13 hours ago, Michael Aganier said:
Knowing the usage of the rendering thread is important because If it is at 100%, it means that the GPU is waiting for more instructions because you're not sending them fast enough or in a such a way that the GPU can parallelize them. If this is the case, you have a 100% confirmation that the problem is your renderer.
So I'm not sure if I did this right but I went back and looked my CPU with the graph set to show logical processors
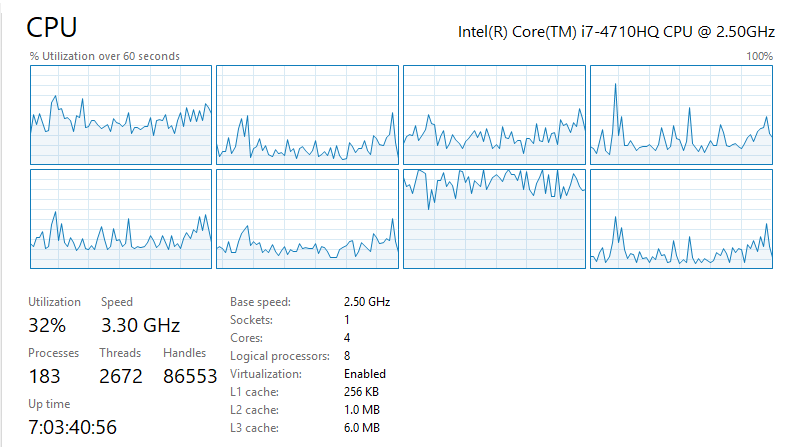
Based on this it looks like my CPU is crunching hard
12 hours ago, matt77hias said:
BTW if you use Visual Studio, you can use the built-in profiler. This will give you a rough idea of the methods taking most of the time. Furthermore, they do not use your timer. So you can rule out the issues you think to have with your timer.
Didn't know this was a thing. This is awesome. I feel like this confirms its my CPU. I'm not sure if I can set it to look at one run of a function or not but I set the "look at" frame as small as I can. Which is about 44ms


Looking at this a hugh chunk of time is spent in the addVertexToBuffer method. Which makes sense since this method is ran once per sprite. This method basically sets up the sprite, in here we are doing things like setting positions for the vertices, checking what tex coords to map, and etc. Honestly I don't know if this is the right place for this. I feel like the code in here might be better suited in the actual sprite class inset of having to redo it every frame for each sprite. Moving it to the Sprite class itself this stuff could be "precomputed" and the addToVertexBuffer would just be a data copy method
void SpriteRenderer::addToVertexBuffer(Sprite* sprite)
{
Texture* spriteTexture = sprite->getTexture();
if (spriteTexture != boundTexture)
{
flushVertexBuffer();
bindTexture(spriteTexture);
}
if (vertexCountInBuffer == MAX_VERTEX_COUNT_FOR_BUFFER)
{
flushVertexBuffer();
vertexCountInBuffer = 0;
vertexCountDrawnOffset = 0;
vertexBufferMapType = D3D11_MAP_WRITE_DISCARD;
}
float width;
float height;
float u = 0.0f;
float v = 0.0f;
float uWidth = 1.0f;
float vHeight = 1.0f;
float textureWidth = (float)spriteTexture->getWidth();
float textureHeight = (float)spriteTexture->getHeight();
SpriteVertex verts[6];
Rect* rect = sprite->getTextureClippingRectangle();
if (rect == nullptr)
{
width = textureWidth / 2.0f;
height = textureHeight / 2.0f;
}
else
{
width = rect->width / 2.0f;
height = rect->height / 2.0f;
u = rect->x / textureWidth;
v = rect->y / textureHeight;
uWidth = (rect->x + rect->width) / textureWidth;
vHeight = (rect->y + rect->height) / textureHeight;
}
verts[0].position.setXYZ(-width, -height, 0.0f);
verts[1].position.setXYZ(width, height, 0.0f);
verts[2].position.setXYZ(width, -height, 0.0f);
verts[3].position.setXYZ(-width, -height, 0.0f);
verts[4].position.setXYZ(-width, height, 0.0f);
verts[5].position.setXYZ(width, height, 0.0f);
if (sprite->isFlipped() == false)
{
verts[0].texCoords.setXY(u, vHeight);
verts[1].texCoords.setXY(uWidth, v);
verts[2].texCoords.setXY(uWidth, vHeight);
verts[3].texCoords.setXY(u, vHeight);
verts[4].texCoords.setXY(u, v);
verts[5].texCoords.setXY(uWidth, v);
}
else
{
verts[0].texCoords.setXY(uWidth, vHeight);
verts[1].texCoords.setXY(u, v);
verts[2].texCoords.setXY(u, vHeight);
verts[3].texCoords.setXY(uWidth, vHeight);
verts[4].texCoords.setXY(uWidth, v);
verts[5].texCoords.setXY(u, v);
}
