
Hello GameDev,
This entry is going to be a big one for me, and it's going to cover a lot. What I plan to cover on my recent development journey is the following:
1 - Goal of this Blog entry.
2 - Lessons learned using Node.js for development and testing as opposed to Chrome console.
3 - Linear Path algorithm for any surface.
4 - Dynamic Path Finding using Nodes for any surface, incorporating user created, dynamic assets.
5 - short term goals for the game.
-- - -- - -- - -- - -- - -- - Goal of this Blog entry - -- - -- - -- - -- - -- - --
My goal for this adventure is to create a dynamic path-finding algorithm so that:
- any AI that is to be moved will be able to compute the shortest path from any two points on the surface of the globe.
- the AI will navigate around bodies of water, vegetation, dynamic user assets such as buildings and walls.
- will compute path in less then 250 milliseconds.
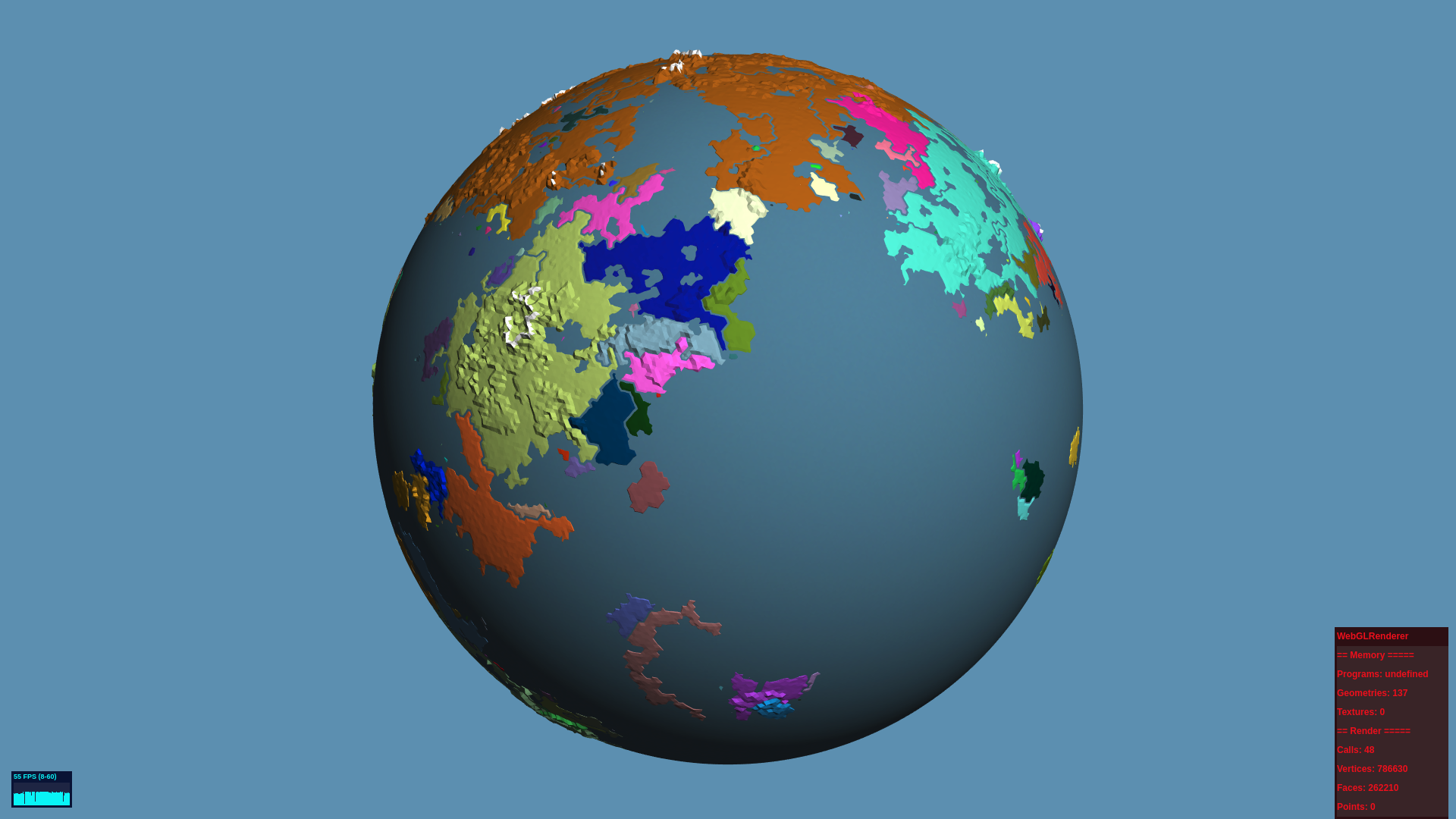
There are a few restrictions the AI will have to follow, in the image above you can see land masses that are cut off from one another via rivers and bodies of water are uniquely colored. If an AI is on a land mass of one color, for now, it will only be able to move to a location on the same colored land mass. However; there are some land masses that take up around 50% of the globe and have very intricate river systems. So the intended goal is be able to have an AI be on one end of the larger land mass and find the shortest path to the opposite end within 250 milliseconds.
