Your vertex shader is expected to output vertices in "clip space", where X, Y are between -W and +W and Z is between 0 and +W, and everything outside of that range is clipped (see the section called "Viewport culling and clipping" in this article for more info, or google for "clip space" to find some more resources if you're curious).

(note that this image is using OpenGL conventions where Z is between -W and +W, whereas D3D specifies that Z is between 0 and W)
The rasterizer expects homogeneous coordinates where the final coordinate will be divided by W after interpolation, which is how you get to the [-1, -1, 0] -> [1, 1, 1] "normalized device coordinate" space that you're referring to in your above post.
So with the details out of the way, let's say that we wanted to position a triangle so that it has one vertex at the top-middle of the screen, on one the right-middle of the screen, and one in the very center of the screen:
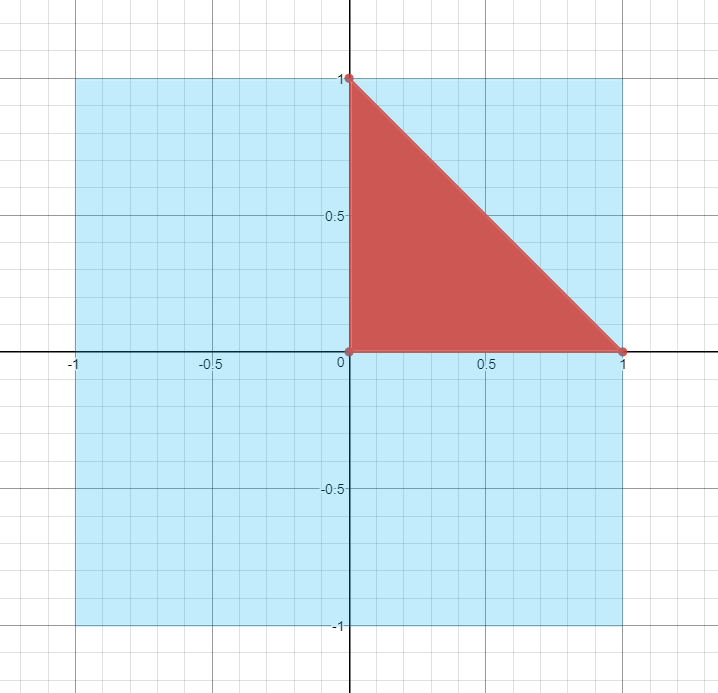
The easiest way to do this is to use a value of 1.0 for W, which means we can specify the XYZ coordinates in NCD [-1, -1, 0] -> [1, 1, 1] space. So to get the triangle where we want, we could set the three vertices to (0, 1, 1, 1), (1, 0, 1, 1), (0, 0, 1, 1). If we do this, the triangle will be rasterized in the top-right quadrant of the screen, with all pixels having a z-buffer value of 1.0.
In practice, you usually don't calculate vertex coordinates in this way except in special circumstances (like drawing a full-screen quad). Instead you'll apply a projection matrix that takes us from camera-relative 3D space to a projected 2D space, where the resulting coordinates are perfectly set up to be in the clip space that I mentioned earlier. Projection matrices typically aren't too fancy: they're usually just a scale and a translation for X, Y, and Z, with either 1 or Z ending up in the W component. For 2D stuff like sprites, orthographic matrices are usually the weapon of choice. For X and Y, an orthographic matrix will usually divide X and Y by the "width" and "height" of the projection, and possibly also shift them down afterwards with a translation. If you think about it, this is a perfect way to automatically account for the viewport transform so that you can work in 2D coordinates. Let's say you wanted to work such that (0, 0) is the bottom left of the screen, and (ViewportWidth, ViewportHeight) is the top. To go from this coordinate space to [-1, 1] NCD space, you would do something like this:
// Go from [0, VPSize] to [0, 1]
float2 posNCD = posVP / float2(VPWidth, VPHeight);
// Go from [0, 1] to [0, -1]
posNCD = posNCD * 2.0f - 1.0f;
Now you can do this yourself in the vertex shader if you'd like, but if you carefully look at how an orthographic projection is set up you should see that you can use such a matrix to represent the transforms that I described above. You can even work an extra -1 into the Y component if you wanted to have your original coordinate space set up so that (0, 0) is the top-left corner of the screen, which is typical for 2D and UI coordinate systems.
Perspective projections are a little more complicated, and aren't really set up for 2D operations. Instead they create perspective effects by scaling X and Y according to Z, so that things appear smaller as they get further from the camera. But your typical symmetrical perspective projection is still doing roughly the same thing as an orthographic projection, in that it's applying a scale and translation so that your coordinates will end up with (-W, -W) as the bottom left of the screen and (W, W) as the top right. One of the major difference is that an orthographic projection will typically always set W to 1.0, while a perspective projection will typically set it the Z value of the coordinate before the projection was applied. Then when homogeneous "divide-by-w" happens, coordinates with a higher Z value will end up being closer to 0, which makes geometry appear smaller as it gets further away from the camera.







