This is a follow-up-slash-rewrite of an article I wrote a while back on a technique I called 'Precalculated Pathfinding.' There were a few problems I didn't address, partly because I didn't have answers to them and partly because they hadn't occurred to me. Well, after recently solving the problem which bugged me the most (the problem of dynamic networks), I've decided to attack this thing again. I'll give a complete description of the initial technique again too, so you don't have to go and find the other article. Precalculated Pathfinding (or "Fine's algorithms" as I hope they will come to be known ;-) ) is a way of storing all possible paths through a network, eliminating most real-time pathfinding operations. It's also a very useful way of having an AI 'learn' the paths through a network. However, it's a trade - memory for speed. Also, the fact that the routes are 'precalculated' - calculated once, before the game begins - means that you have to respond to changes in the world (which may create or block routes through the network). I'll be addressing both these problems.
Initial Concept
Given that the route ABCD is the shortest route from A to D, it can be proven that BCD is the shortest route from B to D. It's as if any given 'shortest route' is made up of smaller 'shortest routes.' If there were a shorter route from B to D, for example BED, then the shortest route from A to D would have to be ABED. And so on. So, we can say something like this:
route(A->D) = AB + route(B->D) and we know for a fact that's the shortest route. While we're at A, it doesn't actually matter to us what the shortest route from B to D is; we just know that the we're going to use it. We can find out what it actually is once we get to B. All we're interested in right now is 'where to go next.'
The Foundation
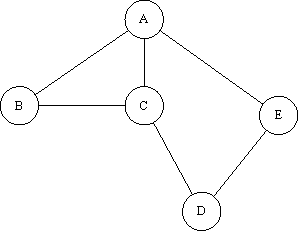
That 'where to go next' is a pretty powerful concept. Imagine that once we're at B, our target changes and we want to get to E? We won't have wasted any time calculating the rest of the route to D; we can instantly change our target and say 'ok, so where do we go next to get to E?' These 'where to go next' values can be stored neatly in a table. And we love tables, don't we? Let's take the sample network:
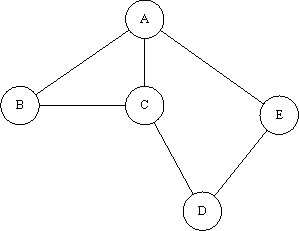
From this network, using any pathfinding algorithm you feel like (I just used visual inspection, so I might not always get the shortest path - but you'll get the idea), you can build the following table:
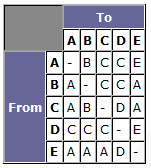
To recap: I built this table by finding the route
From each given node
to each given node, and storing the first node in the route (excluding the start node). To use the table, all you need to know is your current location, and your destination. Feeding the current location in as your 'from' value, and the destination in as your 'to' value, you get the next node you should move to. In any sensible implementation, connections between nodes are simple straight lines where no obstacles are present, so actually moving to the next node should be a cinch. This technique also has the advantage that it can cope instantly with changes both in position and destination, without having wasted any processing time (at a time when processor real-estate is at a premium). Using conventional pathfinding techniques, you have to calculate the entire route to the target - sometimes you'll do that each time the bot reaches a new node, but you may have optimised by storing the path in the bot's "memory." Let's say that you've calculated a path that is 10 nodes long. Your bot begins to move, but after traversing 2 nodes, the target changes (the enemy has moved, or the bot has been given new orders, or something). So, a new path is calculated, and the old one discarded. That means you processed 8 nodes which never got used - and yes, there's no way you could have predicted the path would have been discarded or when, but it's an obvious waste of processor time. With this technique however, you process all the nodes before the game starts - perhaps even at development time, where the table can be stored in a file - and once you're in-game, you never have to waste time looking at nodes which don't get used. Let's play a little game with our network. We'll place a 'hare' at A, set to follow the path AEDCA repeatedly. We then place our 'dog' at D, and watch it track (and, finally, catch) the hare.
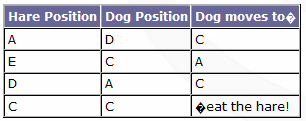
Notice how, in the third row, the dog actually doubles back on itself - if it didn't, our racetrack critters would be stuck in an endless loop (symbolic maybe, but that's far too philosophical for this article). In a more usual game situation - because our dog-race example is based around the same simple 'terminator' AI that people realised wasn't terribly interesting several years ago - there'd be other information influencing the path. For example, each node could also contain the distance to and location of the nearest health-pack, so that the AI could choose to take a little detour to pick up a medikit, if not too far away. The same sort of idea can be applied to all number of in-game objects the AI might find significant - ammunition, etc - things which don't move around. Of course, each time you store something else in the table, you're using up more memory, so you need to make sure you stay efficient. If you want to be aware of nearby objects which could be
moving, then it gets a little more difficult. I'll look at such a situation later on in the article.
