Download the Source Code "
Watch the Video "
[size="5"]Introduction
Efficient antialiasing techniques are an important tool of high-quality, real-time rendering. MSAA (Multisample Antialiasing) is the standard technique in use today, but comes with some serious disadvantages:
- Incompatibility with deferred lighting, which is used more and more in real-time rendering;
- High memory and processing cost, which makes its use prohibitive on some widely available platforms (such as the Sony Playstation* PS3* [Perthuis 2010]). This cost is also directly linked to the complexity of the scene rendered;
- Inability to smooth non-geometric edges unless used in conjunction with alpha to coverage.A new technique developed by Intel Labs called Morphological Antialiasing (MLAA) [Reshetov 2009] addresses these limitations. MLAA is an image-based, post-process filtering technique which identifies discontinuity patterns and blends colors in the neighborhood of these patterns to perform effective antialiasing. It is the precursor of a new generation of real-time antialiasing techniques that rival MSAA [Jimenez et al., 2011] [SIGGRAPH 2011].
This sample is based on the original, CPU-based MLAA implementation provided by Reshetov, with improvements to greatly increase performance. The improvements are:- Integration of a new, efficient, easy-to-use tasking system implemented on top of Intel(R) Threading Building Blocks (Intel(R) TBB).
- Integration of a new, efficient, easy to use pipelining system for CPU onloading of graphics tasks.
- Improvement of data access patterns through a new transposing pass.
- Increased use of Intel(R) SSE instructions to optimize discontinuities detection and color blending.
[size="5"]The MLAA algorithm
In this section we present an overview of how the MLAA algorithm works; cf. [Reshetov 2009] for the fully detailed explanation. Conceptually, MLAA processes the image buffer in three steps:- Find discontinuities between pixels in a given image.
- Identify U-shaped, Z-shaped, L-shaped patterns.
- Blend colors in the neighborhood of these patterns.
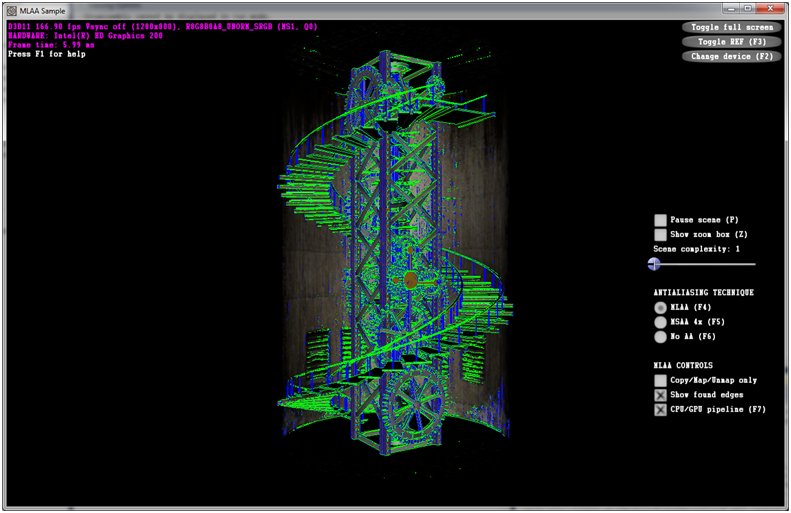
The first step (find discontinuities) is implemented by comparing each pixel to its neighbors. Horizontal discontinuities are identified by comparing a pixel to its bottom neighbor, and vertical discontinuities by comparing with the neighbor on the right. In our implementation we compare color values, but any other approach that suits the application's specificities is perfectly valid. - Pause Scene toggles the scene's animations on/off;
- Show zoom box toggles the zoom box feature on/off, which allows the user to take a closer look at a pixel area to better compare the antialiasing techniques. The area of interest can be changed by right-clicking to the new area to examine;
- Scene complexity simulates the effect of increasing scene complexity by using overdraw. The value (between 1 and 100, adjusted by the slider) indicates how many times the scene is rendered per frame (with overdraw).The second block selects which antialiasing technique to apply: MLAA, MSAA (4x) or no antialiasing. This is of course to allow comparison of the techniques' performance and quality (the default choice is "MLAA");
The last block of controls is only available if the antialiasing technique used is MLAA, and controls how the algorithm should be run:- Copy/Map/Unmap only copies the color buffer from GPU memory to CPU memory and back, but won't perform any MLAA processing between the two copy operations. This allows measurement of the impact of the copy operations on the overall performance of the entire algorithm;
- CPU tasks pipelining turns the pipelining system on/off for CPU onloading of graphics tasks (the default is on) so that it is easy to see the benefit of pipelining;
- Show found edges runs the first part of the algorithm (find discontinuities between pixels), but the blending passes are replaced by a debug pass, where a pixel is:
- changed to solid green if a horizontal discontinuity has been found with its neighbor;
- to solid blue if a vertical discontinuity has been found with its neighbor;
- changed to solid red if both horizontal and vertical discontinuities have been found with its neighbors;
- unchanged if no discontinuities have been found.
