
Following up the previous post.
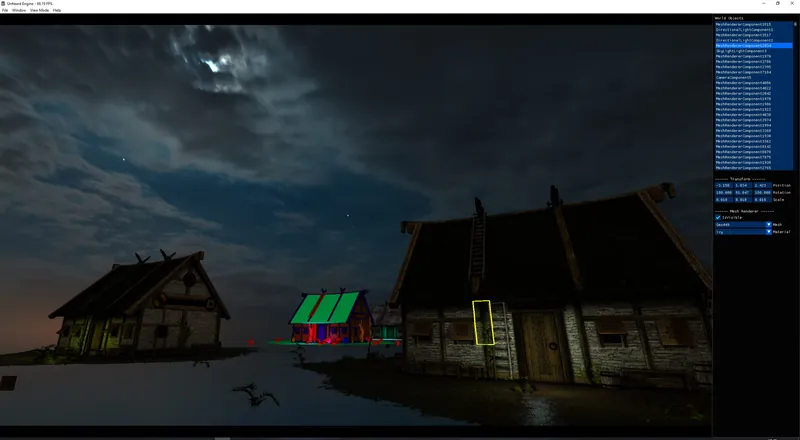
I added HDR image import, BC6H compression and cubemap tool this time. Also integrated the ImGui as current GUI solution.
To be honest, there are more refactoring and bugfixes in this sprint and only a few runtime features. But I think it's also important to review the code sometimes and refactor them at a certain point.
In case making the project as an incomprehensible pain.
*Disclaimer: This is just a personal practice of engine programming. Seeking something else if you're for game developing.
Git link: https://github.com/EasyJellySniper/Unheard-Engine
ImGui Integration
A popular GUI solution that can save developer lots of time. I believe many people are already familiar with it.
I choose their docking branch so a GUI window can be dragged outside the main app window. However, this branch doesn't exactly support win32 + Vulkan combination.
I won't blame them as this is a rare combo, but that's the setup I have for now. So I made some ImGui modification for my platform:
// BEGIN UHE MOD - add this line in ImGui_ImplWin32_InitPlatformInterface()
platform_io.Platform_CreateVkSurface = ImGui_ImplWin32_CreateVkSurface;
// END UHE MOD
// BEGIN UHE MOD - Adding win32-vulkan support
static int ImGui_ImplWin32_CreateVkSurface(ImGuiViewport* viewport, ImU64 vk_instance, const void* vk_allocator, ImU64* out_vk_surface)
{
VkWin32SurfaceCreateInfoKHR CreateInfo{};
CreateInfo.sType = VK_STRUCTURE_TYPE_WIN32_SURFACE_CREATE_INFO_KHR;
CreateInfo.hwnd = (HWND)viewport->PlatformHandleRaw;
CreateInfo.hinstance = GetModuleHandle(nullptr);
VkResult Err = vkCreateWin32SurfaceKHR((VkInstance)vk_instance, &CreateInfo, (const VkAllocationCallbacks*)vk_allocator, (VkSurfaceKHR*)out_vk_surface);
return (int)Err;
}
// END UHE MODThis at least makes ImGui work on my platform. I've also added other things like storing swap chain format & color space in struct ImGui_ImplVulkan_InitInfo.
So that Imgui initialization will follow my main app's swap chain format.
HDR Image Import
OpenEXR is introduced for the purpose. I would consider importing .hdr format as well, but .exr seems more popular as it's already an industry standard.
Following their read image sample I can easily get the 16-bit float data as input and use them afterward. Creating VkImage with VK_FORMAT_R16G16B16A16_SFLOAT.
I only noticed that some assets could have an infinite float value after import. I simply set those value with a valid max value and scale down all pixels if the max value in pixel exceeds a certain threshold value.