Dynamic Worlds
One of the biggest problems people emailed me about after the last article was 'how do I deal with a network which changes?' For example, say a ceiling collapses somewhere, removing one of the paths between two nodes. How do we deal with that, without recalculating the entire network? I think I have a solution now (oddly enough, penned while sitting around at a game development studio, waiting for an interview), so here you go, boys and girls. We're only going to deal with a situation where one path has been removed. We can't escape recalculation altogether in a properly dynamic network - there's no way of knowing which paths would disappear/reappear and when - so we want to minimise the number of nodes we process. The technique uses a sort of 'ripple propagation.' As we move further away from the affected path within the network, the number of nodes needing to be processed get fewer and fewer, until eventually the network doesn't change - like how a ripple dissipates as you get further from the point of impact. The algorithm is recursive/repetitive. For each node you feed in, you recalculate it, and compare the recalculated version to the original version. If there have been no changes, then obviously the node is not affected by the change in the network, so processing of this node stops. However, if there have been changes, then you process all nodes connected to the current node (that have not already been recalculated).
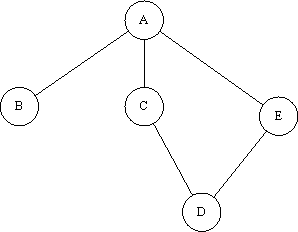
Let's take our network from earlier, and remove the path BC: The original path table looked like this:
We'll keep two lists - a 'nodes to be processed' (tbP) list and a 'nodes already processed' (aP) list. To begin with, the tbP list is 'BC' and the aP list is empty. We process the first node on the tbP list - B. Using visual inspection again, we rebuild the row in the table. In fact, in this case, we can see that B only has one path left, so all its values will have to use that path. So, the original row was:

And the newly calculated row is:

We can see that the row has changed. So, we get all the nodes which
were connected to B - that is, assuming the connection BC still exists - and see if we need to process them. The list of nodes connected to B is AC. Node A does not appear in either the tbP or aP lists so we add it to the tbP list. Node C is in the tbP list already, so we leave it alone. That's node B done, so we move it from the tbP list to the aP list, and move to the next node in the tbP list. The tbP list is now 'CA' and the aP list is now 'B.' The current node is now C. The original row for C was:
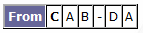
The newly calculated row is:

It's only a small change, but it's a change. So, we get our list of nodes that used to be connected to C - 'ABD' - and work out which ones need adding to lists. A is already in the tbP list; B is in the aP list; but D is in neither, so we add it to the tbP list. Finally, we move C to the aP list. The tbP list is now 'AD' and the aP list is now 'BC.' The current node is now A. The original row for A was:

The new row for A is:
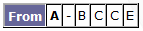
No change this time. So, we can move A to the aP list and continue processing the tbP list, without adding any more nodes. The tbP list is now 'D' and the aP list is now 'BCA.' The current node is now D. Original row for D:
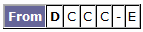
New row for D:
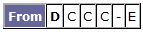
Again, no change, so we move D across to the aP list. Now, the aP list is 'BCAD,' but the tbP list is empty - which means we've finished. The new path table is:
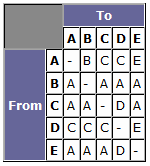
Notice that we didn't even need to process node E with this method. The path from node E to node B hasn't changed (EAB), but it could quite easily have done. The two lists can, in fact, be combined - you could just use one list and keep a 'cursor' in it, rather than using the top node of the tbP list each time. The method can be used for both adding paths and removing paths - you just ensure you start with the correct nodes in the tbP list. As for adding/removing nodes, nodes are only significant in the network when they have connections. A node with no connections might just as well not exist. So, when removing a node, simply remove all of its connections (using the method described here), and when adding a node, simply change the network and propagate the change (again, using this method). The only thing you need to watch out for when adding a node is that the path table will have to be expanded to have room for the new node's routes. Often, you'll have a situation where more than one path has to be added/removed. You could simply add/remove each path in turn; however, that would result in having to recalculate some nodes several times, rather than just the once that a single path would require. So, you can actually do as many paths as you want at once; you just make sure that all changes have been made before propagation begins, and that the tbP list contains
all the endpoints of the affected routes. When adding routes AB and CD, you start with a tbP list of 'ABCD,' and so on. It's more efficient than propagating each path separately.
