I always solve the problem just after asking a question... Seems like I needed another barrier just before the parallel reduction. Anyhow, any optimization tips or other advice would be appreciated!

27 users logged in
Proud partner of GDC 2025

Before posting, review our community guidelines.
Support GameDev.net with a monthly GDNet+ subscription!
What good is hundreds of lights with out hundreds of shadows?

4,399
March 28, 2019 09:58 PM
If the reduction is only to find the sum or maximum of all values, using a simple atomic op on a LDS variable is faster for me than a reduction algorithm. (I use the latter only for prefix sums)
But might depend on GPU and compiler cleverness. (SM6 subgroup operations would be the way...)
I'm mostly worried about the 4x4 matrix that ends up in VGPRs. This could limit occupancy a lot - a profiling tool would show it. Personally i use quaternions and a translation vector in a similar situation, made a big difference for me.

March 28, 2019 10:36 PM
Interesting approach - I have played with ISMs few years back, but never got satisfied with the results and performance. Do I understand correctly that you render whole BVH nodes (e.g. as the actual node bounding box) in case they are small enough to ignore whatever is in subtree under that node? Out of curiosity - how do you build your BVH (I always have to ask!)?
As for me, I'm currently doing the standard rendering of shadow maps (i.e. for each frustum to be rendered - I do standard frustum culling, LOD, etc.), and results are stored in "virtual shadow map".
The hard part for me was determination of which lights require to have shadows (originally I based it on testing light volume against frustum - but had to also add lights that 'could be seen in reflective objects' - these receive lowest score, but if space is available in virtual shadow map - they get rendered).
While this approach can easily handle hundreds of shadow casting lights too (technically any number!) - you have no guarantee that every light that will be requesting shadow map rendering will get it rendered. It also gives me ability to limit how many pages I want to update each frame (gives you nice scalability on various hardware).
And as my curiosity grows:
How do you determine which shadows should be rendered (directly testing 'light volume' against frustum only?). Or do you render shadow map for all of them?
I also noticed you are using a texture atlas to pack shadow maps in (each cube face separately for point lights), how do you perform the filtering (especially across cube map edges)?
My current blog on programming, linux and stuff - http://gameprogrammerdiary.blogspot.com