verts[0].color.setRGB(0.0f, 0.0f, 0.0f);
verts[1].color.setRGB(0.0f, 0.0f, 0.0f);
verts[2].color.setRGB(0.0f, 0.0f, 0.0f);
verts[3].color.setRGB(0.0f, 0.0f, 0.0f);
verts[4].color.setRGB(0.0f, 0.0f, 0.0f);
verts[5].color.setRGB(0.0f, 0.0f, 0.0f);
//Pre transform the positions
Matrix4 model = sprite->getModelMatrix();
verts[0].position = model * verts[0].position;
verts[1].position = model * verts[1].position;
verts[2].position = model * verts[2].position;
verts[3].position = model * verts[3].position;
verts[4].position = model * verts[4].position;
verts[5].position = model * verts[5].position;
D3D11_MAPPED_SUBRESOURCE resource = vertexBuffer->map(vertexBufferMapType);
memcpy(((SpriteVertex*)resource.pData) + vertexCountInBuffer, verts, BYTES_PER_SPRITE);
vertexBuffer->unmap();
vertexCountToDraw += VERTEX_PER_QUAD;
vertexCountInBuffer += VERTEX_PER_QUAD;
vertexBufferMapType = D3D11_MAP_WRITE_NO_OVERWRITE;
}
After this most of my time is spent doing the matrix multiplications. By just commenting out the code that does this:
//Pre transform the positions
Matrix4 model = sprite->getModelMatrix();
verts[0].position = model * verts[0].position;
verts[1].position = model * verts[1].position;
verts[2].position = model * verts[2].position;
verts[3].position = model * verts[3].position;
verts[4].position = model * verts[4].position;
verts[5].position = model * verts[5].position;
My SpriteRenderer::render method time drops down to ~30ms. So its not crazy great but its still a pretty solid drop. So using a index buffer to cut out 2 of those pre-transformations might help too. Also sprite->getModelMatrix() under the hood is really doing transform * rotation * scale. So thats another set of matrix multiplications. I wonder if I should just recreate the matrix based on position, rotation, and scale vectors as it might be less math in the end
3 hours ago, Zaoshi Kaba said:
Am I understanding this correctly: your renderList contains 10,000 sprites and you Map() > memcpy() > Unmap() each one individually? No wonder you're having issues. It should be a single Map() > memcpy() > Unmap() call.
You are looking at that correctly and I 100% agree. I have actually done a quick test, where I place everything into a normal array first and then do a Map() > memcpy() from the normal array to the vertex buffer > Unmap() only when I am about to do a Draw call. By doing this it makes my SpriteRenderer::render method drop down to only taking ~25ms. Definitely a change that I need to make
51 minutes ago, Infinisearch said:
This is a much better way of doing things rather than mapping and unmapping 10,000 times. But 25ms still seems to much for what you're doing.
Are you creating 10,000 * 6 sprite vertex's per frame invidually? Or up front? 60,000 dynamic memory allocations a frame might slow you down especially on a laptop CPU.
What does flushvertexbuffer do exactly?
Oh no, the sprites are all created at the beginning of the application's start and added to the render list. Once that is done thats it. Nothing is added or removed during the test.
flushVertexBuffer is where my Draw call takes place. It basically updates the constant buffer for the MVP matrix and the does the draw call. Drawing as much data as I need (which in this case is all 10K sprites). Then any counters needed to determine where we are in the buffer or where to draw from, or etc are updated/reset
Sorry for the post walls, just trying to cover everything ")










