
If you search on the web for the best C++ source code. The Doom3 source code is mentioned many times, with testimonials like this one.
I spent a bit of time going through the Doom3 source code. It's probably the cleanest and nicest looking code I've ever seen.
Doom 3 is a video game developed by id Software and published by Activision.The game was a commercial success for id Software; with more than 3.5 million copies of the game were sold. On November 23, 2011 id Software maintained the tradition and it released the source code of their previous engine. This source code was reviewed by many developers, here's as example the feedback from fabien (orginal source):
Doom 3 BFG is written in C++, a language so vast that it can be used to generate great code but also abominations that will make your eyes bleed. Fortunately id Software settled for a C++ subset close to "C with Classes" which flows down the brain with little resistance:
- No exceptions.
- No References (use pointers).
- Minimal usage of templates.
- Const everywhere.
- Classes.
- Polymorphism.
- Inheritance.
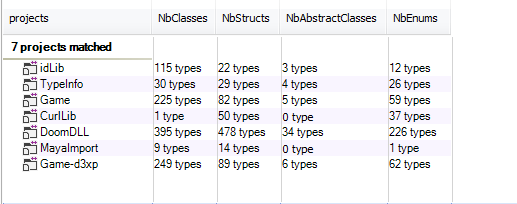
Many C++ experts don't recommend any more the "C with classes" approach. However, Doom3 was developed between 2000 and 2004, what could explain the no use of modern C++ mechanisms. Let's go inside its source code using CppDepend and discover what makes it so special. Doom3 is modularized using few projects, here's the list of its projects, and some statistics about their types:
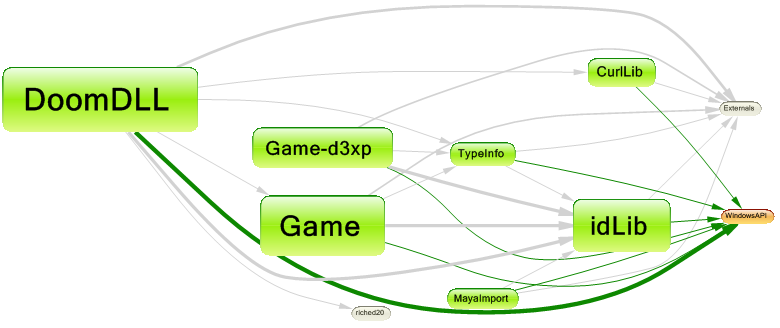
And here's the dependency graph to show the relation between them:
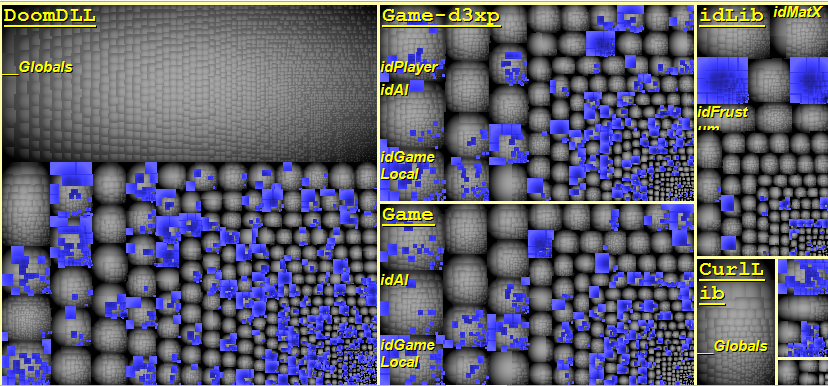
Doom3 defines many global functions. However, most of the treatments are implemented in classes. The data model is defined using structs. To have a concrete idea of using structs in the source code, the metric view above shows them as blue rectangles.
In the Metric View, the code base is represented through a Treemap. Treemapping is a method for displaying tree-structured data by using nested rectangles. The tree structure used is the usual code hierarchy:
- Project contains namespaces.
- Namespace contains types.
- Type contains methods and fields.