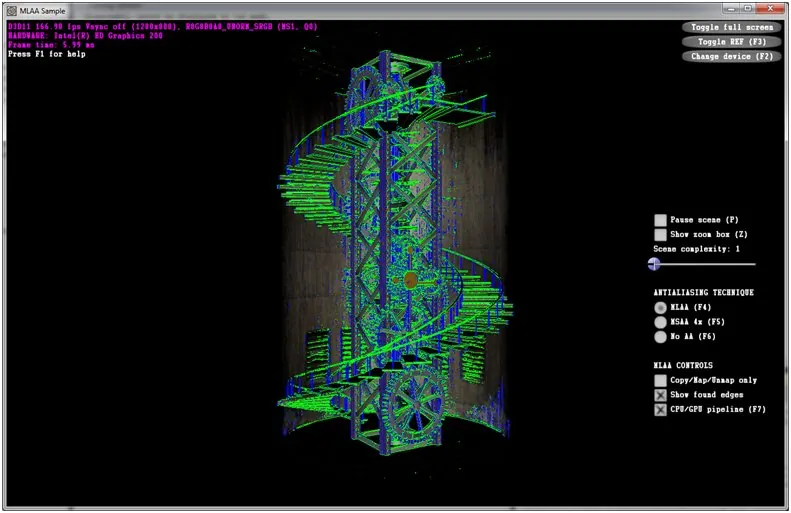
Figure 4. Gear tower scene with MLAA and the "show found edges" option enabled[size="5"]Sample Architecture
Without the pipelining optimizations, the sequence of events for each frame is:
ANIMATE AND RENDER TEST SCENE
MLAA STAGE (if MLAA is enabled)
[bquote]Copy the color buffer where the scene was rendered to a staging buffer
Map the staging buffer for CPU-side access.
MLAA post-processing (the staging buffer is both input and output)
Unmap the staging buffer
Copy staging buffer back to the GPU-side color buffer
Render the zoombox (if applicable)[/bquote]RENDER THE SAMPLE's UI, PRESENT FRAME
Except for the "Perform the MLAA post-processing work" step (and again not considering the pipeline for now), all of these steps are implemented using standard Microsoft DirectX* methods.
[size="5"]The Tasking API
By nature the MLAA algorithm is easy to parallelize. For both the discontinuities detection and blending passes, we can process the color buffer in independent chunks (blocks of contiguous rows or columns). MLAA can be implemented using a task-based solution that automatically makes full use of all available CPU cores, while keeping the code core count agnostic
This sample uses a simple C-based tasking API that is implemented on top of the Intel(R) Threading Building Blocks (Intel(R) TBB) scheduler. This wrapper API was created to simplify the integration of the technique into existing codebases which already expose a similar tasking API (e.g. cross-platform game engines). An added benefit is the increased readability of the main source file MLAA.cpp.
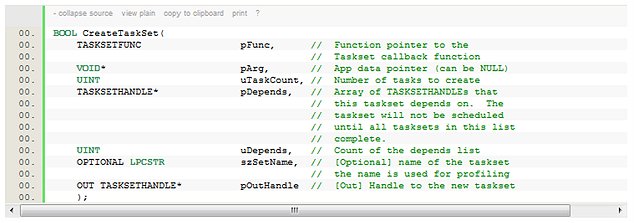
The two important functions of the wrapper APIs are:
And: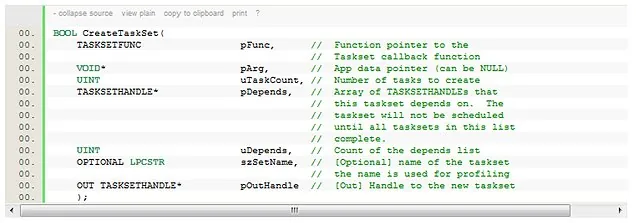

The callback function has the following signature:

.MLAA requires a dependency graph of three consecutive tasksets:
- The first taskset finds the discontinuities between pixels in the color buffer;
- The second taskset performs the horizontal blending pass, and depends on the completion of the first taskset for the discontinuities information;
- The third taskset performs the vertical blending pass, which depends on the completion of the first taskset for the discontinuities information, but also on the completion of the second taskset because of the transpose optimization (cf. corresponding section for details).This dependency graph is expressed in MLAA.cpp as a sequence of three calls to [font="Courier New"]CreateTaskSet;[/font] the taskset callback functions (implemented in MLAAPostProcess.cpp) being respectively [font="Courier New"]MLAAFindDiscontinuitiesTask[/font], [font="Courier New"]MLAABlendHTask[/font], [font="Courier New"]MLAABlendVTask[/font].