Currently my path finding algorithm can find the shortest path in anywhere from 10 ms and up, and when I say up, I mean upwards of 30 seconds, and that's because of the way I built the algorithm, which is in the process of being optimised.
-- - -- - -- - -- - -- - -- - Lessons learned using Node.js for development and testing - -- - -- - -- - -- - -- - --
As of this writing I am using Node.js to test the efficiency of my algorithms. This has slowed down my development. I am not a programmer by trade, I've taught myself the bulk-work of what I know, and I often spend my time re-inventing the wheel and learning things the hard way. Last year I made the decision to move my project over to Node.js for continued development, eventually it all had to be ported over to Node.js anyways. In hind sight I would have done things differently. I would have continued to use Chrome console for testing and development, small scale, then after the code was proven to be robust would I then port it over to Node.js. If there is one lesson I'd like to pass on to aspiring and new programmers, it's this, use a language and development environment that allows you, the programmer, to jump into the code while it's running and follow each iteration, line by line, of code as it's be executed, basically debugging. It is so easy to catch errors in logic that way. Right now I'm throwing darts at a dart board, guesses what I should be sending to the console for feedback to help me learn more about logical errors using Node.js, see learning the hard way.
-- - -- - -- - -- - -- - -- - Linear Path algorithm for any surface. - -- - -- - -- - -- - -- - --
In the blog entry above I go into detail explaining how I create a world. The important thing to take away from it is that every face of the world has information about all surrounding faces sharing vertices pairs. In addition, all vertices have information regarding those faces that use it for their draw order, and all vertices have information regarding all vertices that are adjacent to them.
An example vertices and face object would look like the following:
Vertices[ 566 ] = {
ID: 566,
x: -9.101827364,
y: 6.112948791,
z: 0.192387718,
connectedFaceIDs: [ 90 , 93 , 94 , 1014 , 1015 , 1016 ], // clockwise order
adjacentVertices: [ 64 , 65 , 567 , 568 , 299 , 298 ] // clockwise order
}
Face[ 0 ] = {
ID: 0,
a: 0,
b: 14150,
c: 14149,
sharedEdgeVertices: [ { a:14150 , b: 14149 } , { a:0 , b: 14150 } , { a:14149 , b:0 } ], // named 'cv' in previous blog post
sharedEdgeFaceIDs: [ 1 , 645 , 646 ], // named 's' in previous blog post
drawOrder: [ 1 , 0 , 2 ], // named 'l' in previous blog post
} Turns out the algorithm is speedy for generating shapes of large sizes. ![]() My buddy who is a Solutions Architect told me I'm a one trick pony, HA!
My buddy who is a Solutions Architect told me I'm a one trick pony, HA!

Anyways, this algorithm comes in handy because now if I want to identify a linear path along all faces of a surface, marked as a white line in the picture above, you can reduce the number of faces to be tested, during raycasting, to the number of faces the path travels across * 2.
To illustrate, imagine taking a triangular pizza slice which is made of two faces, back to back. the tip of the pizza slice is touching the center of the shape you want to find a linear path along, the two outer points of the slice are protruding out from the surface of the shape some distance so as to entirely clear the shape. When I select my starting and ending points for the linear path I also retrieve the face information those points fall on, respectively. Then I raycaste between the sharedEdgeVertices, targeting the pizza slice. If say a hit happens along the sharedEdgeVertices[ 2 ], then I know the next face to test for the subsequent raycaste is face ID 646, I also know that since the pizza slice comes in at sharedEdgeVertice[ 2 ], that is it's most likely going out at sharedEdgeVertices[ 1 ] or [ 0 ]. If not [ 1 ] then I know it's 99% likely going to be [ 0 ] and visa-versa. Being able to identify a linear path along any surface was the subject of my first Adventure in Robust Coding. Of course there are exceptions that need to be accounted for. Such as, when the pizza slice straddles the edge of a face, or when the pizza slice exits a face at a vertices.