Education
There's another interesting thing about this technique. Let's say that rather than having one globally shared table, we give each bot in the world it's own table - and this table starts with one row/column, for the node the bot is currently at. Now, we add all the nodes that the bot can 'see,' using the propagation method described earlier. So our bot has a limited knowledge of the world; it can traverse the part of the graph that it 'knows' about.
We're about to need another table. I'll call this a 'magnitude' table - it's a table of the number of connections each node in the network has. For the network we've been using throughout this article: It looks like this:
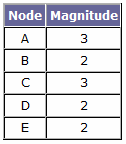
So, how does this help us? Well, our bot can take any given node in his 'view' of the network, and compare its magnitude to the value in the table. If his value is smaller than the 'global' value, (we'll call it the 'optimum magnitude'), then it means he hasn't fully 'explored' that node yet - there are routes beyond that node that he doesn't know about yet. So, let's give our bot a new type of idle behaviour - 'explore.' He can do it when he has no achievable goal. When exploring, what he does is to pick a nearby node with a less-than-optimum magnitude, and go to it. When he reaches it, he should be able to see other routes, thus increasing his magnitude for that node until it becomes optimum. This behaviour could be linked to other ideas - for example, he could be instructed to stay within a certain radius of a point, or within the line of sight of a given node. It could be linked to a more complex idea: for example - the bot finds a trail of blood on the floor, increasing the probability of nearby nodes being explored relative to other nodes ('investigation'). Maybe he sees a sign saying 'danger,' which decreases the probability of nearby nodes being explored ('caution'). Simply adding a probability system to the node-picking code can be immensely powerful. It would also not be too difficult to implement 'forgetfulness.' Simply: every now and then, pick a route in the bot's view of the network (preferably one far away), and remove it. If you'd prefer, maybe add a non-existent route (although that would mean you'd have to take care of situations where the node's magnitude is actually
greater than the optimum). It can be a pretty powerful behaviour. Linking it into other parts of the AI - for example, scripted sequences - could produce some impressive effects. Right now, I'm getting the image of watching a group of soldiers in explore mode, finding and opening the door to a room with an extremely large monster in, screaming, and running away. Woo! What are the problems with this technique? The first, and most obvious one, is that of memory usage. With a large network, keeping a path table for each bot in the world will often be totally unfeasible. The optimisation I'd probably go for is to try and find ways to group the bots into 'squads,' and have each squad share a path table. Bear in mind, though, that very often a bot won't get round to exploring an entire network - they might be constrained to specific area, either by artificial constraints ('stay within radius' rules), or by their part of the network simply being isolated with no entry/exit routes (for example, in a set of rooms which the player reaches through the ventilation ducts). If there are no constraints, then the tables could get quite large. However, the only time I could see a bot having no constraints would be if the bot were a 'principal character' of some sort - and you don't tend to have many of them, so the problem solves itself.
Progressive nets and subnets
Another problem people emailed me about was using networks over large worlds. Not necessarily large networks; just networks which needed to cover large distances. Particularly over open terrain (Delta Force type worlds). I think I have a solution which will help some people out. It also applies to some other situations too; large worlds with many enclosed spaces, for example. Here we go: split nodes into 'levels.' That is, have a top level (level 0) which contains a 'general' set of nodes - nodes which cover most of the world, but are very coarse. The routes between them are like Interstate roads. Into the next level, you put nodes which, while not totally in-depth, are more detailed than the Level 0 nodes. These are like your main roads. What's more, you give each Level 1 node a list of 'parent' Level 0 nodes. If you had an area of the world enclosed by routes between 4 Level 0 nodes, the Level 1 nodes inside the enclosure would have the 4 Level 0 nodes as parents. The Level 0 nodes, in return, keep lists of all Level 1 nodes which have them as parents. This means that you can take any given Level 0 node, and load into memory all 'nearby' Level 1 nodes. This goes on for as many levels as you want (is 'progressive'), right until you're down to the small routes which are like people's driveways. Each level (excluding Level 0 and the smallest level) has lists of both parent and child nodes. So, from anywhere in the world, you can follow a node back to the 'interstate,' use the Level 0 nodes to get near to your destination, and then progressively use smaller and smaller levels to get closer and closer to your destination. There are routes between nodes in any given level and the nodes in the level above - Level 1 is 'anchored' to Level 0 by such routes. So, only Level 0 is a complete network (in that of its routes and nodes are a part of it), unlike the other Levels which have dependencies on their parent levels. This concept of Levels or 'sub-networks' can be extremely useful. Imagine a world containing many buildings which can be explored. The nodes in each building can be grouped into a subnet, and only loaded when the building is actually being traversed, saving large amounts of memory.