If pipelining is not enabled, we wait for the last taskset to complete by calling [font="Courier New"]WaitForSet[/font] with the handle of the last taskset. When the call returns, the MLAA work for the frame is complete. Things are just a little bit more complicated when using the pipeline.
[size="5"]The CPU/GPU pipeline
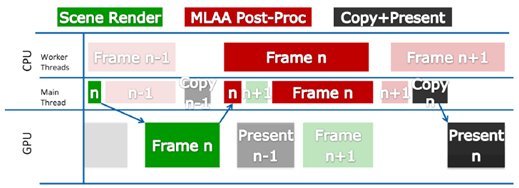
To get the maximum performance from our implementation, we have to keep both CPU and GPU sides fully utilized. Due to the data dependencies between the tasksets, full utilization can be achieved by interleaving the processing of multiple frames, as shown in the diagram below: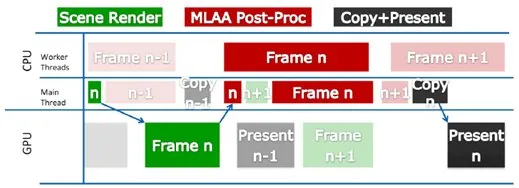
Figure 5: Frames moving through the pipeline. The red blocks on the CPU main thread timeline illustrate that the main thread
will take MLAA work if the application gets CPU-bound.In other words, we have to build a pipelining system, where a pipeline is a sequence of CPU stages (workloads) and GPU stages, and able to run multiple instances of said pipeline at the same time.
In our case, each instance of the pipeline corresponds to the processing of one frame. We have three steps:
Step 1 (GPU stage):- Animate and render test scene;
- Copy color buffer to staging buffer (using asynchronous GPU-side CopyResource).Step 2 (CPU stage):
- Map the staging buffer;
- Perform the MLAA post-processing work (staging buffer is both input and output).Step 3 (GPU stage):
- Unmap staging buffer and copy it back to the GPU-side color buffer;
- Finish frame rendering (zoombox, UI) and present.To implement this concept, we designed a simple Pipeline class. Each stage is represented by a [font="Courier New"]PipelineFunction[/font] structure that specifies the function to be called, and the stage type. The callback function must have the following signature:

Where [font="Courier New"]uInstance[/font] indicates which instance of the pipeline the function is being called from. A GPU stage uses a DirectX* query (of type [font="Courier New"]D3D11_QUERY_EVENT[/font]) to signal its completion, but a CPU stage has to explicitly call the Pipeline's class [font="Courier New"]CompleteCPUWait[/font] method to signal completion:

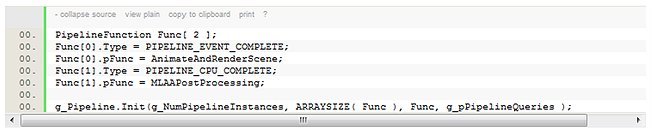
Creating the pipeline instances requires a single call to the Init method. In our case, the code is:
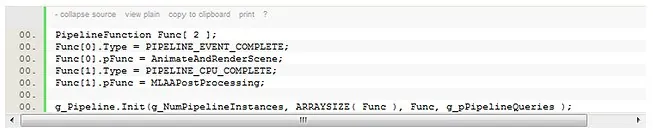
Where g_NumPipelineInstances is the number of pipeline instances to create (3 in this case).
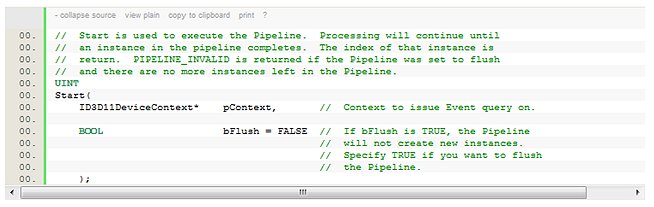
To run the pipelines, we call the [font="Courier New"]Start[/font] method each frame: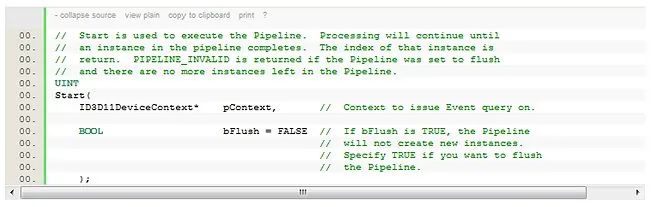
Because the [font="Courier New"]Start[/font] method returns the index of a completed instance of the pipeline, the third and last step doesn't have to be called through the [font="Courier New"]Pipeline[/font] class. The code of the last step executes right after the call to the [font="Courier New"]Start[/font] method, indexing the data structures with the index returned by [font="Courier New"]Start[/font].