Sometimes though when I'm dealing with distances along the surface of a given shape where the pizza slice needs to be made up of more than one set of back to back faces, another problem can arise: I learned about the limitations of floating point numbers too, or at least that's what it appear to be to me. I'm sure most of you are familiar with some variation of the infinite chocolate bar puzzle

So with floating point numbers I learned that you can have two faces share two vertices along one edge, raycaste at a point that is directly between the edges of two connecting faces, and occasionally, the raycaste will miss hitting either of the two faces. I attribute this in large part because floating point numbers only capture an approximation of a point, not the exact point. Much like in the infinite chocolate bar puzzle there exists a tiny gap along the slice equal in size to the removed piece, like wise, that tiny gap sometimes causes a miss for the raycaste. If someone else understands this better please correct me.
-- - -- - -- - -- - -- - -- - Dynamic Path Finding using Nodes for any surface - -- - -- - -- - -- - -- - --
Now that I've got the linear path algorithm working in tip top shape, I use it in conjunction with Nodes to create the pathfinding algorithm.
Firstly I identify the locations for all nodes. I do this using a Class I created called Orientation Vector, I mention them in the blog post above. When they're created, they have a position vector, a pointTo vector, and an axis vector. The beauty of this class is that I can merge them, which averages their position, pointTo, and axis vectors, and it allows me to rotate them along any axis, and it allows me to move them any distance along the axis of their pointTo vector.


To create shoreline collision geometry, and node collision geometry, illustrated above, and node locations along shorelines, illustrated below, I utilise the Orientation Vector Class.
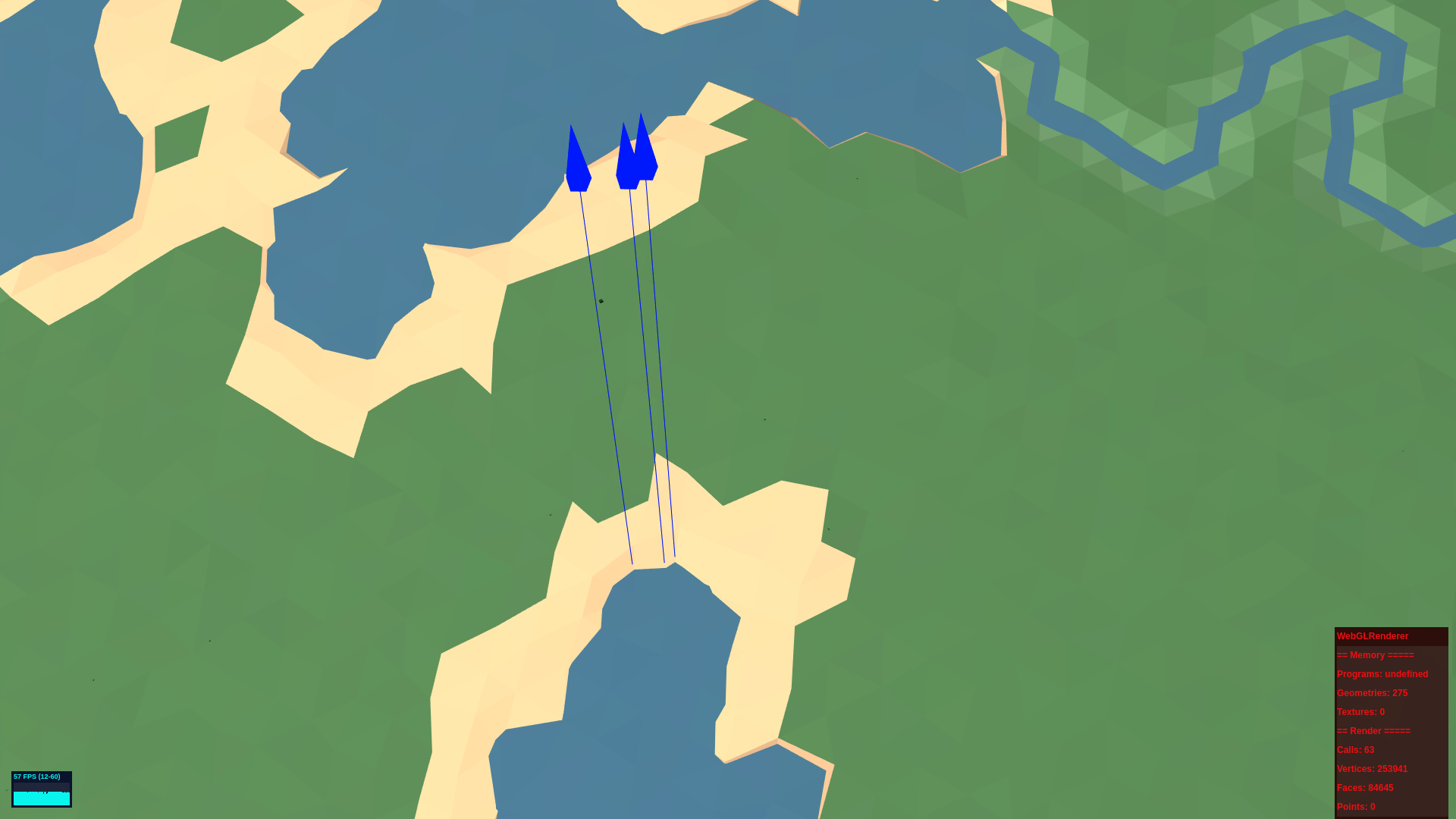
Firstly, the water table for the world is set to an arbitrary value, right now it's 1.08, so if a vector for a given face falls below the table and one or two vertors are above the table then I know the face is a shoreline face. Then I use simple Math to determine at what two points the face meets the water and create two OVectors, each pointing at each-other. Then I rotate them along their y axis 90 and -90 degrees respectively so that they are