I don't know how many times I need to say it, but where alpha = beta = 1 you get zero precession.
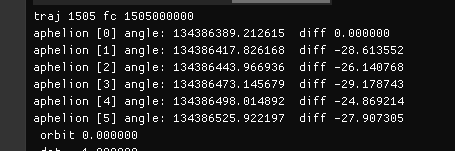
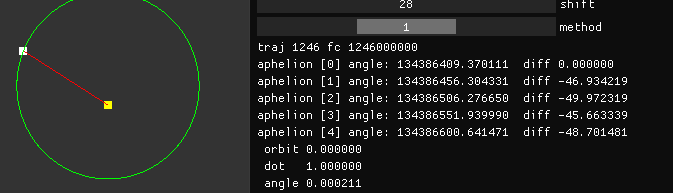
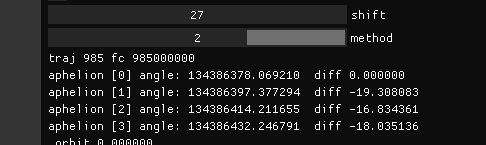
As for the character of the function that calculates angle from bits, it is not monotonically decreasing like you are saying. 20 bits gives an angle of 5.7, 24 bits gives an angle of 43.5, and 30 bits gives an angle of 14.8. That's not monotonic. Sorry man, but you're not right all of the time.
I'm interested in knowing how to generally calculate the next toward value from 0 to 1. For instance, nexttowardf(0, 1) returns a float 1.4013e-45. For double, using nexttoward(0, 1), the result is a double 4.94066e-324.
These values are much smaller than the epsilon, which is pow(2, -23) = 1.19209e-07 for float, etc.
Not sure what to make of them. Sorry. I don't know everything lol.
taby said: it is not monotonically decreasing like you are saying.
I don't say anything like this. When i did your angle measurement each timestep, it gave nan half of the time, thus the speculation about measurements being the explanation. Using complex numbers avoids a need to clamp a dot product just like atan2, so no nans. But i got the same numbers as before, so it isn't an explanation and measurement is not the problem. (I still recommend to clamp the dot product for acos, so no nans can happen in any case.)
taby said: I'm interested in knowing how to generally calculate the next toward value from 0 to 1.
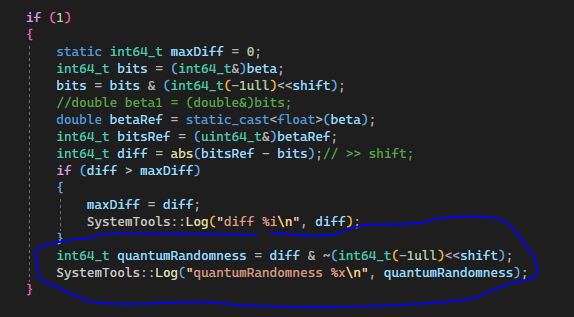
If you can be sure no overflow happens requiring to change exponent, the technical answer is simple:
uint64_t bits = (uint64_t&)value;
bits++;
value = (double&) bits;
This increases mantissa by one, and you can't do a change smaller than that.
I'm no floating point expert, but i've learned those things from GPU work, when figuring out we can use integer atomic min/max operations on floating point data. It works because exponent is in the higher bits, thus interpreting bits as integers works to compare for larger / smaller. (Negative numbers require some bit hacking before and after the atomic ops.)
I'm really baffled about the failure of replicating the casting behavior with bit hacking. The doubt on the scientific workflow here is one thing, but the failure on this low technical level is another. It should work, but it does not. I have no more idea about the reason.