I started working on a raytracer project (again) and ran into a problem when compiling a Debug configuration.
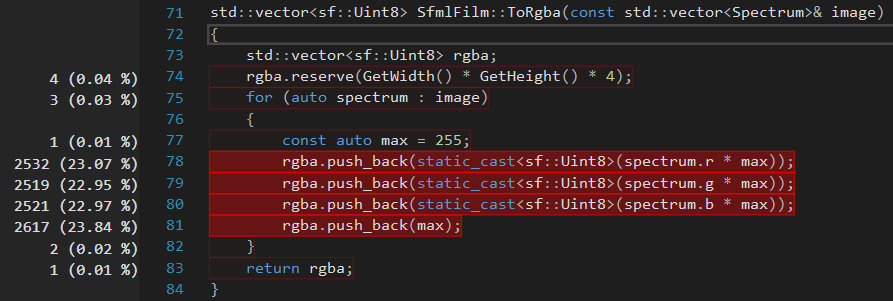
All I have at the moment is a set of pixels in float RGB format that I convert to unsigned char RGBA format that SFML wants. This happens once per frame, running at 200+ FPS in Release mode, but 1 FPS in debug mode. Please have a look at the attached profiling result.
It seems to spend almost all of its time in std::vector::push_back().
Is there any way to speed up this process? Could I create all elements in a batch and then start filling in values? Is there some handy use of std::transform that I could apply?
Thank you in advance!
std::vector<sf::Uint8> SfmlFilm::ToRgba(const std::vector<Spectrum>& image)
{
std::vector<sf::Uint8> rgba;
rgba.reserve(GetWidth() * GetHeight() * 4);
for (auto spectrum : image)
{
const auto max = 255;
rgba.push_back(static_cast<sf::Uint8>(spectrum.r * max));
rgba.push_back(static_cast<sf::Uint8>(spectrum.g * max));
rgba.push_back(static_cast<sf::Uint8>(spectrum.b * max));
rgba.push_back(max);
}
return rgba;
}