Pipelining does not rely on the tasking API [font="Courier New"]WaitForSet[/font] call, since it is blocking and so does not allow pipelining to occur. The solution is to use a completion taskset--that is, a task that depends on the completion of all the MLAA tasks, and whose only work will be to call the [font="Courier New"]CompleteCPUWait[/font] method.
[size="5"]Intel(R) SSE optimizations
The first pass of the MLAA algorithm identifies discontinuities between pixels. Conceptually, each pixel checks its color and compares it with its bottom neighbor (when looking for horizontal discontinuities) or right neighbor (when looking for vertical discontinuities) [Reshetov09, section 2.2.1].
In this sample, we have kept the simple discontinuity detection kernel of the reference implementation. A discontinuity exists between two pixels if at least one of their RGB color components differs by at least 16 (on the 0-255 scale of the RGBA8 format).
This definition works well in the sample and allows a very compact and efficient SIMD implementation. However, more complex approaches are possible, and sometimes necessary, to get the best possible results. For example, a pixel's luminance could be used instead of directly comparing color values, and a variable threshold recomputed each frame to take into account the scene's overall luminance and contrast [Luminance]. Depth values could be used to assist with edge detection or any kind of custom data to exclude specific zones of the color buffer from being processed.
Because this step is independent from the rest of the algorithm, and we are running on the CPU, any data from the program can be used directly as input data. The only limits to the detection algorithm are:- The fact that the algorithm must output a bit for each pixel indicating whether a discontinuity is detected;
- The tradeoff between performance and quality/complexity;
- The programmer's imagination.As with the original reference implementation [Reshetov09, section 2.4], we work with a RGBA8 render target format and the "vertical discontinuity" and "horizontal discontinuity" bit flags computed by MLAA are stored in-place in the two high bits of the pixel data (i.e., the two high bits of the alpha component which is unaffected by the MLAA blending operations). This keeps the implementation simple while helping with memory footprint, and allowing optimizations in the next steps of the algorithms (cf. "the transposing optimization" section below).
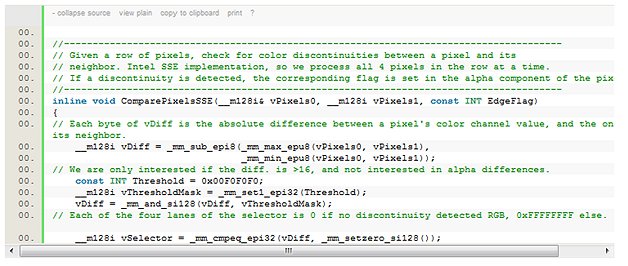
Because each pixel is 32 bits of data, and each pixel can be processed independently of the others in this step, we can process 4 pixels at a time using Intel(R) SSE intrinsics. The detection code is very short.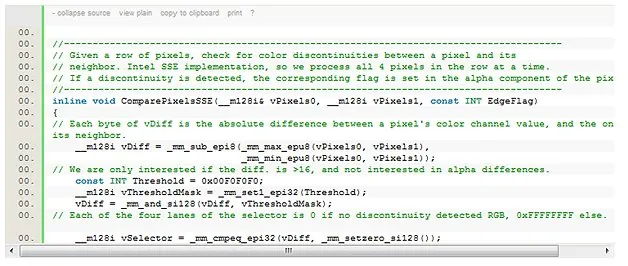
The reference implementation then proceeds to update the alpha component of each pixel, but used inefficient serial code to do so. We can optimize this sequence by using the following Intel(R) SSE code:

We also replaced the [font="Courier New"]MixColors[/font] function (which computes a linear interpolation of two colors) to use a full Intel(R) SSE implementation.
[size="5"]The Transposing Optimization
The next task of the algorithm is to find "discontinuity lines", i.e., sequences of consecutive pixels which are marked with the same discontinuity flag (horizontal flag for horizontal blending pass, vertical flag for vertical blending pass) while walking rows and columns of our color buffer [Reshetov09, section 2.1].
Because discontinuity lines tend to be short, intuition suggests (and profiling data confirms) that the most expensive part of this operation is scanning between discontinuity lines, i.e., scanning the large areas of consecutive pixels where no discontinuity flag is set.
The good news is that we can check 4 pixels at a time using the [font="Courier New"]_mm_movemask_ps[/font] Intel(R) SSE intrinsic when the following conditions are met:- We are scanning 4 pixels stored at consecutive addresses;
- The address of the first pixel is "Intel(R) SSE-aligned" (16 bytes alignment);
- The discontinuity flag is stored as the high bit of the 32 bits of pixel data.
