
Recently I put mesh shader into practice in my Vulkan pet project.
And it’s just too good!
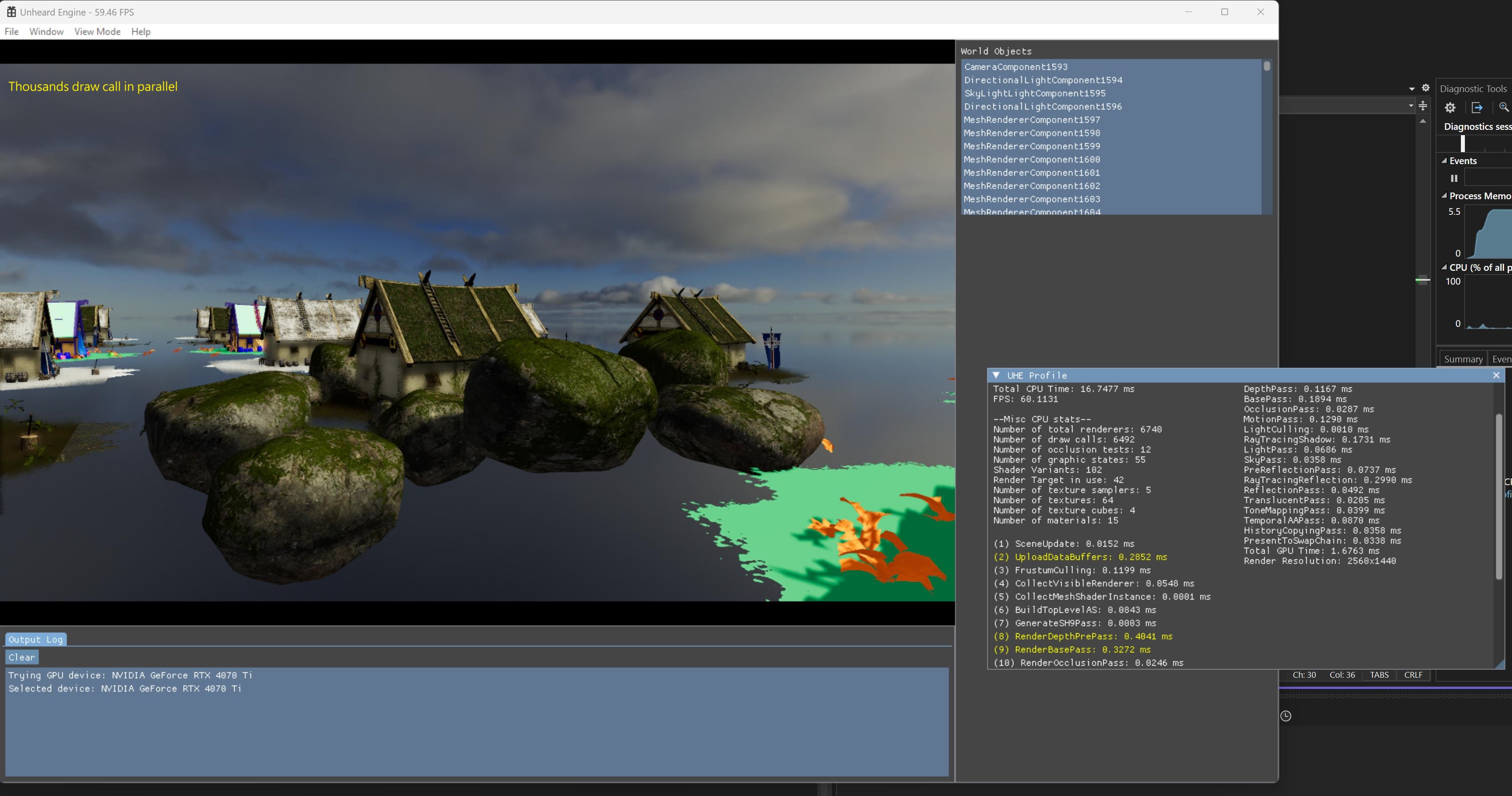
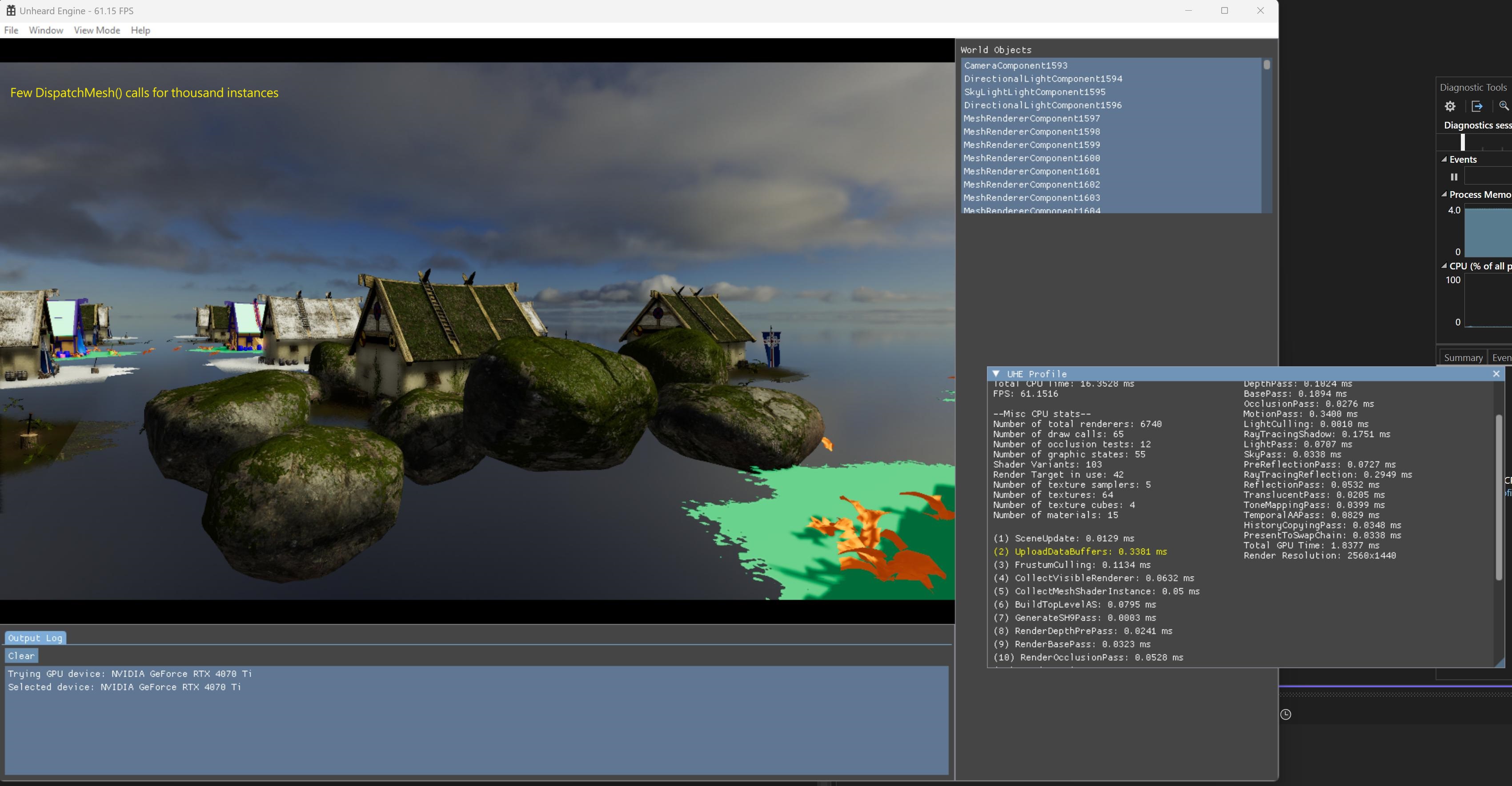
Before and after the mesh shader is applied, it reduced the render thread significantly from 0.3~0.5ms to 0.02~0.03ms for the same set of mesh renderers.
