You didn't mention a language you're working in, this however may make a difference. In C# for example we have the .NET implementation already done in System.Threading.Tasks and many APIs like file I/O already provide an ‘async’ version which will return a task you could wait on completion. The internals are a bit complicated and better explained on some blog posts but the key principle is that .NET maintains a single thread pool internally which task worker threads are running on. Tasks are nothing than promise objects which maintain a state and a reference to an asynchronous ‘thing’. (Yes, thing is the right term here because it can be anything from a callback over a function to an HTTP request which may proceed async)
C# also provides the async/ await keywords. This is black compiler magic; the C# compiler creates a state mashine for those functions, splitting up every await keyword into separate states. This is where the true asynchronous magic happens behind the scenes. The state mashine is processed on a worker thread until an await is hit. It returns the awaitable object instance, usually a Task but it may also be extended to something else (since it is compiler and not a language feature). Then if the dependency awaitable is cleared, it's state is set to something completed, the awaitable is removed from the worker and the dependant task is resumed. This may happen on the same but also another thread.
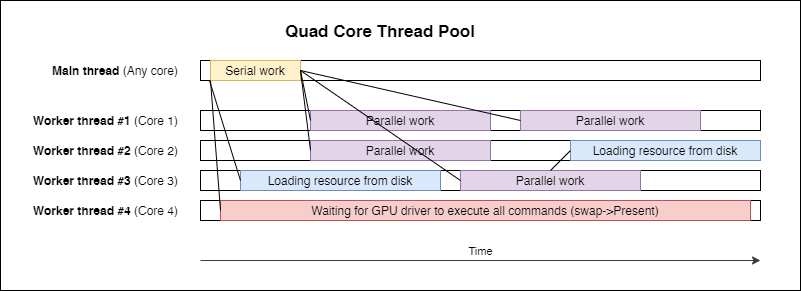
C++ on the other hand can provide the same features (and I don't mean the standard async/ await keywords, which do the same in the background). I have worked on the same topic as you for a long time reading through different articles and blogs. My first implementation, was as yours, a trhead pool of worker threads which picked “tasks” from a queue. There is nothing wrong about that except for when you want describe a scenarion which involves some async process going on. But we have differentiate between different asynchronous/ blocking processes going on in a game. Btw. thread scheduling is way more costly in Windows than in Linux so it should be avoided to perform too many of it.
File I/O: This can be optimized in several ways and may not involve blocking at all. A naive approach is to have a directory of assets on the disk you'll load from time to time, 3D models, scene data, textures. The ususal stuff. But already this disk I/O can be optimized like a good CPU firendly code, the disk also has a cache. A usual disk cache is 64k, so padding your file to 64k will occupy the entire disk cache and everything else needs to wait. This may sound stupid but it guarantees that a reading process is finishing without the need to wait for another process to complete when your data is fragmenting in the cache. As an example: you have a file of 55k and one of 32k means that one process needs to wait for the other to complete in order to free the occupied cache space to load the remaining portion of the file into.
Using buffered streams is also a good alternative to plain file read/write operations. The stream caches a portion of the data your read/write and synchronizes it to/from disk if necessary. Speeds up performance also a little.
A more advanced file I/O operation optimization is memory mapped files. Those widely available OS feature lets the OS manage all your I/O in virtual memory pages. Again, a padding of 64k e.g. 4k (the usual OS page size) will improve performance. The OS is reading your file request from disk as usual but copies the contents over into a virtual memory page. This page is automatically freed up if not in use anymore and you can have a single file which is larger than your installed RAM (on-demand swapping). Another benefits is that more than one thread can process the file at once because everything is already in memory and you obtain a pointer to it rather than a file handle and so more than one trhead can read the same block of memory at a time.