During the horizontal blending pass, (1) is true (we scan horizontal rows of pixels in the color buffer represented as a 2D linear array of pixel data); (2) is true almost all the time (remember that 16 bytes alignment is equivalent to "the index of the starting pixel in the buffer is a multiple of 4" as the buffer is properly aligned); and (3) is true as we chose bit 31 to represent the horizontal discontinuity flag. - 0 (the most common case by far): no discontinuity flag set in this group of 4 pixels, move to the next group of 4 pixels.
- Bit 0 is set: discontinuity line starts at first pixel of the group.
- Bit 1 is set: discontinuity line starts at second pixel of the group.
- Bit 2 is set: discontinuity line starts at third pixel of the group.
- Bit 3 is set: discontinuity line starts at fourth pixel of the group.This optimization is part of the reference implementation and works well for the horizontal blending pass, but was impossible to apply for the vertical blending pass. As the code scans the buffer vertically, (1) is false (adjacent pixels in a column are not stored at consecutive addresses), and (3) is false as well (the vertical discontinuity flag is stored at bit 30 of the pixel data).
The problem with (3) is easy to work around by introducing a simple "shift left by one bit" operation if we are processing the vertical flags, transforming the code above to:
But (1) is still a problem. In addition, vertical scanning is extremely cache-unfriendly. Because of both of these issues, the vertical blending pass is about 3 times (300%!) as expensive as the horizontal blending pass in the reference implementation (as shown by profiling data).
Our solution to this issue is to make the vertical blending pass use the cache and Intel(R) SSE-friendly data access patterns of the horizontal blending pass by considering the color buffer as a matrix of pixels and transposing it between passes:- Perform horizontal blending pass
- Transpose the (horizontally blended) color buffer
- Perform vertical blending pass
- Transpose back color bufferThis way the code for both blending passes is exactly the same (which adds the advantage of simplicity/readability), the only difference being which flag to scan for, and we benefit from all the optimizations and cache-friendliness of the horizontal pass.
In practice, the transpose operations are not implemented as separate passes/tasksets, but as the last part of their respective blending pass. This allows us to benefit from the cache "warmness".
The two transpose operations are not free. The cost is the extra code execution time, one extra work buffer and a synchronization point between the horizontal and vertical passes (we must wait for all horizontal tasks to be done before we can start any of the vertical tasks, because we must wait for the color buffer to be fully transposed before starting the vertical pass work).
Even with these extra costs, the overall performance is significantly better than the previous approach. As expected, profiling data shows that both blending passes have equivalent performance.
[size="5"]Performance Results
MLAA performance was measured on the following two configurations:- Code name "Huron River" : Intel(R) Core(TM) i7-2820QM Processor (Intel(R) microarchitecture code name Sandy Bridge, 4 cores 8 threads @2.30 GHz) with GT2 processor graphics, 4 GB of RAM, Windows 7 Ultimate 64-bit Service Pack 1
- Code name "Kings Creek": Intel(R) Core(TM) i5-660 Processor (codename "Clarkdale", 2 cores 4 threads @ 3.33 Ghz), with GMA HD Graphics (codename "Ironlake"), 2 GB of RAM, Windows 7 Ultimate 64-bit Service Pack 1We measured the average frame rendering time of our sample as a function of scene complexity for the different antialiasing settings. We also measured the rendering time for the Copy/Map/Umap only mode to highlight the impact of the color buffer copy operations on the overall performance of the algorithm.
[size="5"]Results
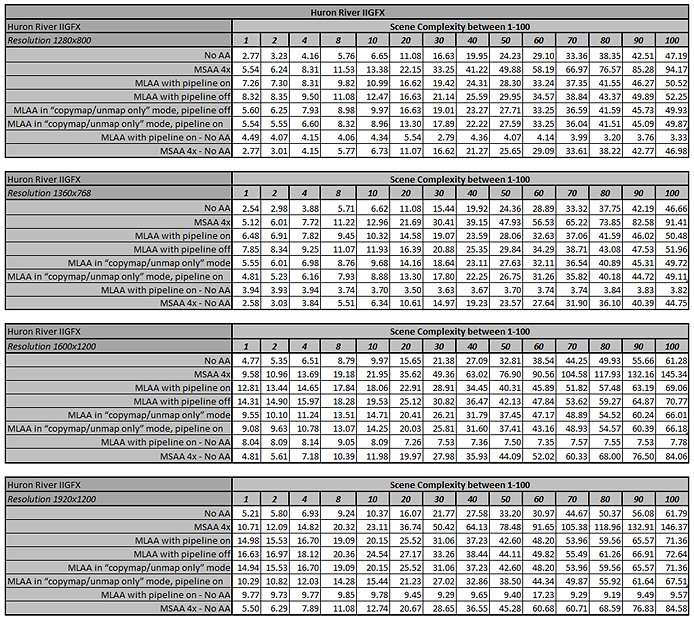
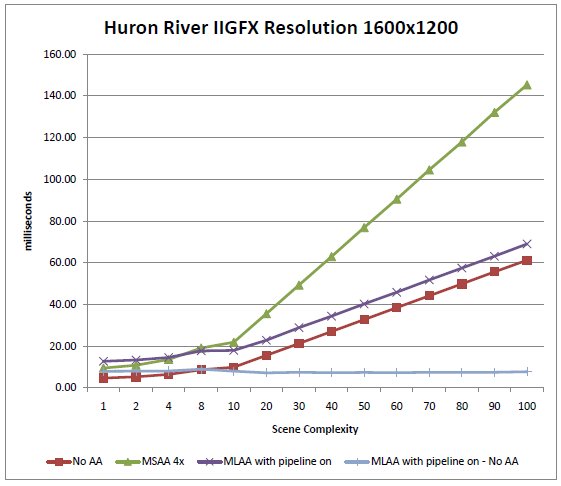
The data shows that for the Huron River machine, the extra cost of MSAA 4x goes up linearly with the scene complexity (in fact, for all resolutions, the frame time when using MSAA 4x to render our test scene appears to be approximately the double of the frame time when no antialiasing is used). In contrast, the cost of MLAA appears more or less constant (around 4 ms/frame at 1280x800). This is consistent with our expectations, as unlike MSAA 4x, MLAA is executed only once per frame, regardless of scene complexity / number of draw calls.