I’ll detail how it’s done here.
Mesh shader references, I learned mesh shader from D3D12 and converted it to Vulkan implementation.
https://microsoft.github.io/DirectX-Specs/d3d/MeshShader.html
https://github.com/microsoft/DirectX-Graphics-Samples
*Disclaimer: This is just a personal practice of engine programming. Seeking something else if you're for game developing.
Git link: https://github.com/EasyJellySniper/Unheard-Engine
Overview
Before stepping into mesh shaders, let me assume a scenario:
There is a scene with multiple renderer instances, those instances could have different meshes, materials, object constants and must be drawn separately.
Which causes an obvious performance spike on CPU, how could we improve this?
To deal with this, we want to do “draw call batching” and make CPU send fewer commands for executing the same amount of instances as possible.
Now let me review a few old ways to do this (except visual culling).
Merge static meshes
In some engines, this is called “static batching”. The idea is to merge meshes by certain rules (E.g. Merge those use the same material).
Despite this can reduce the draw call much, it also introduces higher GPU overhead and stalling as there’re more vertices to process in one call.
Merged meshes also make bigger bounding and make visual culling less efficient…
GPU Instancing
With the function call such as DrawIndexedInstanced().
We can tell GPU to output multiple instances.
However, this needs to work within the same vertex/index buffer.
To start another instance with a different mesh, I still need a new DrawIndexedInstanced() call.
Parallel Draw Bundles
In Vulkan, this is the secondary command buffers.
By recording draw calls on multi-threads to reduce the CPU time.
It works but can still hit the performance if there’re high number of instances.
Indirect Drawing
It is possible to store draw arguments of DrawIndexedInstanced() as a buffer and execute it afterward.
The arguments can be collected on GPU side too, e.g. from the compute shader.
Make GPU-based rendering much easier. Again, however, this needs to work within the same vertex/index buffer.
These methods have one thing in common:
Input Assembly limited! We just can’t achieve these without setting up IA stage properly.
Not to mention you might have various input layouts for different purpose…less chance to reuse a graphic pipeline state.
With mesh shaders, this limit will be gone.
Use Mesh Shader In Vulkan
As like how I implemented ray tracing in my pet project before.
My implementation is HLSL based. So it’s important to get the latest DXC to generate spir-v mesh shader module properly.
And send the following parameters when compiling:
-fspv-extension=SPV_EXT_mesh_shader // or SPV_NV_mesh_shader
-fspv-extension=SPV_EXT_descriptor_indexingThis tells the compiler I'm going to use mesh shader in Vulkan, as well as the descriptor indexing for bindless rendering.
And on the C++ side,
Enable VK_EXT_mesh_shader device extension. (Or VK_NV_mesh_shader)
Setup VkPhysicalDeviceMeshShaderFeaturesEXT for device creation info. (Or VkPhysicalDeviceMeshShaderFeaturesNV)
Remember to assign VK_SHADER_STAGE_MESH_BIT_EXT flag if a descriptor is bound in mesh shader.
Remember to assign VK_SHADER_STAGE_TASK_BIT_EXT flag if a descriptor is bound in amplification shader.
Have a correct Vulkan version. I can't particularly say which version of Vulkan is the starting version that supports the mesh shader. And I'm on 1.3.283.0.
As for graphic state pipeline creation, simply set the shader stage like:
VkPipelineShaderStageCreateInfo ASStageInfo{};
std::string ASEntryName;
if (bHasAmplificationShader)
{
ASEntryName = AS->GetEntryName();
ASStageInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
// In Vulkan, AS shader is treated as task shader
ASStageInfo.stage = VK_SHADER_STAGE_TASK_BIT_EXT;
ASStageInfo.module = AS->GetShader();
ASStageInfo.pName = ASEntryName.c_str();
}
VkPipelineShaderStageCreateInfo MSStageInfo{};
std::string MSEntryName;
if (bHasMeshShader)
{
MSEntryName = MS->GetEntryName();
MSStageInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
MSStageInfo.stage = VK_SHADER_STAGE_MESH_BIT_EXT;
MSStageInfo.module = MS->GetShader();
MSStageInfo.pName = MSEntryName.c_str();
}And DOES NOT need to assign the pVertexInputState and pInputAssemblyState, wonderful!