Echoes of the Past
When tracking prey by scent, a predator will follow by picking up the scent and then continually checking in which direction the scent is strongest. If tracking is left too late, then the scent may have faded and so the prey cannot be tracked. Here's an idea inspired by that. Have moving entities leave 'scents' in the network which can be followed by others. This would deal with the problem of tracking more than one moving target (the most recent scent would indicate the nearest entity), and the problem of an entity moving out of sight (perhaps even out of the network, if the 'education' technique is in use). Give each node a list of pairs of entity IDs (or whatever) and timestamps. Then, whenever an entity visits a node (moves within a certain radius of it), either update the timestamp, or add it to the list if it not already present. When tracking by scent, the predator bot needs the entity ID of its prey (or some way of checking any entity ID to pick out interesting scents), and a node that the prey has visited. Then, it searches all connected nodes, and finds the node with the most recent timestamp for the given entity ID. It moves to that node. There's also a certain amount of clean-up that needs to be performed, too. Looking back to our original inspiration, a scent 'fades' after a certain amount of time. Once a scent has faded, it needs to be removed (well, it does if you don't want to run out of memory). Rather than checking the entire network for 'expired' scents frequently, we only need to ensure that the nodes we're processing are up-to-date - so, the scent list only needs to be cleaned up when it's being examined. As a result, the number of nodes you process is proportional to the number of entities in the network, rather than the size of the network. Why use timestamps rather than a simple decrementing counter? Because a decrementing counter still needs to be decremented. Every game loop, you'd have to process the entire network, decrementing all the counters - and that's one heck of a performance hit, especially for a large network. When you take into account that many nodes may not have scents attached to them anyway, it is obviously inefficient. Timestamps only need to be calculated once, and are unchanging (until they are updated or removed); they're also much more versatile, in that different entities can use them in different ways. A decrementing counter only tells you how many iterations are left until the scent disappears; a timestamp, on the other hand, tells you how long the scent has been there, too. There's a whole bunch more variations on this theme. Firstly, playing the with 'fade times' is definitely a good idea. Different scents could linger for different times; different predator bots could have their own 'threshold' values (for example, a bot tracking by sight rather than smell would have a fairly small time threshold). That does create a problem with cleanup - you can't be sure that a scent has faded to a point that no entity will detect it - but simply picking a sensibly large 'threshold' value should ensure that no entity is 'robbed' of the scent. It's a trade-off - the larger the value, then the surer you can be that entities will be able to pick up scents properly, but the more memory you use. Also, be aware of movement speeds; when presented with two scents, the more recent of the two doesn't necessarily mean the nearest, because the more recent entity might move many times faster than the less recent, and so might be further away. Finally, linking fade times into the nodes themselves could be very interesting, as I hinted at earlier. Perhaps nodes in a small river would have much quicker fade times - any predator tracking to the river would lose the scent, unless the prey had entered the river very recently.
Conclusion
I hope you've figured out by now that you can attach pretty much any information to a node - be it a 'scent,' a mood, a warning, a reference number... you name it. And much of that information is static, and can be precalculated - found by a compiler tool, stored to a file, and then loaded and decompressed for instant use in-game. The network can be used not just for finding a route, but for deciding whether to use it. Whenever you work with node networks like these, remember your constraints:
- Minimise memory usage, mainly through minimising duplication of information.
- Process nodes 'on-demand,' rather than forcing the whole network to be processed frequently.
- Keep good connectivity in your game worlds to make the networks efficient.
- Don't be afraid to use the network for more than just pathfinding.
I think I've covered everything I wanted to cover. Feel free to email me at [email="rfine@tbrf.net"]rfine@tbrf.net[/email] - I'll be happy to answer questions, discuss problems, and merely hear about how you're using the technique and how it's working for you. So.. until next time...