We also observe that except for very low complexity values (i.e. less than ~5) MLAA always outperforms MSAA 4x, regardless of resolution, and that the difference in performance grows with complexity (because as noted above, the cost of MSAA 4x grows linearly with complexity when the cost of MLAA does not).
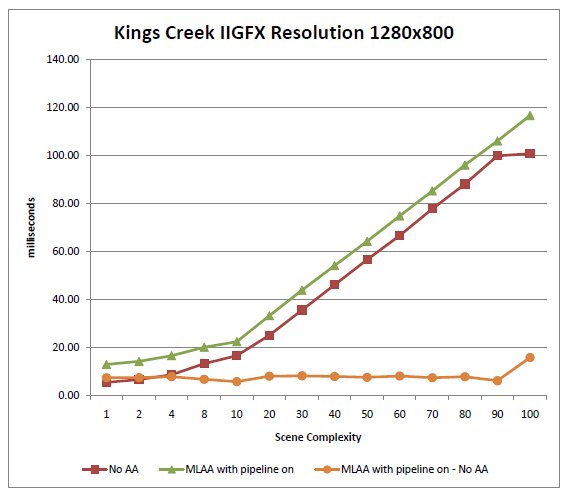
In the case of the Kings Creek machine, we can't compare the cost of MLAA vs. MSAA 4x as the latter is not provided by the Ironlake hardware. The goal is then to determine if MLAA allows us to provide software antialiasing as an alternative with acceptable performance. Our measurements at the 1280x800 resolution show that again the cost of MLAA is largely independent of scene complexity, and the average value is ~7.5 ms (discarding the outlier data point at complexity = 100).
Interestingly, if we compare this result to a hypothetical MSAA 4x implementation with approximately the same performance profile than the Huron River one (frame time with MSAA 4x ~ 2x frame time with no antialiasing), we notice that again MLAA would outperform MSAA 4x for almost all complexity values (=4 in this case).
Table 1. Rendering times of our test scene on the King's Creek machine.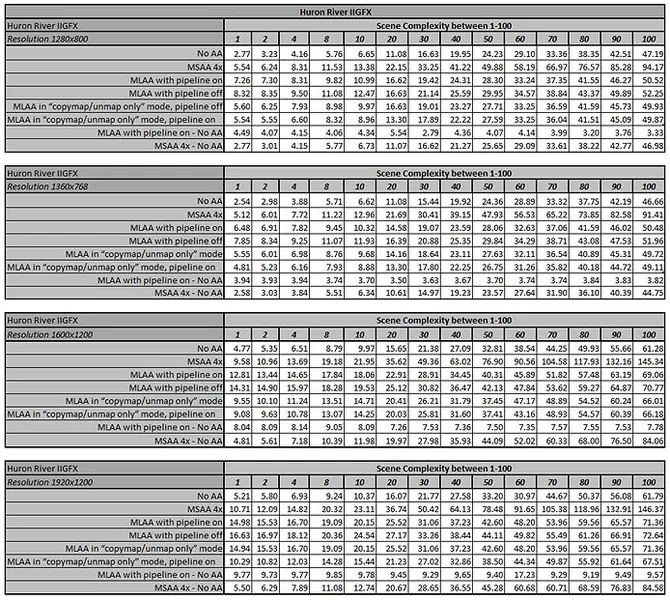