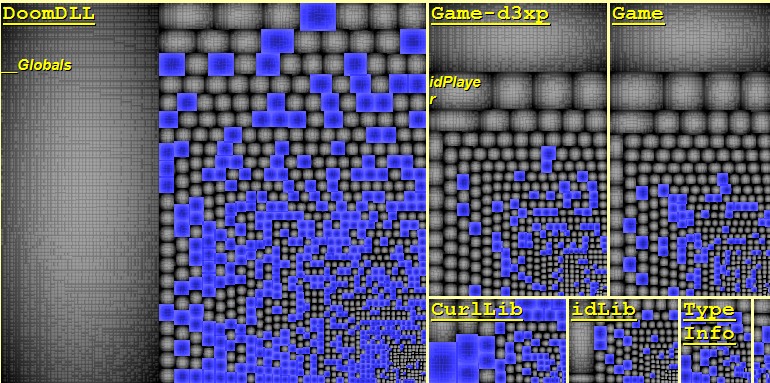
As we can observe many structs are defined, for example more than 40% of DoomDLL types are structs. They are systematically used to define the data model. This practice is adopted by many projects, this approach has a big drawback in case of multithreaded applications. Indeed, structs with public fields are not immutable.
There is one important argument in favor of using immutable objects: It dramatically simplifies concurrent programming. Think about it, why does writing proper multithreaded programming is a hard task? Because it is hard to synchronize threads access to resources (objects or others OS resources). Why it is hard to synchronize these accesses? Because it is hard to guarantee that there won't be race conditions between the multiple write accesses and read accesses done by multiple threads on multiple objects. What if there are no more write accesses? In other words, what if the state of the objects accessed by threads, doesn't change? There is no more need for synchronization! Let's search for classes having at least one base class:
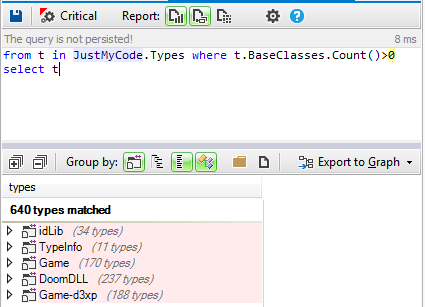
Almost 40% of stucts and classes have a base class. And generally in OOP one of the benefits of inheritance is the polymorphism, here are in blue the virtual methods defined in the source code:
More than 30% of methods are virtual. Few of them are virtual pure and here's the list of all abstract classes defined:
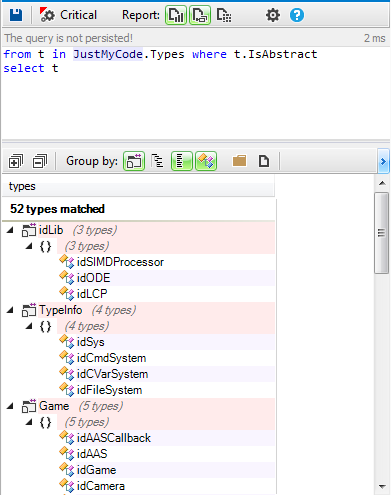
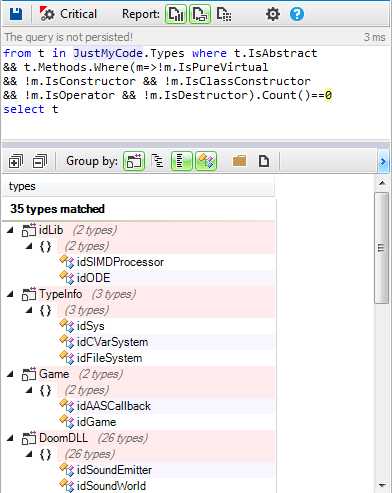
Only 52 are defined abstract classes, 35 of them are defined as pure interfaces,i.e. all their virtual methods are pure.