The mesh shader implementation
Pseudo code below shows how draw commands are called before / after mesh shader is applied in my pet project.
// before - this is running on multi-threads for different instances
for (i=StartInstance; i<EndInstance;i++)
BindResource()
BindState()
BindMesh()
DrawIndex()
// after
for (i=StartMaterialGroup; i<EndMaterialGroup; i++)
BindResource()
BindState()
DispatchMeshInstancesThatShareTheSameMaterial()
Use the screenshot in very top of this post as an example.
I have 6740 renderer instances in test scene, and about 3k instances are visible.
They were rendered in both depth-pre pass and base opaque pass, so there were 6k draw calls in parallel with the old method.
After the mesh shader is applied, the number of DispatchMesh() call is equall to the number of materials only. Which is 15 in my case.
But these dispatches can deal with all instances properly. Of course this would be a huge improvement!
vkCmdDrawMeshTasksEXT() is the call for the purpose. On CPU side, I make it collect all meshlet data that are sharing the same material and store in structured buffer for use.
// mesh shader data structure define
struct UHMeshShaderData
{
uint32_t RendererIndex;
uint32_t MeshletIndex;
uint32_t bDoOcclusionTest;
};
// somewhere in my code..
// collect visible mesh shader instances for opaque objects
for (UHMeshRendererComponent* Renderer : OpaquesToRender)
{
const UHMesh* Mesh = Renderer->GetMesh();
const bool bOcclusionTest = bEnableHWOcclusionRT && ((int32_t)Mesh->GetIndicesCount() / 3) >= OcclusionThresholdRT;
// set the instance to the corresponding material and it's current rendering index
const uint32_t MatDataIndex = Renderer->GetMaterial()->GetBufferDataIndex();
const int32_t NewIndex = MeshShaderInstancesCounter[MatDataIndex]++;
// system will dispatch opaque renderer front-to-back for each material group
// but the group isn't sorted, so add the material data index to the list when first instance is occurred.
if (NewIndex == 0)
{
SortedMeshShaderGroupIndex.push_back(MatDataIndex);
}
UHMeshShaderData Data;
Data.RendererIndex = Renderer->GetBufferDataIndex();
Data.bDoOcclusionTest = bOcclusionTest ? 1 : 0;
bool bClearMotionDirty = false;
for (uint32_t MeshletIdx = 0; MeshletIdx < Mesh->GetMeshletCount(); MeshletIdx++)
{
Data.MeshletIndex = MeshletIdx;
VisibleMeshShaderData[MatDataIndex].push_back(Data);
// push to motion mesh shader data list if it's motion dirty
if (Renderer->IsMotionDirty(CurrentFrameGT))
{
MotionOpaqueMeshShaderData[MatDataIndex].push_back(Data);
bClearMotionDirty = true;
}
}
if (bClearMotionDirty)
{
Renderer->SetMotionDirty(false, CurrentFrameGT);
}
}
I haven't utilized the amplification shaders yet. So there are only mesh shaders at this point.