Table 2. Rendering times of our test scene on the Huron River machine.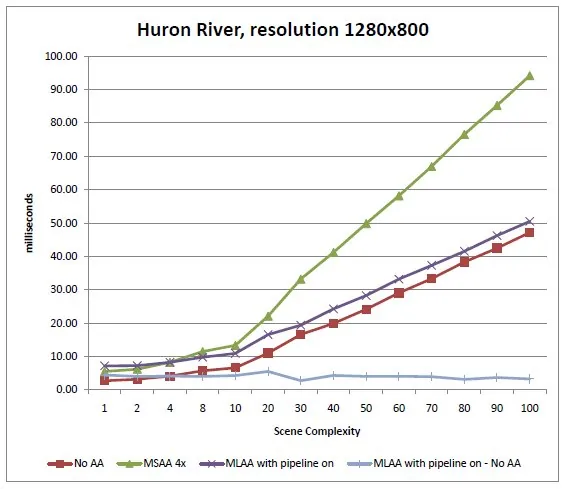
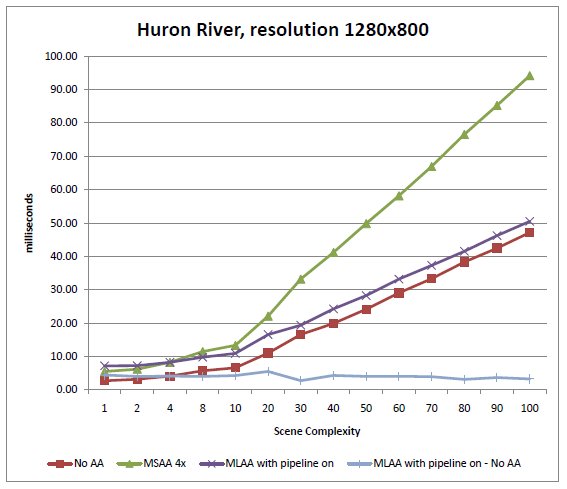
Figure 6: Rendering times of our test scene for each of the antialiasing techniques, as a function of scene complexity. The
bottom, flat curve is the difference between the "MLAA with pipeline on" curve, and the "No antialiasing" curve, measuring the
cost of using MLAA [Huron River, res. 1280x800]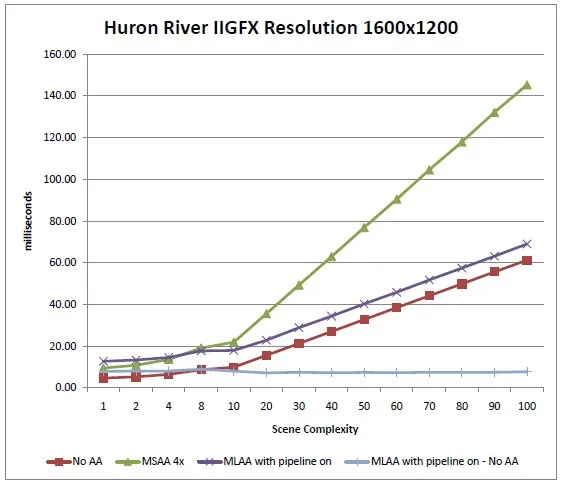
Figure 7: Rendering times of our test scene for each of the antialiasing techniques, as a function of scene complexity. The
bottom, flat curve is the difference between the "MLAA with pipeline on" curve, and the "No anti aliasing" curve, measuring the
cost of using MLAA [Huron River, res. 1600x1200]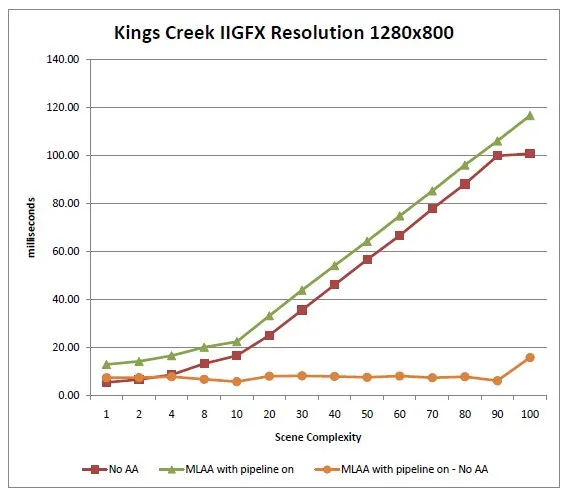
Figure 8: Rendering times of our test scene with MLAA on and off, as a function of scene complexity. The bottom, flat curve is
the difference between the "MLAA with pipeline on" curve, and the "No antialiasing" curve, measuring the cost of using MLAA
[Kings Creek, res. 1280x800][size="5"]References
[Reshetov 2009] RESHETOV, A. 2009. "Morphological Antialiasing"
[Perthuis 2010] PERTHUIS, C. 2010. MLAA in God of War 3. Sony Computer Entertainment America, PS3 Devcon, Santa Clara, July 2010.
