

Recently I implemented the forward+ tile culling for point light.
It seems there is a problem when storing variable with the index return by InterlockedAdd().
Here is the code section:
for (uint lightIndex = _threadIdx; lightIndex < _NumPointLight; lightIndex += TILE_SIZE * TILE_SIZE)
{
... calc tile plane, not important for this question so I skip them here ...
bool overlapping = SphereInsideFrustum(float4(lightPos, light.range), plane);
if (overlapping)
{
uint idx = 0;
InterlockedAdd(tilePointLightCount, 1, idx);
tilePointLightArray[idx] = lightIndex;
}
}
GroupMemoryBarrierWithGroupSync();
if (_threadIdx == 0)
{
// store opaque
_TileResult.Store(tileOffset, tilePointLightCount);
uint offset = tileOffset + 4;
for (uint i = 0; i < tilePointLightCount; i++)
{
_TileResult.Store(offset, tilePointLightArray[i]);
offset += 4;
}
}tilePointLightCount & tilePointLightArray are group shared variable.
And _threadIdx comes from SV_GroupIndex, each thread will cull 1 light.
Most samples use index return from InterlockedAdd when storing group shared variable.
However I got unexpected glitch tiles:
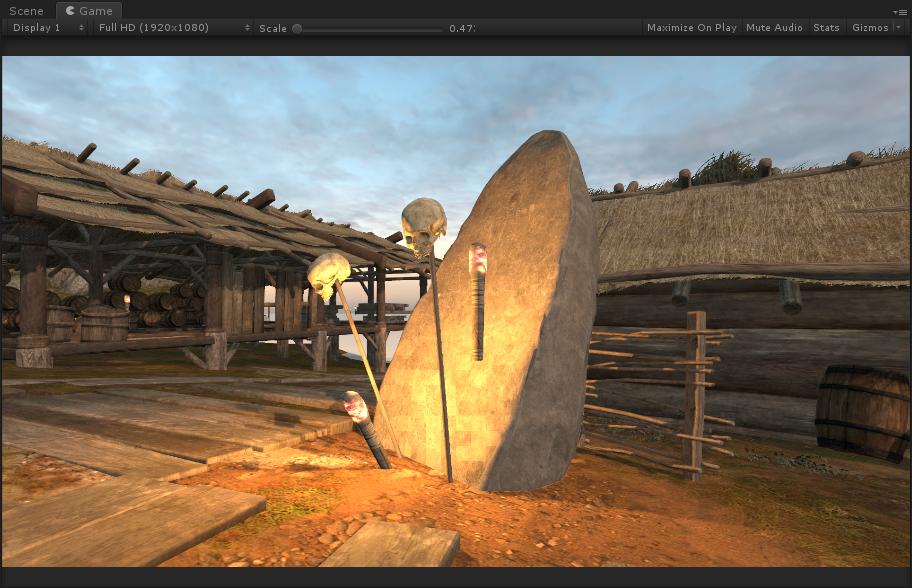
I've checked my algorithm and I'm sure the calculation is correct (including frustum, sphere-plane intersection).
Even I change overlapping to true and force shader to store every light index in array, the glitch still exists.
So I tried another code:
if (overlapping)
{
uint idx = 0;
InterlockedAdd(tilePointLightCount, 1, idx);
tilePointLightArray[lightIndex] = true;
}
if (_threadIdx == 0)
{
// store opaque
_TileResult.Store(tileOffset, tilePointLightCount);
uint offset = tileOffset + 4;
for (uint i = 0; i < _NumPointLight; i++)
{
if (tilePointLightArray[i])
{
_TileResult.Store(offset, i);
offset += 4;
}
}
}This time, I mark the light that is overlapped with tile and store the light index later with for loop.
Now the glitch is gone!
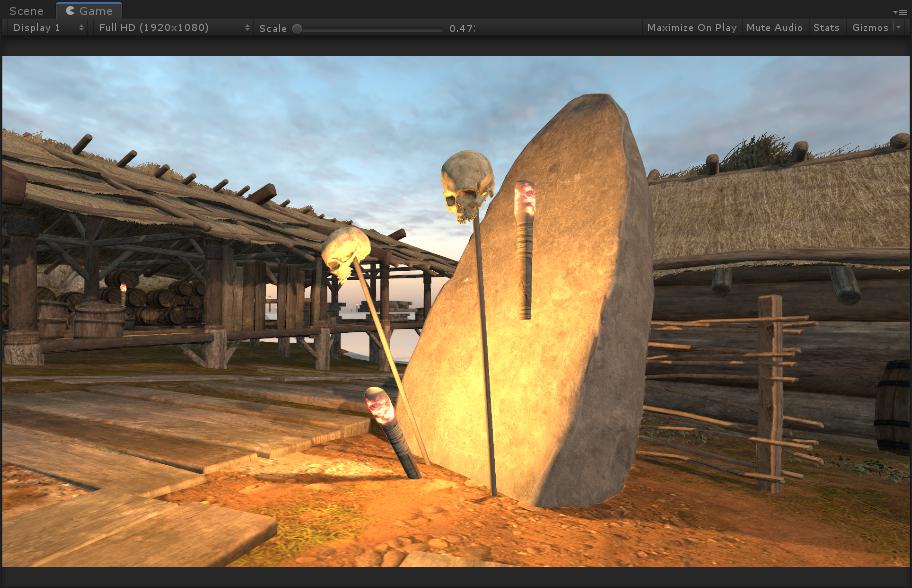
Both code section give me a boost on forward lighting calculation from 11ms to 0.48ms with 417 point lights.
However I need to use 2nd code section to get stable output.
Is there any problem in my 1st code?It should works like a charm.
Or is it a driver issue?My card is RTX 2070 with driver version 452.06.
I've heard other cases about InterlockedAdd() with nvidia card. For example:
https://forums.developer.nvidia.com/t/interlockedadd-limitations-since-v-334-67beta-v-334-89/32522
https://www.gamedev.net/forums/topic/694086-compute-shaders-synchronization-issue/
https://stackoverflow.com/questions/54794206/calling-interlockedadd-on-rwbyteaddressbuffer-multiple-times-gives-unexpected-re
I've tried to figure out this problem few days. Any suggestions would be great.
I really want to use 1st code, culling time is slower with 2nd code. (0.21ms -> 1.0ms if I use 2nd code.)
Thanks!