now facing inland. Since each face, which are shoreline faces, touch one another, there will be duplicate OVectors a each point along the shore. However, each Ovector will have a pointTo vector relative to it's sister Ovector during creation. I merge the paired Ovectors at each point along the shore, this averages their position, pointTo and axis. I then move them inland a small distance. The result is the blue arrows above. The blue arrows are the locations of three of the thousands of nodes created for a given world. Each Node has information about the shoreline collision geometry, the node collision geometry ( the geometry connecting nodes ), and the Node to its left and the Node to its right. Each face of collision geometry is given a Node ID to refer to.
So to create the path-finding algorithm. I first identify the linear path between the starting and ending points. I then test each segment of the linear path for collision geometry. If I get a hit, I retrieve the Node ID. This gives me the location for the Node associated for a given face of collision geometry. I then travel left and right along connecting Nodes checking to see if a new Linear path to the end point is possible, if no immediate collision geometry is encountered, the process continues and is repeated as needed. Subsequently, a list of points is established, marking the beginning, encountered Nodes and end of the line of travel. The List is then trimmed by testing linear paths between every third point, if a valid path is found, the middle point is spliced. Then all possible paths that have been trimmed are calculated for distance. the shortest one wins.
Below is the code for the algorithm I currently use. its my first attempt at using classes to create an algorithm. Previously I just relied on elaborate arrays.
function PATHFINDER_findPath( TGm , Pt , nodes , o , e , testAssets ){
e.currentProcesses ++;
var sN , eN , Br=[] , pIdx=[];
sN = new oNode( o.point1.clone() );
sN.fID = o.id1;
sN.pID = o.p1;
sN.gID = o.g1;
sN.ID = o.ID1;
eN = new oNode( o.point2.clone() );
eN.fID = o.id2;
eN.pID = o.p2;
eN.gID = o.g2;
eN.ID = o.ID2;
Br.push( new oBranch( sN , eN ) );
Br[0].setDirection( true );
var br , p , p1 , i , d , d2 , d3;
var info = [], ID , IN, seQ = false;
//// rewrite ////
// Cycle through all branches
for( var a=0; a<Br.length; a++ ){
br = Br[ a ];
// first do one raycaste to see if the starting nodes parent is in the way.