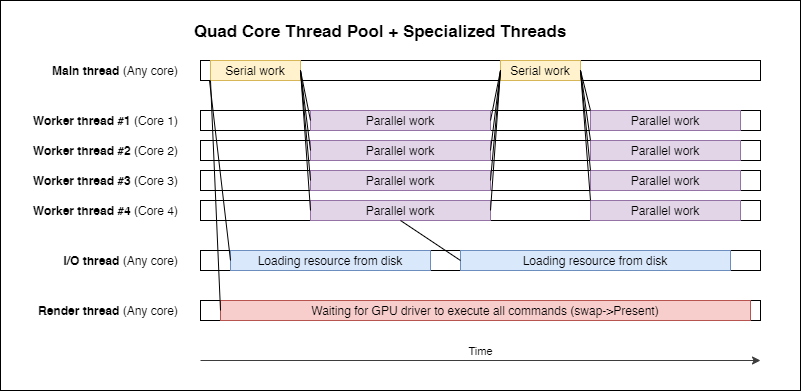
Network I/O: This should anyways be non-blocking and there are mechanisms built into the OS as well, which help to achieve that. It depends on your platform because Windows provides I/O Completion Ports (IOCP) while Unix and so most Consoles out there (Nintendo Switch/ Sony Playstation which seem to be build on the Unix Kernel) have the poll command to query a socket state. However, one can build up IOCP more easily within Linux than vice versa so I decided to go for IOCP. IOCP is, simplified speaking, an event object bound to a specific occurance (for example in network communication) which tells the caller that there are data to receive so that the next call to receive on a socket will be guaranteed to not block. Those event objects are queued by the OS so you can have more than one. For a client application, I always create 1 thread out of the thread pool and make this thread awaiting an IOCP event, on network heavy games it may become 2 threads. This threads are sleeping for as long as there isn't any network action going on and if they awake, I'll do nothing except pushing the package into the message queue, which is processed by my usual worker threads.
However, since all of this won't help on one thing, when tasks depend on other tasks to be completed, there was need for me to do some further research and I found this GDC Talk about to to paralelize your game with fibers: micro tasking without the OS thread scheduler. Fibers, once part of the OS but since they made too much trouble in the past Windows removed them, are a way to break execution of a function in order to allow something else to be done. They work similar to .NET tasks but don't involve a state machine nor require compiler magic to take place.
Our implementation is quite straight forward. We used some assembly instructions to create a new callstack on a virtual memory page. This stacks can be of any size, I tested 1kb for it and it seems to work for now. Then another assembly function comes in which performs a switch on the current thread, the current callstack is swapped with that one from the memory page, which leads to an entire switch from one point of execution to another.
It works quiet well on Windows (x86/x64) and Linux (x86/x64/ARM) and we build up our task scheduler from that two functions. It operates on our existing thread pool by occupying one thread for each CPU Core - 1 by spawning a worker on each of those threads. The main thread joins the scheduler as the “- 1”th thread so we can initialize our game engine properly and then operate on tasks only. The scheduler itself manages tasks by adding them to a random worker's queue in a round robin fashion. If a worker runs out of tasks, it'll begin to steal tasks from other workers or is set to sleep for as long as there isn't anymore work to do. Dispatching a task will resume a sleeping worker, this helps us to control CPU usage along with the amount of work to do and saves processing resources.
This sounds quiet similar to what I described before but the real magic happens when we hit our own Await functions. The task maintains a state which is an atomic integer and indicates the amount of work which has to happen before the task can resume. When a worker starts processing of a task, it's callstack is switched with a special bootstrap function. This function is small and only has to guarantee that the thread is never running over a task's boundaries (the task needs to pass the thread back to the worker by switching the callstack again). So we're switching from the worker to the task's callstack and start to execute the task, which may call await on every time while executing. An await sets the task's dependency counter to the amount of work to be awaited and switches the callstack back to the worker. The worker will then check the task for completion and else puts it into a waiting queue. This is queried for tasks ready to resume before a new task is picked from a worker's queue.
The system works like a charm and I was happy to observe a significant decrease of idle threads in our profiler