BC6H Compression
Another important change IMO. Here are some screenshots before and after BC6H compression:
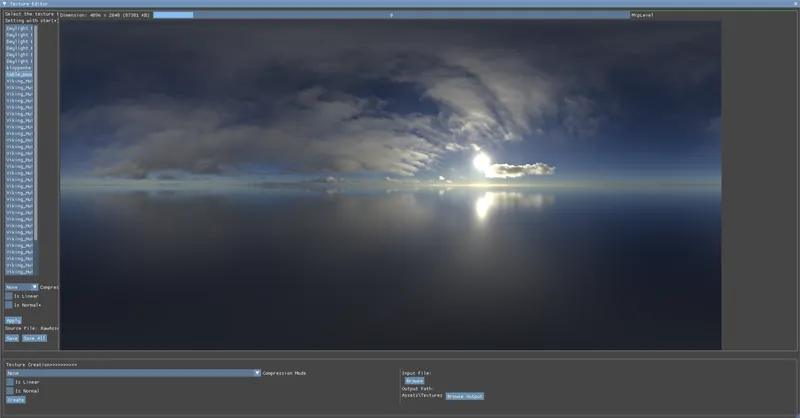
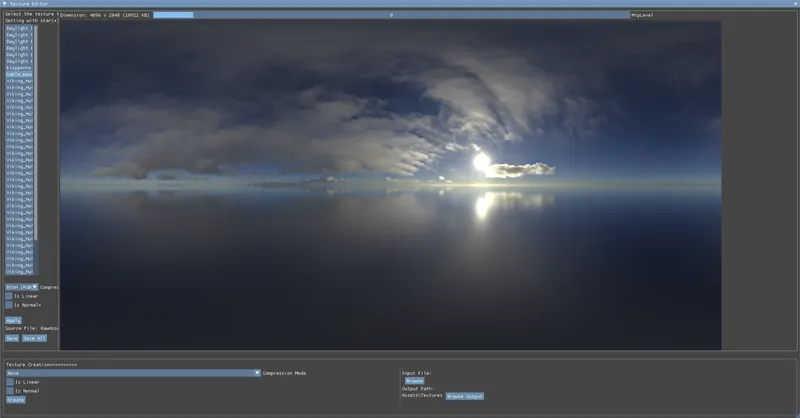
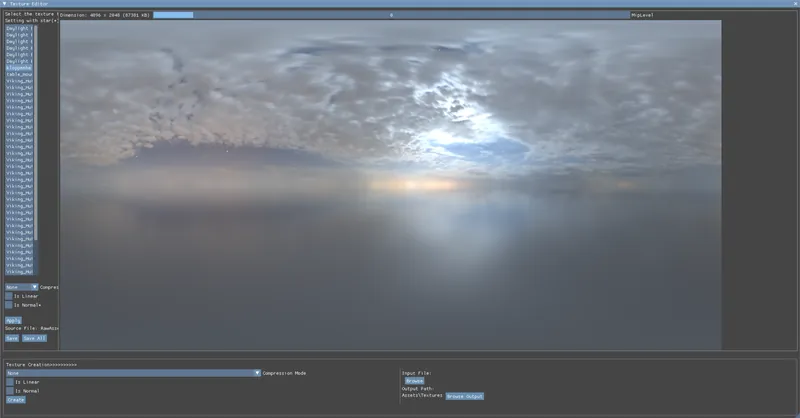
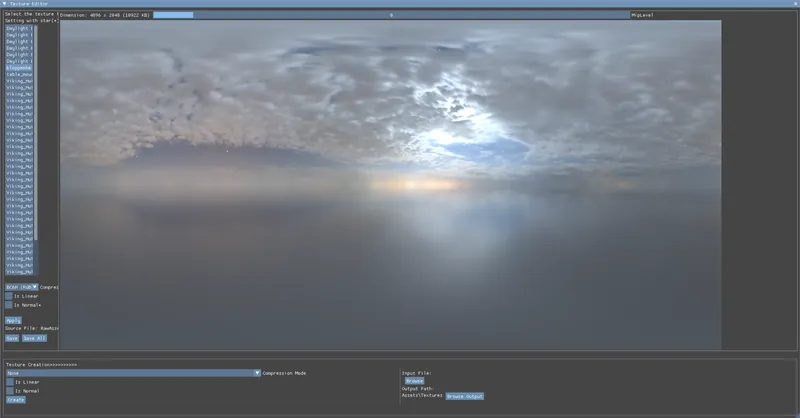
Sorry I didn't really find a way to make these info GIFs and keep the same image quailty. But they can be easily compared when opening in the new tabs.