// second check if path between branchTestStart and branchTestEnd
nodeTOobject( br.start() , br.end() , o );
//console.dir( o );
// determine if path exists in pathIndex
// possibly entertain idea of storing path information perminently.
p = pathINDEX.getPath( br.startID() , br.endID() );
if( p == false ){
ID = PATHFINDER_firstCheck( br.start() , br.end() , Pt[ br.getParent( br.branchTestStart ) ] , o );
if( ID > -1 ){
IN = false;
} else {
p = new oPath( definePathLocal( TGm , o , false ) );
info = PATHFINDER_checkPathValidity( p , Pt );
ID = info[0];
IN = info[1];
}
} else {
ID = -1;
IN = false;
}
if( e.pathReadout ){
if( ID > -1 ){
console.log( 'BRANCH == startID: ' + br.startID() + ' endID: ' + br.endID() );
console.log( 'BRANCH == A: ' + a + ' ID: ' + ID + ' IDa: ' + nodes[ ID ].IDa + ' IDb: ' + nodes[ ID ].IDb + ' IN: ' + IN );
} else {
console.log( 'BRANCH == startID: ' + br.startID() + ' endID: ' + br.endID() );
console.log( 'BRANCH == A: ' + a + ' ID: ' + ID + ' IDa: -1 IDb: -1 IN: ' + IN );
}
}
if( ID > -1 ){
if( br.endID() == nodes[ ID ].IDb && br.getDirection() ){
if( p != false ){
if( e.pathReadout ){ console.log( 'over-riding to IDa' ); }
ID = -1;
}
} else if( br.endID() == ID && !br.getDirection() ){
if( p != false ){
if( e.pathReadout ){ console.log( 'over-riding to IDb' ); }
ID = nodes[ ID ].IDb;
ID = -1;
}
}
}
if( ID == -1){
if( e.pathReadout ){ console.log( 'valid path' ); }
br.setPath( pIdx.length , br.branchTestStart );
pIdx.push( p.clone() );
br.setDistance( p.getDistance() , br.branchTestStart );
br.setDirlog( br.getDirection() , br.branchTestStart );
}
if( e.pathReadout ){ console.log( ' ' ); }
if( ID > -1 ){
if( br.getNodeEncountered( ID ) && br.getNodeEncountered( nodes[ ID ].IDb ) ){
// check to see if the next node in this direction is already apart of this nodes listing
if( br.getDirection() ){
if( br.getNodeEncountered( nodes[ ID ].IDa ) ){
// continue this path in the true direction according to br.startID();
if( br.startID() == -1 ){
if( e.pathReadout ){ console.log( 'REMOVING BRANCH' ); }
br.destroy();
Br.splice( a , 1 );
} else if( br.getNodeEncountered( nodes[ br.startID() ].IDa ) ){
if( e.pathReadout ){ console.log( 'REMOVING BRANCH' ); }
br.destroy();
Br.splice( a , 1 );
} else {
br.insertNode( nodes[ nodes[ br.startID() ].IDa ].clone() , br.branchTestEnd );
br.setNodeEncountered( nodes[ br.startID() ].IDa );
}
} else {
// add IDa node to branch.
br.insertNode( nodes[ nodes[ ID ].IDa ].clone() , br.branchTestEnd );
br.setNodeEncountered( nodes[ ID ].IDa );
}
} else {
if( br.getNodeEncountered( nodes[ nodes[ ID ].IDb ].IDb ) ){
// destroy this path
if( br.startID() == -1 ){
if( e.pathReadout ){ console.log( 'REMOVING BRANCH' ); }
br.destroy();
Br.splice( a , 1 );
} else if( br.getNodeEncountered( nodes[ nodes[ br.startID() ].IDb ].IDb ) ){
if( e.pathReadout ){ console.log( 'REMOVING BRANCH' ); }
br.destroy();
Br.splice( a , 1 );
} else {
br.insertNode( nodes[ nodes[ nodes[ br.startID() ].IDb ].IDb ].clone() , br.branchTestEnd );
br.setNodeEncountered( nodes[ nodes[ br.startID() ].IDb ].IDb );
}
} else {
// add IDb of IDb node to branch.
br.insertNode( nodes[ nodes[ nodes[ ID ].IDb ].IDb ].clone() , br.branchTestEnd );
br.setNodeEncountered( nodes[ nodes[ ID ].IDb ].IDb );
}
}
} else if( br.getNodeEncountered( ID ) && !br.getNodeEncountered( nodes[ ID ].IDb ) ){
if( br.getDirection() ){
if( br.getNodeEncountered( nodes[ ID ].IDa ) ){
// switch direction
// add IDb node to branch
br.setDirection( false );
br.insertNode( nodes[ nodes[ ID ].IDb ].clone() , br.branchTestEnd );
br.setNodeEncountered( nodes[ ID ].IDb );
} else {
// create new branch:
// add IDa node to branch.