March 28, 2019 10:39 PM
Interesting. I expected an atomic used like that to cause thread stalls or something...
I was thinking about doing two passes in the kernel - one to sum up the number of output nodes, triangles and points that the whole thread group will create. Then allocate slots in the output buffers for the whole thread group using a few atomic adds on a buffer variable somewhere (not sure where is best to store these counters). Then do the final pass to copy the data into the output buffers.
March 28, 2019 10:50 PM
Vilem: the point at which a node is too small to traverse further is when it is roughly one pixel big, so it is rendered as just a pixel.
At the moment I just render shadow maps for lights that are in the view frustum.
There is a link to the paper that describes the method that I use for bulding the bvh on my blog post about rendering thousands of dynamic lights.
4,399
March 28, 2019 11:10 PM
22 minutes ago, fries said:I was thinking about doing two passes in the kernel - one to sum up the number of output nodes, triangles and points that the whole thread group will create. Then allocate slots in the output buffers for the whole thread group using a few atomic adds on a buffer variable somewhere (not sure where is best to store these counters). Then do the final pass to copy the data into the output buffers.
Likely you know this: Usually it's faster to cache the piece of worklist a workgroup creates in LDS using LDS atomics. Then at the end of the shader the first thread does only one atomic to global memory to reserve space and finally each thread copies a value from LDS to global mem in order.
Looking your code again this might indeed be a win:
// Append the child node-views to the OutNodeViewBuffer
uint2 children = node.GetChildIndices();
uint maxNodes1 = AppendNodeView(children.x, nodeView.mViewIndex, nodeView.mViewRadius, nodeView.mObjectInstanceIndex);
uint maxNodes2 = AppendNodeView(children.y, nodeView.mViewIndex, nodeView.mViewRadius, nodeView.mObjectInstanceIndex);
This looks like each thread writes to global memory directly. (Vulkan/GL has no append buffers, so i lack experience here)
Your LDS usage seems low, so you can afford to cache easily - it's surely worth to try out.
4,399
March 29, 2019 07:51 AM
8 hours ago, Vilem Otte said:Out of curiosity - how do you build your BVH (I always have to ask!)?
The basic idea of Many LoDs / ISM, point hierarchies in general is to have geometry and tree in one data structure to get easy dynamic LOD, obviously.
So also internal nodes can become 'visible', and that's a big problem. Imagine two seperated red and green boxes and then zooming out. First each box becomes just one pixel, but at some distance both boxes merge to a common yellow point in the middle between the two.
I think that's the main problem of those approaches. Personally i solve it by duplicating nodes to the parent as long as possible to make the merge as distant as possible, but at the same time i increase the number of nodes which can cause other bad side effects. Building the tree becomes pretty complex for me because of this. But it's still fast (less than 0.1ms actually with my smaller scenes).
9 hours ago, Vilem Otte said:you have no guarantee that every light that will be requesting shadow map rendering will get it rendered.
How do the resulting artifacts look? Can this be acceptable at distance?
The main problem with shadow maps i see is the inability to time slice their updates - all of them needs to be updated per frame if there is movement in their view.
If we had object space shading, RT shadows could do stochastic updates on individual texels. Workload could be distributed over several frames. That's the point where RT shadows will outperform SMs i guess. But neither is perfect.
A compromise is shown in this paper: http://www.cse.chalmers.se/~d00sint/more_efficient/clustered_shadows_tvcg.pdf
It updates only regions of shadow maps that need the update and uses RT if the SM texel count is so small raster is not worth it. Very complex, and still requires to update at least partially.
March 29, 2019 05:47 PM
9 hours ago, JoeJ said:How do the resulting artifacts look? Can this be acceptable at distance?
I honestly can't tell - in examples where you put many lights around I can't really tell much (GI also plays major role in this enabled). Here is an example screenshot from editor:
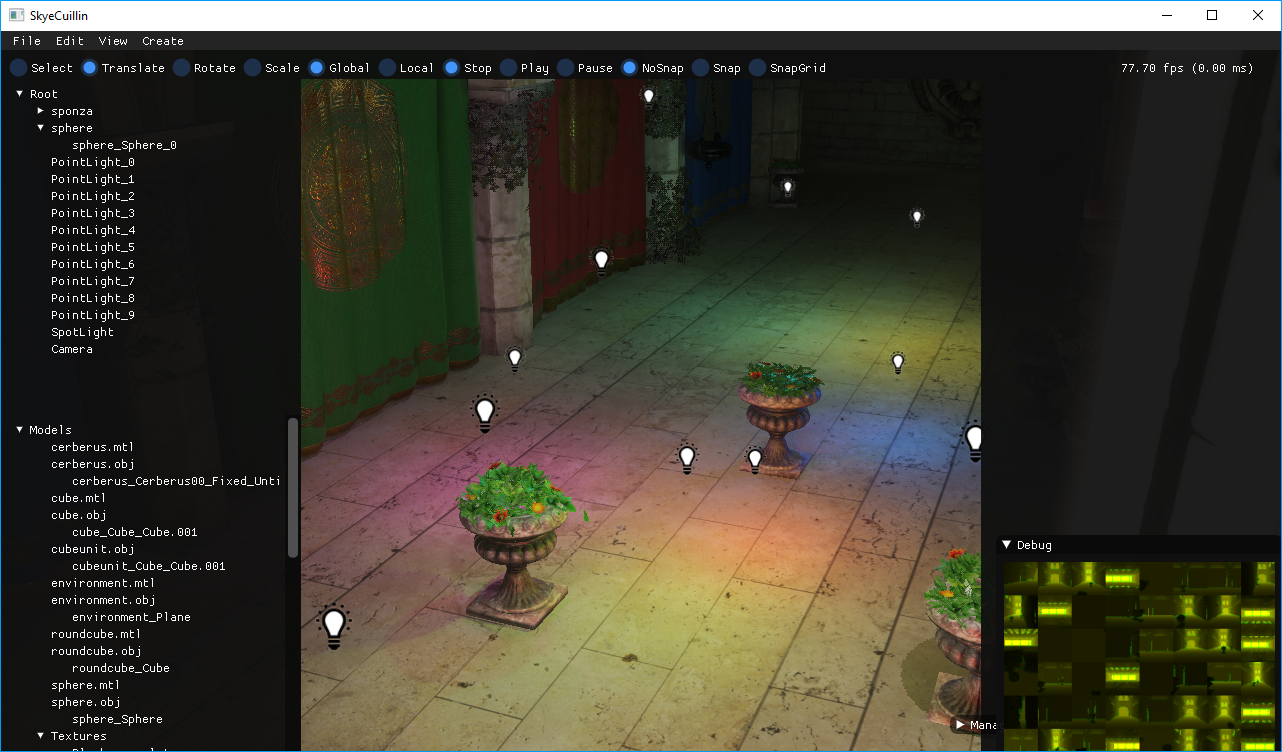
You can see virtual shadow map in bottom right - there is 10 point lights, 1 spot light in the scene, and I'm quite sure they couldn't all fit into virtual shadow map. If a tile doesn't get fit - light doesn't obviously cast any shadows (for point light - it can be even be F.e. 1 face not casting shadows, while others do).
I colorized the lights to make shadows more visible - yet even then it is hard to tell where shadows are (GI makes this hard to distinguish).
If the problem gets visible, you can always increase size of virtual texture (therefore increase number of active pages), decrease resolution for lights (and also size of single page). I'm also considering exposing importance factor for each light (so users could make sure that some lights will case shadows).
A video (with texturing and GI enabled/disabled) might be good to show this in action - sadly I'm too busy to do it today, but I may get to it over the weekend (no promises though - my TODO list grows at faster speed than at which I'm able to finish items from it).
My current blog on programming, linux and stuff - http://gameprogrammerdiary.blogspot.com
4,399
March 29, 2019 07:32 PM
1 hour ago, Vilem Otte said:I honestly can't tell - in examples where you put many lights around I can't really tell much
Thanks! I never considered missing shadows could go unnoticed, always thinking they would be totally black, haha ![]()
I see the problem is not as worse as i thought.
This topic is closed to new replies.
Advertisement
Popular Topics

Advertisement
Recommended Tutorials

Advertisement