The result after compression is almost ideal to the uncompressed one but saves 8X storage! This makes the cubamap applications afterward more effective as well.
The BC6H compression provides 14 different modes and therefore makes it a bit more complicated than BC1~BC5.

Looks scary isn't it? Mode 1 to mode 10 uses 4 reference points, and mode 11 to 14 uses 2 reference points. To keep simplicity, my method is a mixture of mode 11 to 14.
Let's start from the mode 11, I'd describe this mode as “HDR's BC1”. Since it simply store two refernce colors as 10 bits (RGB_W, RGB_X), and the GPU decoder will interpolate the result.
void GetBC6HPalette(const Imf::Rgba& Color0, const Imf::Rgba& Color1, float PaletteR[16], float PaletteG[16], float PaletteB[16])
{
const int32_t Weights[] = { 0, 4, 9, 13, 17, 21, 26, 30, 34, 38, 43, 47, 51, 55, 60, 64 };
const int32_t RefR0 = static_cast<int32_t>(Color0.r.bits());
const int32_t RefG0 = static_cast<int32_t>(Color0.g.bits());
const int32_t RefB0 = static_cast<int32_t>(Color0.b.bits());
const int32_t RefR1 = static_cast<int32_t>(Color1.r.bits());
const int32_t RefG1 = static_cast<int32_t>(Color1.g.bits());
const int32_t RefB1 = static_cast<int32_t>(Color1.b.bits());
// interpolate 16 values for comparison
for (int32_t Idx = 0; Idx < 16; Idx++)
{
const int32_t R = (RefR0 * (64 - Weights[Idx]) + RefR1 * Weights[Idx] + 32) >> 6;
const int32_t G = (RefG0 * (64 - Weights[Idx]) + RefG1 * Weights[Idx] + 32) >> 6;
const int32_t B = (RefB0 * (64 - Weights[Idx]) + RefB1 * Weights[Idx] + 32) >> 6;
Imf::Rgba Temp;
Temp.r = static_cast<uint16_t>(R);
Temp.g = static_cast<uint16_t>(G);
Temp.b = static_cast<uint16_t>(B);
PaletteR[Idx] = Temp.r;
PaletteG[Idx] = Temp.g;
PaletteB[Idx] = Temp.b;
}
}
// BC6H references:
// https://learn.microsoft.com/en-us/windows/win32/direct3d11/bc6h-format
// https://github.com/microsoft/DirectXTex/blob/main/DirectXTex/BC6HBC7.cpp
// Color0 and Color1 might be swapped during the process
uint64_t EvaluateBC6H(const Imf::Rgba BlockColors[16], Imf::Rgba& Color0, Imf::Rgba& Color1, float& OutMinDiff)
{
// setup palette for BC6H
float PaletteR[16];
float PaletteG[16];
float PaletteB[16];
GetBC6HPalette(Color0, Color1, PaletteR, PaletteG, PaletteB);
OutMinDiff = 0;
int32_t BitShiftStart = 0;
uint64_t Indices = 0;
for (uint32_t Idx = 0; Idx < 16;)
{
const int32_t R = static_cast<int32_t>(BlockColors[Idx].r.bits());
const int32_t G = static_cast<int32_t>(BlockColors[Idx].g.bits());
const int32_t B = static_cast<int32_t>(BlockColors[Idx].b.bits());
Imf::Rgba Temp;
Temp.r = static_cast<uint16_t>(R);
Temp.g = static_cast<uint16_t>(G);
Temp.b = static_cast<uint16_t>(B);
float BlockR = Temp.r;
float BlockG = Temp.g;
float BlockB = Temp.b;
float MinDiff = std::numeric_limits<float>::max();
uint64_t ClosestIdx = 0;
for (uint32_t Jdx = 0; Jdx < 16; Jdx++)
{
const float Diff = sqrtf((float)(BlockR - PaletteR[Jdx]) * (float)(BlockR - PaletteR[Jdx])
+ (float)(BlockG - PaletteG[Jdx]) * (float)(BlockG - PaletteG[Jdx])
+ (float)(BlockB - PaletteB[Jdx]) * (float)(BlockB - PaletteB[Jdx]));
if (Diff < MinDiff)
{
MinDiff = Diff;
ClosestIdx = Jdx;
}
}
// since the MSB of the first index will be discarded, if closest index for the first is larger than 3-bit range
// swap the reference color and search again
if (ClosestIdx > 7 && Idx == 0)
{
Imf::Rgba Temp = Color0;
Color0 = Color1;
Color1 = Temp;
GetBC6HPalette(Color0, Color1, PaletteR, PaletteG, PaletteB);
continue;
}
OutMinDiff += MinDiff;
Indices |= ClosestIdx << BitShiftStart;
BitShiftStart += (Idx == 0) ? 3 : 4;
Idx++;
}
return Indices;
}The code above is the core of BC6H evaluation. Basically it's checking the closest distance between a color pair in a 4x4 block and the 16 interpolated value used in decoder.