// add IDb to another branch
br.insertNode( nodes[ nodes[ ID ].IDa ].clone() , br.branchTestEnd );
br.setNodeEncountered( nodes[ ID ].IDa );
if( a < e.maxBranchSize /* arbitrary number used, will have to come up with idea */ ) {
i = Br.length;
Br[ i ] = br.clone();
Br[ i ].insertNode( nodes[ nodes[ ID ].IDb ].clone() , br.branchTestEnd );
Br[ i ].setNodeEncountered( nodes[ ID ].IDb );
Br[ i ].setDirection( false );
}
}
} else {
// add IDb node to branch
br.insertNode( nodes[ nodes[ ID ].IDb ].clone() , br.branchTestEnd );
br.setNodeEncountered( nodes[ ID ].IDb );
}
} else if( !br.getNodeEncountered( ID ) && br.getNodeEncountered( nodes[ ID ].IDb ) ){
if( br.getDirection() ){
// add ID node to branch
br.insertNode( nodes[ ID ].clone() , br.branchTestEnd );
br.setNodeEncountered( ID );
} else {
if( br.getNodeEncountered( nodes[ nodes[ ID ].IDb ].IDb ) ){
// switch direction
// add ID node to branch
br.setDirection( true );
br.insertNode( nodes[ ID ].clone() , br.branchTestEnd );
br.setNodeEncountered( ID );
} else {
// create new branch:
// add ID node to branch.
// add IDb of IDb to another branch
br.insertNode( nodes[ nodes[ nodes[ ID ].IDb ].IDb ].clone() , br.branchTestEnd );
br.setNodeEncountered( nodes[ nodes[ ID ].IDb ].IDb );
if( a < e.maxBranchSize /* arbitrary number used, will have to come up with idea */ ) {
i = Br.length;
Br[ i ] = br.clone();
Br[ i ].insertNode( nodes[ ID ].clone() , br.branchTestEnd );
Br[ i ].setNodeEncountered( ID );
Br[ i ].setDirection( true );
}
}
}
} else {
// create new branch:
// add ID node to branch.
// add IDb to another branch
br.setDirection( true );
br.insertNode( nodes[ ID ].clone() , br.branchTestEnd );
br.setNodeEncountered( ID );
if( a < e.maxBranchSize /* arbitrary number used, will have to come up with idea */ ) {
i = Br.length;
Br[ i ] = br.clone();
Br[ i ].insertNode( nodes[ nodes[ ID ].IDb ].clone() , br.branchTestEnd );
Br[ i ].setNodeEncountered( ID );
Br[ i ].setDirection( false );
}
}
a--;
} else {
// set the distance
// increment both start and end
if( p.getDistance() < 0 ){
console.log( '--------------------------------------' );
console.log( "-- something's up with p" );
console.log( '--------------------------------------' );
console.log( p );
}
br.setDistance( p.getDistance() , br.branchTestStart );
br.branchTestStart ++;
br.branchTestEnd ++;
if( br.branchTestEnd <= br.getTreeLength()-1 ){
//if( e.pathReadout ){ console.log( 'true, less then' ); }
a--;
} else {
if( e.pathReadout ){ console.log( 'BRANCH COMPLETE' ); }
br.pathFound = true;
// Branch is complete.
}
}
}
//// rewrite ////
if( e.pathReadout ){ console.log( 'STARTING TRIM' );}
if( br.getTreeLength() > 2 ){
// resets start and end.
for( var a=0; a<Br.length; a++ ){
Br[ a ].branchTestStart = 0;
Br[ a ].branchTestEnd = 2;
if( !Br[ a ].pathFound && e.pathReadout ){
for( var ii = 0; ii<100; ii++ ){
console.log( 'BRANCH NOT COMPLETE!!' );
}
}
}
// trim branches
for( var aa=0, A; aa<Br.length; aa++ ){
br = Br[ aa ];
br.setOldIndex();
A=1;
for( var a=0; a<A; a++ ){
//
// first check if path between branchTestStart and branchTestEnd
//if( br.getTreeLength() < 30 ){
nodeTOobject( br.start() , br.end() , o );
// determine if path exists in pathIndex
// possibly entertain idea of storing path information perminently.
