomFloat(bounds.yMin, bounds.yMax)) // setup a sprite for it (random sprite index from first 5), and initial white color
, sprite(1.0f, 1.0f, 1.0f, rand() % 5, 1.0f) { }
}; ...
// create regular objects that move
regularObject.reserve(kObjectCount);
for (auto i = 0; i < kObjectCount; ++i)
regularObject.emplace_back(bounds);The algorithms
Now the other big change is in the algorithms. Remember at the start when I said that interfaces and algorithms were symbiotic, and both should impact the design of the other? Well, the "virtual void Update" anti-pattern is also an enemy here. The original code has a main loop algorithm that consists of just:
// go through all objects
for (auto go : s_Objects)
{
// Update all their components
go->Update(time, deltaTime);You might argue that this is nice and simple, but IMHO it's so, so bad. It's completely obfuscating both the flow of control and the flow of data within the game. If we want to be able to understand our software, if we want to be able to maintain it, if we want to be able to bring on new staff, if we want to be able to optimise it, or if we want to be able to make it run efficiently on multiple CPU cores, we need to be able to understand both the flow of control and the flow of data. So "virtual void Update" can die in a fire.
Instead, we end up with a more explicit main loop that makes the flow of control much more easy to reason about (the flow of data is still obfuscated here, we'll get around to fixing that in later commits)
// Update all positions
for (auto& go : s_game->regularObject)
{
UpdatePosition(deltaTime, go, s_game->bounds.wb);
}
for (auto& go : s_game->avoidThis)
{
UpdatePosition(deltaTime, go, s_game->bounds.wb);
}
// Resolve all collisions
for (auto& go : s_game->regularObject)
{
ResolveCollisions(deltaTime, go, s_game->avoidThis);
}The downside of this style is that for every single new object type that we add to the game, we have to add a few lines to our main loop. I'll address / solve this in a future blog in this series.
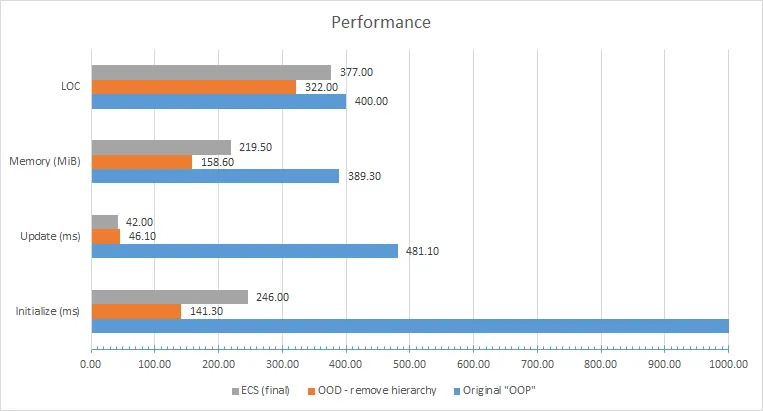
Performance
There's still a lot of outstanding OOD violations, some bad design choices, and lots of optimization opportunities remaining, but I'll get to them with the next blog in this series. As it stands at this point though, the "fixed OOD" version either almost matches or beats the final "ECS" code from the end of the presentation... And all we did was take the bad faux-OOP code and make it actually obey the rules of OOP (and delete 100 lines of code)!
Next steps
There's much more ground that I'd like to cover here, including solving the remaining OOD issues, immutable objects (functional style programming) and the benefits it can bring to reasoning about data flows, message passing, applying some DOD reasoning to our OOD code, applying some relational wisdom to our OOD code, deleting those "entity" classes that we ended up with and having purely components-only, different styles of linking components together (pointers vs handles), real world component containers, catching up to the ECS version with more optimization, and then further optimization that wasn't also present in Aras' talk (such as threading / SIMD). No promises on the order that I'll get to these, or if, or when... :D
















Maybe you're going to address this in the next part you mentioned, but languages could really use more neat tools to avoid all the boilerplate you have to write and read.
With methods like update and generic things like 'GameObject' you're tempted because you never have to touch that code again, and the codebase 'magically' accounts for everything when you add a new component type. And the 'main loop' that just calls the updates is never a real source of errors, as opposed to the specific style where you can (and this happens to me a ton) actually just forget to add the actual function call which may cost you a precious sanity on a bad day.
I guess a good metaprogramming language and a way to 'tag' functions/methods and variables/attributes (templates certainly aren't this) so you can look them up in the metaprogramming language later is all you'd need there, but C++ doesn't have it...
As you pointed out, the thing about 'static so a programmer has to change it' vs 'dynamic so designers can change it with a tool' is not really a thing considering the tool can theoretically spit out generated code in whatever language you need, but again the ecosystem bites you because actually doing that is a lot more complicated (if you want to be able to change stuff while the game/engine is running) than writing something data driven and loading/reloading a bunch of text files instead.