Let me share a piece of code from one of my mesh shader as an example:
// entry point for mesh shader
// each group should process all verts and prims of a meshlet, up to MESHSHADER_MAX_VERTEX & MESHSHADER_MAX_PRIMITIVE
[NumThreads(MESHSHADER_GROUP_SIZE, 1, 1)]
[OutputTopology("triangle")]
void DepthMS(
uint Gid : SV_GroupID,
uint GTid : SV_GroupThreadID,
out vertices DepthVertexOutput OutVerts[MESHSHADER_MAX_VERTEX],
out indices uint3 OutTris[MESHSHADER_MAX_PRIMITIVE]
)
{
// fetch data and set mesh outputs
UHMeshShaderData ShaderData = MeshShaderData[Gid];
UHRendererInstance InInstance = RendererInstances[ShaderData.RendererIndex];
UHMeshlet Meshlet = Meshlets[InInstance.MeshIndex][ShaderData.MeshletIndex];
SetMeshOutputCounts(Meshlet.VertexCount, Meshlet.PrimitiveCount);
// output triangles first
if (GTid < Meshlet.PrimitiveCount)
{
// output triangle indices in order, the vertex output below will get the correct unique vertex to output
// so I don't need to mess around here
OutTris[GTid] = uint3(GTid * 3 + 0, GTid * 3 + 1, GTid * 3 + 2);
}
// output vertrex next
if (GTid < Meshlet.VertexCount)
{
// convert local index to vertex index, and lookup the corresponding vertex
// it's like outputting the "IndicesData" in UHMesh class, which holds the unique vertex indices
uint VertexIndex = GetVertexIndex(IndicesBuffer[InInstance.MeshIndex], GTid + Meshlet.VertexOffset, InInstance.IndiceType);
// fetch vertex data and output
DepthVertexOutput Output = (DepthVertexOutput)0;
Output.Position.xyz = PositionBuffer[InInstance.MeshIndex][VertexIndex];
#if MASKED
Output.UV0 = UV0Buffer[InInstance.MeshIndex][VertexIndex];
#endif
// transformation
ObjectConstants Constant = RendererConstants[ShaderData.RendererIndex];
float3 WorldPos = mul(float4(Output.Position.xyz, 1.0f), Constant.GWorld).xyz;
float4x4 JitterMatrix = GetDistanceScaledJitterMatrix(length(WorldPos - GCameraPos));
Output.Position = mul(float4(WorldPos, 1.0f), GViewProj_NonJittered);
Output.Position = mul(Output.Position, JitterMatrix);
OutVerts[GTid] = Output;
}
}Based on the mesh shader spec.
- Max NumThreads() X x Y x Z can’t exceed than 128.
- Max vertices/indices output can’t exceed 256.
Implementation shall follow these limits.
I simply select 126 as my thread/vertices number, as it’s the closest multiple of 3 to 128. And 126 / 3 = 42 for the indices number.
At the beginning, it will fetch the shader data with SV_GroupID and then use the index to get further info of a renderer instance and the meshlet data it references.
Then, call the SetMeshOutputCounts() to setup the output counts. This is essential.
Runtime validation will raise an error for ouputting vertices/indices without setting this!
Next is to output vertices and indices. The output highly depends on your implementation (how you split a model and generate your meshlet) and can vary.
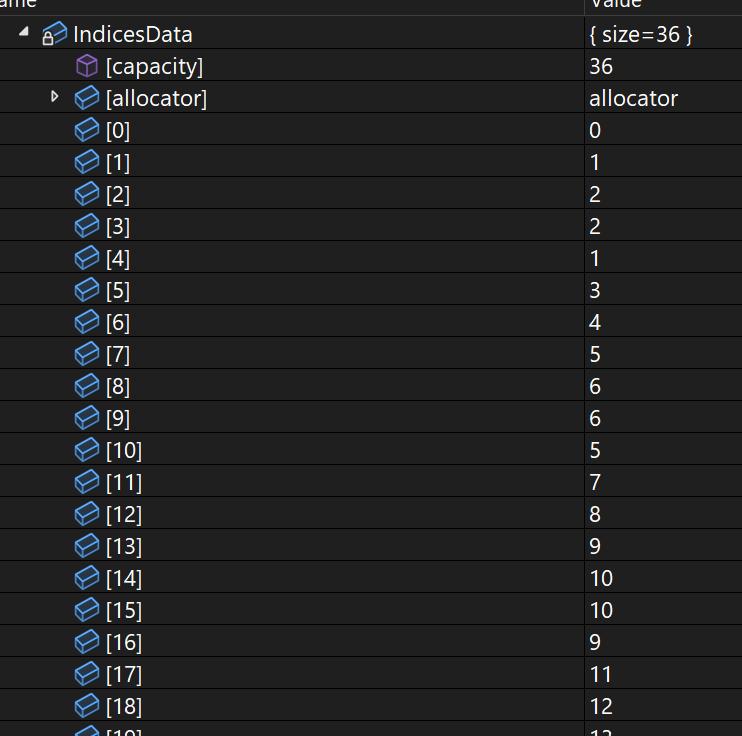
For indices, I simply output the number in order. First triangle will be 0,1,2, and the second be 3,4,5…to the end.