p = pathINDEX.getPath( br.startID() , br.endID() );
if( p == false ){
ID = PATHFINDER_firstCheck( br.start() , br.end() , Pt[ br.getParent( br.branchTestStart ) ] , o );
if( ID > -1 ){
IN = false;
} else {
p = new oPath( definePathLocal( TGm , o , false ) );
info = PATHFINDER_checkPathValidity( p , Pt );
ID = info[0];
IN = info[1];
}
} else {
ID = -1;
}
if( e.pathReadout ){
console.log( ' ' );
if( ID > -1 ){
console.log( 'TRIM == startID: ' + br.startID() + ' endID: ' + br.endID() );
console.log( 'TRIM == A: ' + aa + ' ID: ' + ID + ' IDa: ' + nodes[ ID ].IDa + ' IDb: ' + nodes[ ID ].IDb + ' IN: ' + IN );
} else {
console.log( 'TRIM == startID: ' + br.startID() + ' endID: ' + br.endID() );
console.log( 'TRIM == A: ' + aa + ' ID: ' + ID + ' IDa: -1 IDb: -1 IN: ' + IN );
}
}
if( ID > -1 ){
if( br.endID() == nodes[ ID ].IDb && br.getDirlog( br.branchTestStart ) && IN ){
if( p != false ){
if( e.pathReadout ){ console.log( 'over-riding to IDa' ); }
ID = -1;
}
} else if( br.endID() == ID && !br.getDirlog( br.branchTestStart ) && IN ){
if( p != false ){
if( e.pathReadout ){ console.log( 'over-riding to IDb' ); }
ID = -1;
}
}
}
if( ID == -1){
// path is valid
// splice previous node if distance is shorter
d = p.getDistance();
d2 = br.getDistanceBetweenTwoIndexes( br.branchTestStart , br.branchTestEnd-1 );
if( e.pathReadout ){ console.log( 'TRIM == D: ' + d + ' D2: ' + d2 ); }
if( d <= d2){
// newly tested valid path is shorter
if( br.branchTestEnd - br.branchTestStart > 2 ){
br.spliceBetween( br.branchTestStart+1 , br.branchTestEnd-1 );
//br.branchTestEnd = br.branchTestStart + 2;
} else {
br.splice( br.branchTestStart+1 );
}
br.setPath( pIdx.length , br.branchTestStart );
br.setDistance( p.getDistance() , br.branchTestStart );
pIdx.push( p.clone() );
} else {
// newly tested valid path is longer
if( e.pathReadout ){ console.log( 'IMPOSSIBLE ++' ); }
//br.branchTestEnd ++;
}
br.branchTestStart ++;
br.branchTestEnd = br.branchTestStart+2;
if( br.branchTestEnd >= br.getTreeLength()-1 ){
if( br.compareIndexes() ){
// this cycle is done
// allow a to incriment.
if( e.pathReadout ){ console.log( '::: BRANCH FINISHED :::' ); }
br.finished();
seQ = true;
} else {
br.branchTestStart = 0;
br.branchTestEnd = br.branchTestStart+2;
aa--;
}
} else {
A++;
}
} else {
// obsticle encountered. create new path cycle only if nodes are unknown
// otherwise increment.
if( !br.getNodeEncountered( ID ) && !br.getNodeEncountered( nodes[ ID ].IDa ) && !br.getNodeEncountered( nodes[ ID ].IDb ) ){
//nodeTOobject( br.start() , nodes[ ID ] , o );
nodeTOobject( br.start() , br.end() , o );
if( e.currentProcesses < e.maxDeepProcesses ){
if( e.pathReadout ){ console.log( 'GOING DEEP ' + e.currentProcesses ); }
if( e.pathReadout ){ console.log( 'TRIM == start: ' + br.startID() + ' end: ' + ID ); }
p = PATHFINDER_findPath( TGm , Pt , nodes , o , e , false );
} else {
p = false;
}
// may need to check on condition of p;
if( p == false ){
// next cycle
} else {
d = p.getDistance();
d2 = br.getDistanceBetweenTwoIndexes( br.branchTestStart , br.branchTestEnd-1 );
if( e.pathReadout ){ console.log( 'TRIM == D: ' + d + ' D2: ' + d2 ); }
if( d <= d2){
// newly tested valid path is shorter
if( br.branchTestEnd - br.branchTestStart > 2 ){
br.spliceBetween( br.branchTestStart+1 , br.branchTestEnd-1 );
//br.branchTestEnd = br.branchTestStart + 1;
} else {
br.splice( br.branchTestStart+1 );
}
br.setPath( pIdx.length , br.branchTestStart );
br.setDistance( p.getDistance() , br.branchTestStart );
pIdx.push( p.clone() );
} else {
// newly tested valid path is longer
if( e.pathReadout ){ console.log( 'IMPOSSIBLE' ); }
}
}
}
br.branchTestStart ++;
br.branchTestEnd = br.branchTestStart+2;
if( br.branchTestEnd >= br.getTreeLength()-1 ){
if( br.compareIndexes() ){
// this cycle is done
// allow a to incriment.