I only had a look in DirectXTex and tried to see how exactly the decoding is done. Because I was confused at the beginning: Mode 5 bits + RGB 60 bits = 65 bits, remaining 63 bits.
If each index uses 4 bits, how could 63 bits fit it? Then I realized the first index only uses 3 bits in the data layout. So the first index can never be bigger than 7. If that happens, I need to swap the reference color value and evaluate again. This gurantees the first index has a valid index.
The EvaluateBC6H will be called mutiple times and my system will choose the result that has the minimal total difference as like my BC1~BC5 do. However there is a problem of mode 11:

The color banding is too obvious with only mode 11 compression. Not surprised as it's a 16-to-10 bit conversion. Some data must've lost. But I'm not satisfied with that so I combine compression with mode 12~14.
The mode 12~14 do not store the two reference colors anymore. Instead, they store a color and a delta vector. The decoder will simply get the second reference color by (Color 0 + Vector) addition.
This provides a possible to store reference color in higher precision. But with a limit size of the delta vector.
- Mode 14: Color 16 bits + Vector 4 bits
- Mode 13: Color 12 bits + Vector 8 bits
- Mode 12: Color 11 bits + Vector 9 bits
bool StoreBC6HMode13(const Imf::Rgba& Color0, const Imf::Rgba& Color1, uint64_t Indices, UHColorBC6H& OutResult)
{
// the first endpoint and the delta
// 12 bits for the endpoint and 8 bits for the delta
uint64_t RW = UnquantizeFromNBit(QuantizeAsNBit(Color0.r.bits(), 12), 12) >> 4;
uint64_t GW = UnquantizeFromNBit(QuantizeAsNBit(Color0.g.bits(), 12), 12) >> 4;
uint64_t BW = UnquantizeFromNBit(QuantizeAsNBit(Color0.b.bits(), 12), 12) >> 4;
int32_t RX = UnquantizeFromNBit(QuantizeAsNBit(Color1.r.bits() - Color0.r.bits(), 12), 12) >> 4;
int32_t GX = UnquantizeFromNBit(QuantizeAsNBit(Color1.g.bits() - Color0.g.bits(), 12), 12) >> 4;
int32_t BX = UnquantizeFromNBit(QuantizeAsNBit(Color1.b.bits() - Color0.b.bits(), 12), 12) >> 4;
if (!(RX >= -128 && RX < 127
&& GX >= -128 && GX < 127
&& BX >= -128 && BX < 127))
{
return false;
}
// .............. skpped - do the Mode 13 output .............. //
return true;
}
// conditionally select the BC6H mode, they will be evaluate in the funciton, this piece is called in BlockCompressionHDR()
if (StoreBC6HMode14(Color0, Color1, Indices, Result)) { }
else if (StoreBC6HMode13(Color0, Color1, Indices, Result)) { }
else if (StoreBC6HMode12(Color0, Color1, Indices, Result)) { }
else
{
Result = StoreBC6HMode11(Color0, Color1, Indices);
}Let me use the mode 13 as an example, it will check if the color delta is within the 8 bits value range. If not, the color difference is too much for this mode and it will return false, proceed to the next mode.
It's also important to check the delta with the proper color precision, so I quantize/unquantize those values to keep the consistency with hardward implementation.
Each block will now select the best mode for it. That's the power of BC6H! The drawback is that it's much slower than BC1 ~ BC5, given each 4x4 block needs to compare with 16 interpolated colors!