Because how I output my vertices below, I don’t need to make this too complicated.
For vertices, it will lookup the vertex index from my unique vertex indices buffer. Which is organized for rendering already.
This is why I don’t need to do anything special for indices output. One example of the mesh data:
Doing culling in mesh shader?
In my base opaque mesh shader, I did a check for occlusion result check and early return it (outdated, see note below):
// occlusion test check, not every objects have the occlusion test enabled, so need another bDoOcclusionTest flag to check
if (ShaderData.bDoOcclusionTest == 1 && OcclusionResult.Load(ShaderData.RendererIndex * 4) == 0)
{
SetMeshOutputCounts(0, 0); // must set output as 0 when doing early return
return;
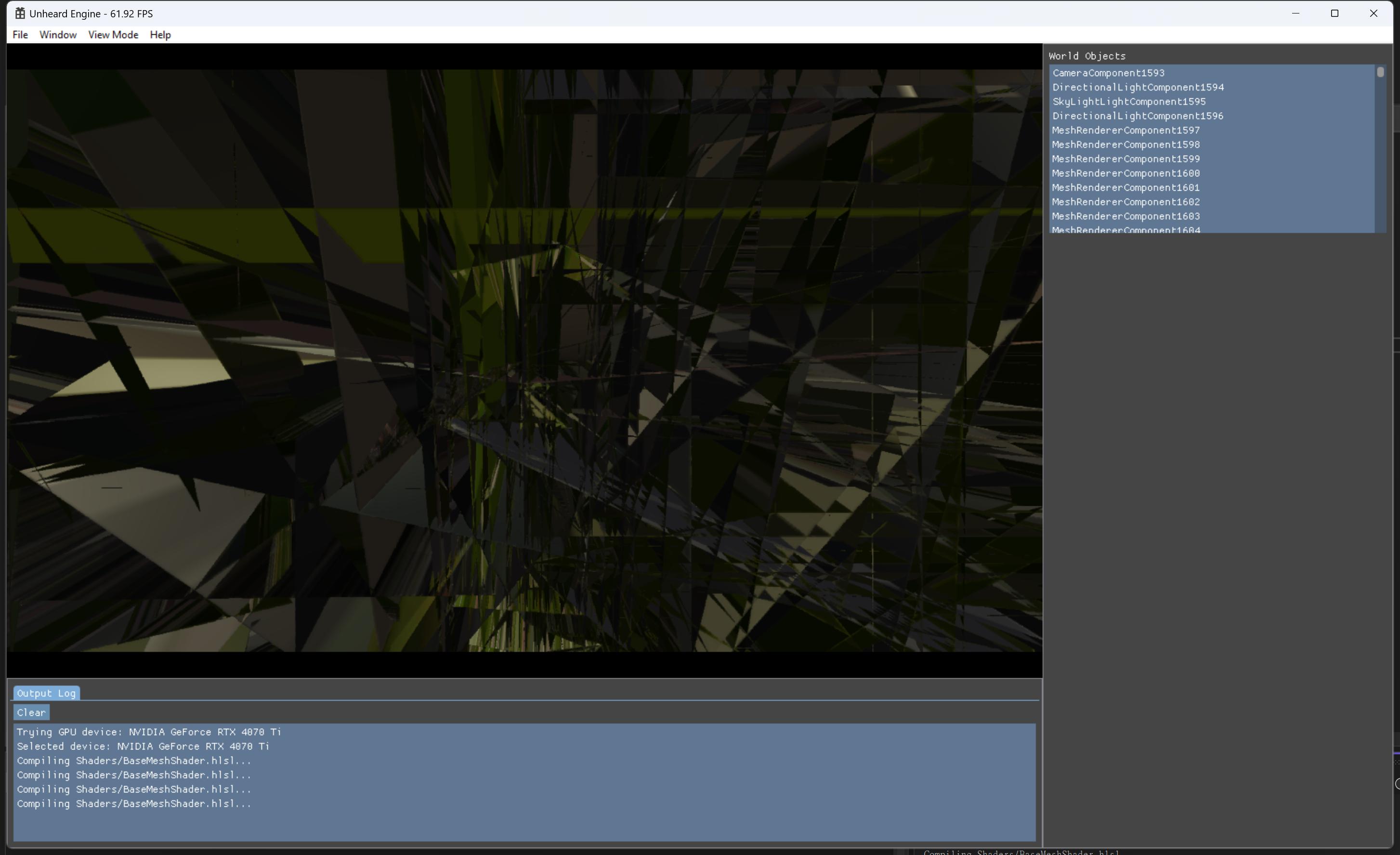
}This is the way if you’re culling anything in the mesh shader. Must ensure that the output count is set as 0, otherwise the behavior is undefined and cause visual glitches.