if( e.pathReadout ){ console.log( '::: BRANCH FINISHED :::' ); }
br.finished();
seQ = true;
} else {
br.branchTestStart = 0;
br.branchTestEnd = br.branchTestStart+2;
aa--;
}
} else {
A++;
}
}
//}
}
}
}
if( e.pathReadout ){ console.log( Br.length ); }
for( var a=0; a<Br.length; a++ ){
if( Br[ a ].complete == false ){
Br[ a ].finished();
}
}
if( e.pathReadout ){ console.log( 'PATH COMPLETE' ); }
// calculate all distances for branches
if( Br.length > 0 ){
d = 100000;
d1 = 0;
for( var a=0; a<Br.length; a++ ){
if( Br[ a ].totalDistance < d ){
d = Br[ a ].totalDistance;
d1 = a;
}
}
p = new oPath( [] );
for( var a=0, aa=Br[ d1 ].path.length; a<aa; a++ ){
d = Br[ d1 ].path[ a ];
p.concat( pIdx[ d ] );
}
if( e.pathReadout ){ console.dir( 'BRANCH ID:: ' + d1 ); }
if( e.pathReadout ){ console.dir( Br[ d1 ].index ); }
if( e.pathReadout ){ console.dir( p ); }
if( e.pathReadout ){ console.dir( p.path.length ); }
e.currentProcesses --;
return p;
} else {
e.currentProcesses --;
return false;
}
}
I plan on improving the the process mentioned above by keeping track of distance as each path spreads out from it's starting location. Only the path which is shortest in distance will go through its next iteration. With this method, once a path to the end is found, I can bet it will be shortest, so I won't need to compute all possible paths like I am now.

The challenge I've been facing for the past two months is sometimes the Nodes end up in the water, The picture above shows a shoreline where the distance the OVectors travel would place them in the water. Once a node is in the water, it allows the AI to move to it, then there is no shoreline collision geometry for it to encounter, which would keep it on land, and so the AI just walks into the ocean. Big Booo! I've been writing variations of the same function to correct the location of the geometry shown below in Red and Yellow below.

But what a long process. I've rewritten this function time and time again. I want it to be, well as the title of this Blog states, Robust, but it's slow going. As of today's date, it's not Robust, and the optimised path-finding algorithm hasn't been written either.
I'll be posting updates in this blog entry as I make progress towards my goal. I'll also make mention what I achieve for shortest, long time for pathfinding. Hopefully it'll be below 250 ms.
-- - -- - -- - -- - -- - -- - short term goals for the game - -- - -- - -- - -- - -- - --
Badly... SO BADLY I want to be focusing on game content, that's all I've been thinking about. Argh, But this all has to get wrapped up before I can. I got ahead of myself, I'm guilty of being too eager. But there is no sense building game content on top of an engine which is prone to errors.
My immediate goals for the engine are as follows:
// TO DO's //
// Dec 26th 2017 //
/*
* << IN PROGRESS >> -update path node geometry so no errors occur
* -improve path finding alg with new technique
* -improve client AI display -only one geometry for high detail, and one for tetrahedron.
* -create ability to select many AI at the same time by drawing a rectangle by holding mouse button.
* -create animation server to recieve a path and process animation, and test out in client with updates.
* -re-write geometry merging function so that the client vertices and faces have a connected Target ID
* -incorporate dynamic asset functionality into client.
* -create a farm and begin writing AI.
* -program model clusters
* -sychronize server and client AI. Test how many AI and how quickly AI can be updated. Determine rough estimate of number of players the server can support.
*
*/see the third last one! That's the one, oh what a special day that'll be.
I've created a Project page,
please check it out. It gives my best description to date of what the game is going to be about. Originally I was going to name it 'Seed', a family member made the logo I use as my avatar and came up with the name back in 2014. The project is no longer going to be called Seed, it's instead going to be called Unirule.
[ edit: 02/02/18
Some new screen shots to show off. All the new models were created by Brandross. 

There are now three earth materials, clay, stone and marble. There are also many types of animals and more tree types. ]
Thanks for reading and if you've got anything to comment on I welcome it all.
Awoken










Sounds quite ambitious, but should still be achievable! Looking forward to seeing your progress, this sounds like it will be fun to play!
Hopefully it can still stand out from Seed!")