I'll probably move the implementation to the compute shader in the future. All details are in TextureCompressor.cpp.
(Update: I've moved implementation to BlockCompressionNewShader.hlsl)
Cubemap Editing
The next thing to mention is the cubemap creation. It can either be created from six 2D slices or a panorama map for now. The input will eventaully be converted to a cubemap and can be compressed.
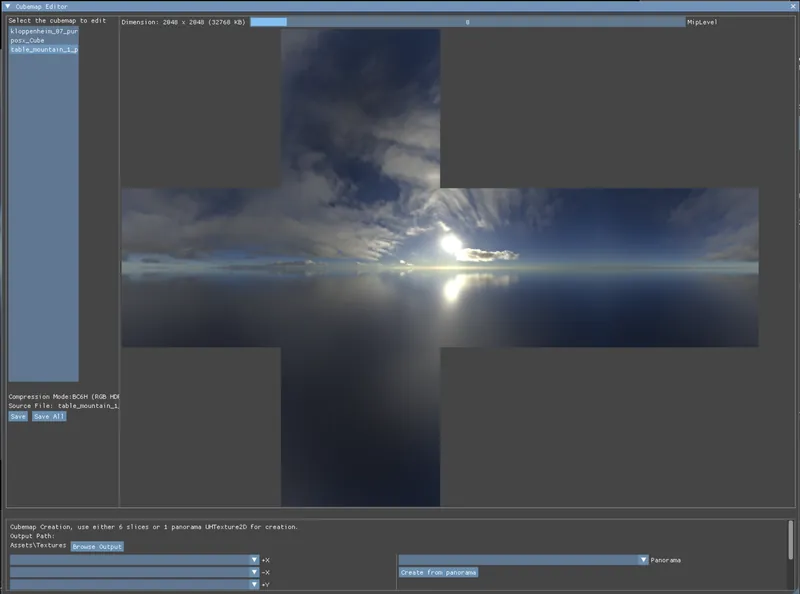
So the key is panorama to cubemap conversion. Given the spherical coordinate system formula based on ISO 80000-2:2019 standard:
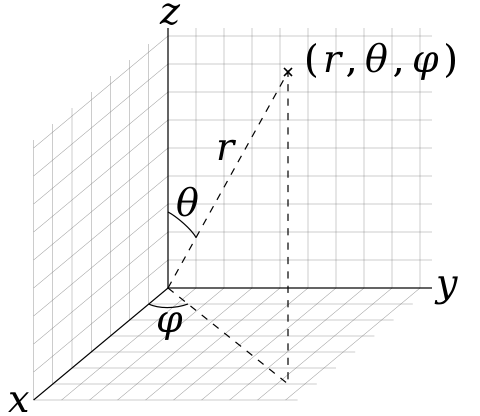
x = sin(theta * v) * cos(phi * u)
y = sin(theta * v) * sin(phi * u)
z = cos(theta * v)
theta = PI, and phi = PIWhen converting UV to panorama map, you apply the formula above and get a 3D sphere position. Then call the texCube() or TextureCube.Sample() function in the shader.
So to converting from panorama back to each cubemap face I need to :
- Rasterize a fullscreen quad as usual, set output target as individual 2D slice.
- Convert the quad UV to sphere position.
- Solve the equation above with the given sphere position, and get the UV for the input texture.