[Jimenez et al., 2011] JIMENEZ, J., MASIA, B., ECHEVARRIA, J., NAVARRO, F. and GUTIERREZ, D. 2011. Practical Morphological Anti-Aliasing. In Wolfgang Engel, ed., GPU Pro 2. AK Peters Ltd.
[SIGGRAPH 2011] JIMENEZ, J., GUTIERREZ D., YANG, J., RESHETOV, A., DEMOREUILLE, P., BERGHOFF, T., PERTHUIS, C., YU, H., MCGUIRE, M., LOTTES, T., MALAN, H., PERSSON, E., ANDREEV, D. and SOUSA T. 2011. Filtering Approaches for Real-Time Anti-Aliasing. In ACM SIGGRAPH 2011 Courses.
[Luminance] Definition of luminance for CRT-like devices:
INTERNATIONAL COMMISSION ON ILLUMINATION. 1971. Recommendations on Uniform Color Spaces, Color Difference Equations, Psychometric Color Terms. Supplement No.2 to CIE publication No. 15 (E.-1.3.1), TC-1.3, 1971.
And for LCDs:
ITU-R Rec. BT.709-5. 2008. Page 18, items 1.3 and 1.4
If all conditions are true, we compute the flags:
And five outcomes are possible depending on the value of HFlags:
At the end of the first step, each pixel is marked with the horizontal discontinuity flag and/or the vertical discontinuity flag, if such discontinuities are detected. In the next step, we "walk" the marked pixels to identify discontinuity lines (sequences of consecutive pixels marked with the same discontinuity flag), and determine how they combine to form L-shaped patterns, as illustrated below:
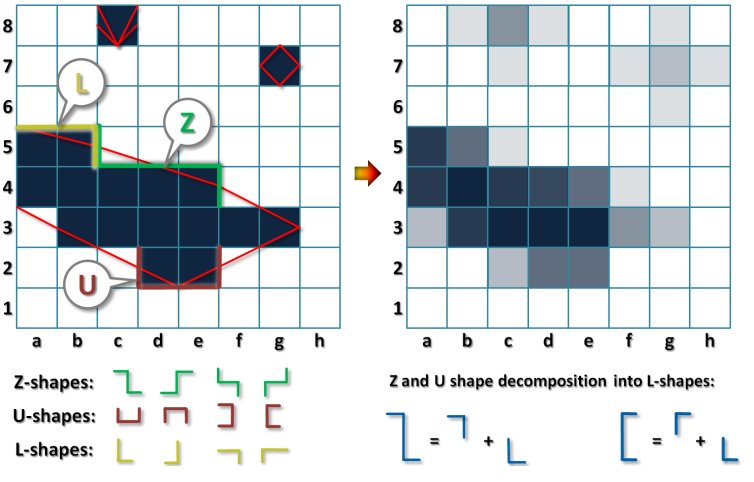
Figure 1: MLAA processing of an image, with Z, U, and L-shapes shown on the original image on the left
The third and final step is to perform blending for each of the identified L-shaped patterns.
The general idea is to connect the middle point of the primary segment of the L-shape (horizontal green line in the figure below) to the middle point of the secondary segment (vertical green line--the connection line is in red). The connection line splits each pixel into two trapezoids; for each pixel the area of the corresponding trapezoid determines the blending weights. For example, in the figure below, we see that the trapezoid's area for pixel c5 is 1/3; so the new color of c5 will be computed as 2/3 * (color of c5) + 1/3 * (color of c5's bottom neighbor).
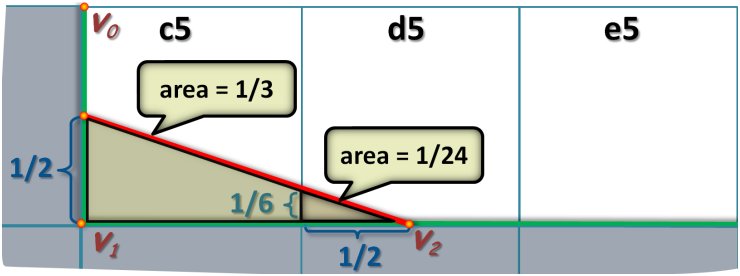
Figure 2: Computing blending weights
In practice, to ensure a smooth silhouette look, we need to minimize the color differences at the stitching positions of consecutive L-shapes. To achieve this, we slightly adjust the connection points on the L-shape segments around the middle position based on the colors of the pixels around the stitching point.
[size="5"]Sample usage
The camera can be moved around the scene using drag-and-click, and the mouse wheel can be used to zoom in or out. In addition, there are three blocks of controls on the right side of the sample's window:
Figure 3: A screenshot of the sample in action
The first block controls the rendering of the scene: