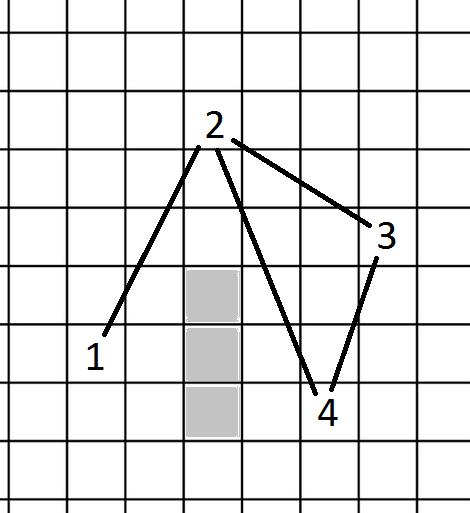
Im using micropather, a c++ implementation of a* pathfinding in my games. I got it to work fine with a strict grid-based system, but now need it to also work with "nodes". My setup is like this:
1. I have a collection of nodes. Each node has a X/Y-position, an ID, and an array of max 10 node-ids it can move to ("adjacent nodes").
2. Which nodes are reachable from each node are checked (based on a max distance and not having any obstacles between them).
3. Cost to move from a node to another is simply the distance between the 2 nodes' positions.
I guess some things will be silimar to how a grid works, but im not sure how to reconstruct the code.