// convert UV to xyz and back,
void ConvertUVtoXYZ(float2 UV, out float3 Pos, int Index)
{
// .... convert uv to xyz following https://en.wikipedia.org/wiki/Cube_mapping .... //
}
float2 ConvertSpherePosToUV(float3 SpherePos, int Index, float2 QuadUV)
{
float Theta = UH_PI;
float Phi = UH_PI * 2.0f;
// flip the position to the (ISO 80000-2:2019) definition
float3 Pos;
Pos.x = -SpherePos.z;
Pos.y = SpherePos.x;
Pos.z = SpherePos.y;
Pos = normalize(Pos);
// so given a sphere pos, I just need to solve the equation above to get the UV
float2 UV = 0;
if (Index < 2)
{
UV.y = acos(Pos.z) / Theta;
UV.x = acos(Pos.x / sin(Theta * UV.y)) / Phi;
}
else if (Index < 4)
{
UV.y = acos(Pos.z) / Theta;
float Val = Pos.x / sin(Theta * UV.y);
// be careful for UV.x since it could go singularity, clamp the value between[-1,1]
Val = clamp(Val, -1.0f, 1.0f);
UV.x = acos(Val) / Phi;
if (QuadUV.x < 0.5f)
{
UV.x = 1.0f - UV.x;
}
}
else
{
UV.y = acos(Pos.z) / Theta;
UV.x = asin(Pos.y / sin(Theta * UV.y)) / Phi;
}
// flip to proper direction, following the sign in ConvertUVtoXYZ()
if (Index == 0 || Index == 5)
{
UV.x = 1.0f - UV.x;
}
// assume input width & height ratio is 2:1, adjust the U for face -Y+Y+Z
if (Index >= 2 && Index <= 4)
{
UV.x += 0.5f;
}
return UV;
}
// almost the same as the post process output, but add the selection of render target index
Panorama2CubemapOutput PanoramaToCubemapVS(uint Vid : SV_VertexID)
{
Panorama2CubemapOutput Vout;
Vout.UV = GTexCoords[Vid];
Vout.Position = float4(2.0f * Vout.UV.x - 1.0f, 2.0f * Vout.UV.y - 1.0f, 1.0f, 1.0f);
return Vout;
}
float4 PanoramaToCubemapPS(Panorama2CubemapOutput Vin) : SV_Target
{
// inverse the UV.y for Y faces
if (GOutputFaceIndex != 2 && GOutputFaceIndex != 3)
{
Vin.UV.y = 1.0f - Vin.UV.y;
}
// the goal is to solve the "original UV" of InputTexture and sampling from it
// so the first thing to do is reconstruct the sphere pos based on the quad UV and the requested cube face
float3 SpherePos = 0;
ConvertUVtoXYZ(Vin.UV, SpherePos, GOutputFaceIndex);
// the second step, calculate the original uv with spherical formula
float2 UV = ConvertSpherePosToUV(SpherePos, GOutputFaceIndex, Vin.UV);
UV = fmod(UV, 1.0f);
return InputTexture.SampleLevel(LinearWrappedSampler, UV, 0);
}I skipped a few lines for variable defines, full code: PanoramaToCubemap.hlsl
It's pretty straight forward, just comes with a few corrections based on what I see in the result.
The [-1,1] clamping is important for solving the Y faces. As I find it has a chance to return NaN value and causes black line artifact in texture.

After a cubemap is ready, my system will gerenrate mipmaps for it and compress it when requested.
That's it! Enjoying the quailty of HDR but keeping the storage as low as possible. I'm happy with it now.
Low-end Hardware Test
This time, I've also tried to run my app on low-end hardware. For example, my integrated GPU (AMD Radeon(TM) Graphics).
Not surprisingly, there are a few issues:
- Do not support VK_KHR_present_id and VK_KHR_present_wait. Solved by wait the vkFence finished.
- Do not support 24-bit depth format. Solved by not using it.
- Wrong VkDescriptorPoolSize info when creating a vkDescriptorPool. Solved by setting [descriptorCount * MaxFrameInFlight] instead [MaxFrameInFlight] only.
- Easily running out of VRAM for images. Solved by using host memory when device heap isn't available.
- If a secondary command buffer is used, then the first vkBeginRenderPass() call afterward that is with LOAD_OP_LOAD flag seems to malfunction and the render target will still get cleared!
And validation layer doesn't complain anything about this at all.
The last issue is very subtle and only happens with my integrated GPU, and works fine with 4070 TI. I would probably make a minimal Vulkan project, reproduce it and report to Khrono team. (Driver is already the latest)
The descriptor pool issue also shows how automatic it is in mid-high end GPU and we dont need to set the count exact the same as our VkDescriptorSetLayoutBinding. But I should set the right count as a good practice from now on!
(Surprsingly, ray tracing does work lol.)
After the fixes above, it works on the integrate GPU now.

Just with a lower FPS and a constant 100% usage lol.
Summary
That's it!
As for the next sprint, it's still more editor works. I think it's also time to add scene save/load feature.
Also more interesting runtime rendering features.