
11 users logged in
Proud partner of GDC 2025

Before posting, review our community guidelines.
Support GameDev.net with a monthly GDNet+ subscription!
A* graphical heuristic examples

July 07, 2006 04:14 AM
Ok, so you 'find' successor nodes, not 'create' them. Therefore, their structure is pregenerated, presumably in a one-to-one correspondence with the map grid. Right?

220
July 07, 2006 07:40 AM
Thats suitable for a very small grid... both in terms of memory and cpu. The implementation will always have a n iterations loop, where n is the total number of possibles nodes, because you have to reset all those nodes each time you call the pathfinder. memset aint free :P
July 07, 2006 03:07 PM
Indeed not, but memset is damn fast. I avoided initializing each node every time. Nodes are only initialized when they are first opened, so, only those nodes that actually need be searched to find the path are initialized.
I've tested it with grids up to 512 * 512, and the running time seems to be a function of the length of the path, not of the size of the grid. That is, a path of length 200 was found in the same amount of time on a 256*256 grid as on the 512*512. There is more inialization overhead - you guessed it right; it's in a call to memset. :)
I've tested it with grids up to 512 * 512, and the running time seems to be a function of the length of the path, not of the size of the grid. That is, a path of length 200 was found in the same amount of time on a 256*256 grid as on the 512*512. There is more inialization overhead - you guessed it right; it's in a call to memset. :)
755
July 07, 2006 04:22 PM
I'm using a similar approach, that is:
- 2D-array of nodes
- node contains state used in searching
- during search, dirtied (opened) nodes are pushed on a vector, and cleared afterwards (the idea was taken from TA Spring)
- homebrew, adaptable binary heap is used as a priority queue
But I didn't really checked if the no-allocation boost is a worth gain. It "seems" so...
Test with more complicated obstacles - the proportion may suddenly change to squared (if not using some more complicated heuristic).
- 2D-array of nodes
- node contains state used in searching
- during search, dirtied (opened) nodes are pushed on a vector, and cleared afterwards (the idea was taken from TA Spring)
- homebrew, adaptable binary heap is used as a priority queue
But I didn't really checked if the no-allocation boost is a worth gain. It "seems" so...
Quote:
Original post by Deyja
I've tested it with grids up to 512 * 512, and the running time seems to be a function of the length of the path, not of the size of the grid. That is, a path of length 200 was found in the same amount of time on a 256*256 grid as on the 512*512.
Test with more complicated obstacles - the proportion may suddenly change to squared (if not using some more complicated heuristic).
July 07, 2006 04:53 PM
Except in extreme cases (such as the big unbroken wall example often batted about) it runs pretty much the same. Oddly enough, if I penalize turning (to get it to generate straighter paths) it suddenly explores many more paths, and the complexity explodes!
In this graphic, orange is a closed node. The numbers are the cost of the path to that node (Not the estimated final cost; the 'cost so far'). This is almost the worst case I can demonstrate using my tile engine to visualize it.

In this graphic, orange is a closed node. The numbers are the cost of the path to that node (Not the estimated final cost; the 'cost so far'). This is almost the worst case I can demonstrate using my tile engine to visualize it.
July 07, 2006 04:58 PM
Quote:
during search, dirtied (opened) nodes are pushed on a vector, and cleared afterwards (the idea was taken from TA Spring)
This is how I originally did it. This time, I built the open list directly into the node structure. This ultimatly required me to have 1 more node than you'd expect, and start indexing at 1, not 0. Node 0 represents the root of the open list. I also always put the new open node before other nodes of the same cost already in the list. This gives it a bit of momentum, and means it tends to explore promising paths completely before exploring others.
755
July 07, 2006 05:18 PM
Hum. Could explain one more thing?
On this image, it seems to me, that, with your implementation, every node I marked with the red rectangle (except yellow ones) will have exactly the same estimated_final_cost (current cost + heuristic). How is it then, that so little nodes are being opened in the process?
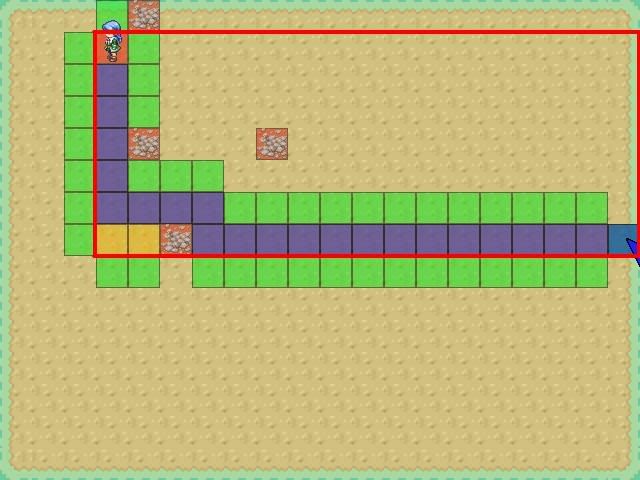
Are there some additional penalties? Or is it just coincidence (for example, your implenetation of 'list of nodes' always pushes from the back, thus favouring nodes being already on the list)?
EDIT: Blah, I meant the other way around... Thanks for the explanation above.
On this image, it seems to me, that, with your implementation, every node I marked with the red rectangle (except yellow ones) will have exactly the same estimated_final_cost (current cost + heuristic). How is it then, that so little nodes are being opened in the process?
Are there some additional penalties? Or is it just coincidence (for example, your implenetation of 'list of nodes' always pushes from the back, thus favouring nodes being already on the list)?
EDIT: Blah, I meant the other way around... Thanks for the explanation above.
July 07, 2006 05:55 PM
I assume my post right above answered your question?
755
July 07, 2006 06:11 PM
Quote:
Original post by Deyja
I assume my post right above answered your question?
Yup, it did. Thanks.
864
July 13, 2006 02:23 AM
As with any pathfinding implementation, there is a distinct tradeoff between online computation required and information stored (obtained by either pre-computation or designed). The method presented (which, given I read the OPs posts correctly, I've seen several times before) is a forward flood-fill with constrained horizon. It shows how algorithms may be optimised to a given domain type. Such methods are only applicable to small grids on closed manifolds. That's not to say, of course, that such domains don't pop up regularly in game design problems. ;)
Cheers,
Timkin
Cheers,
Timkin
This topic is closed to new replies.
Advertisement
Popular Topics


Advertisement
Recommended Tutorials


Advertisement