Or consider moving the culling to amplification shaders, and do not make a call of DispatchMesh() there if it's culled.
One example if I don't setup zero counts properly…BOOM!
Update on 26/11/2024
When I tested the mesh shader on AMD integrated graphics recently, I find previous early-return method causes TDR.
Moving the early return code AFTER indices output stops the TDR, see my latest BaseMeshShader.hlsl as a reference.
My theory is that AMD integrated graphics (or maybe AMD dedicated) can not accept 0 mesh output counts.
So I have to workaround manually if I want to early return in mesh shaders.
Front-to-back rendering?
The rasterization rule is FIFO, as mentioned in the mesh shader spec (See the Rasterization Order section in the reference link).
I sorted my instances in a material group on CPU side properly. Lowest SV_GroupID will fetch the closest instance, and the last for the farest.
Since the dispatch is per-material group not per-instance. The rendering order won't be as perfect as old methods.
But it can still benefit from the sorting for early-z culling.
for (size_t Idx = 0; Idx < SortedMeshShaderGroupIndex.size(); Idx++)
{
const int32_t GroupIndex = SortedMeshShaderGroupIndex[Idx];
const uint32_t VisibleMeshlets = static_cast<uint32_t>(VisibleMeshShaderData[GroupIndex].size());
if (VisibleMeshlets == 0)
{
continue;
}
const UHBaseMeshShader* BaseMS = BaseMeshShaders[GroupIndex].get();
GraphicInterface->BeginCmdDebug(RenderBuilder.GetCmdList(), "Dispatching base pass " + BaseMS->GetMaterialCache()->GetName());
RenderBuilder.BindGraphicState(BaseMS->GetState());
RenderBuilder.BindDescriptorSet(BaseMS->GetPipelineLayout(), BaseMS->GetDescriptorSet(CurrentFrameRT));
// Dispatch meshlets
RenderBuilder.DispatchMesh(VisibleMeshlets, 1, 1);
GraphicInterface->EndCmdDebug(RenderBuilder.GetCmdList());
}
Translucent instances?
No, I haven't applied this idea to translucent materials. As they currently need a strict back-to-front rendering order for proper outcomes.
Also my dispatch is material group based. Make translucent more difficult to fit this idea.
To further combine instances with different materials?
Alan Wake 2 remastered does something similar in their REAC conference talk and the results are good.
But my material is graph-based, and I must rewrite a huge, general purpose uber shader for this.
Even the shader/material part is fine, I have to consider different cull mode, blend mode…etc. I’ll revisit this afterward.
Summary
The mesh shader is just too good!
It removes the need for the IA binding and increases both the flexibility/performance of the geometry pipeline.
Though developers need to rework with their engine architecture, it's completely worth.
In my case it cuts the execution time as 1/10. I didn't even make these DispatchMesh() calls in parallel, which I'll do if the number of materials start growing.
IMO, mesh shader shall be the standard for the next gens.

Developer experience story about mesh shader is quite scarce to find, especially the potential errors like the count, so this is valuable to see. Thank you for sharing!