Let's search for methods using RTTI
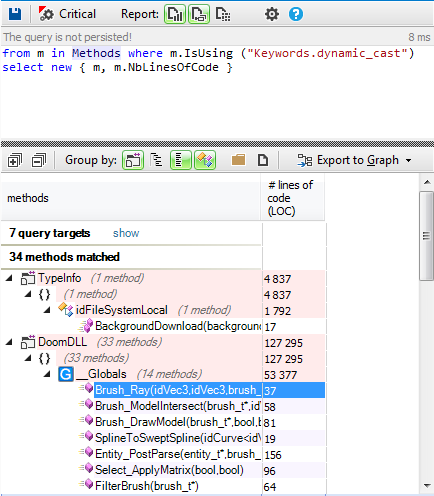
Only very few methods use RTTI. To resume only basic concepts of OOP are used, no advanced design patterns used, no overuse of interfaces and abstract classes, limited use of RTTI and data are defined as structs. Until now nothing special differentiate this code from many others using "C with Classes" and criticized by many C++ developers. Here are some interesting choices of their developers to help us understand its secret: 1 - Provides a common base class with useful services. Many classes inherits from the idClass:
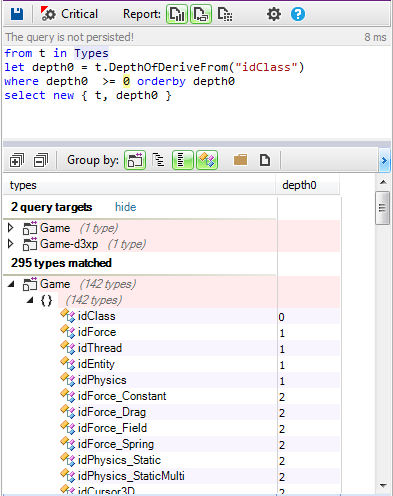
The idClass provides the following services:
- Instance creation.
- Type info management.
- Event management.
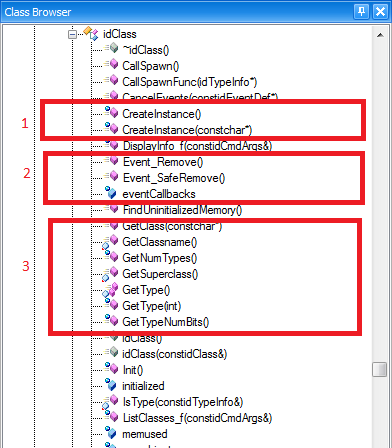
2- Make easy the string manipulation
Generally the string is the most used type in a project, many treatments are done using them, and we need functions to manipulate them. Doom3 defines the idstr class which contains almost all useful methods to manipulate strings, no need to define your own method as the case of many string classes provided by other frameworks.
3- The source code is highly decoupled with the GUI framework (MFC)
In many projects using MFC, the code is highly coupled with their types, and you can find types from MFC everywhere in the code. In Doom3, The code is highly decoupled with MFC, only GUI classes has direct dependency with it. As shown by this following CQLinq query:
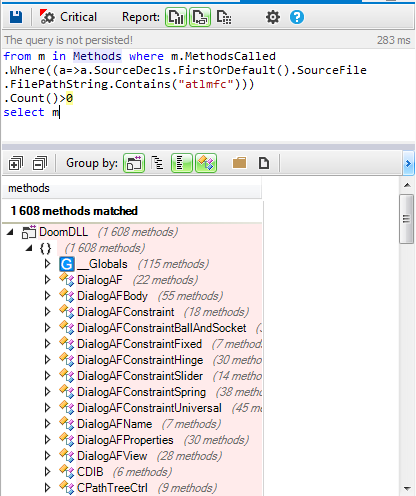
This choice has a big impact on the productivity. Indeed, only the Gui developers must care about the MFC framework, and for the other developers it's not mandatory to waste time with MFC.
4- It provides a very good utility library (idlib)
In almost all projects the most used types are utility classes, as shown by the result of this following query:
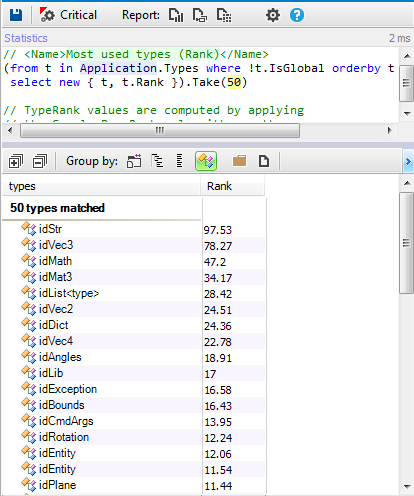
As we can observe the most used are utilities ones. If C++ developers don't use a good framework for utilities, they spend most of their developement time to fight with the technical layer. idlib provides useful classes with all needed methods to treat string, containers, and memory. Which facilitate the work of developers and let them focus more on the game logic.
5- The implementation is very easy to understand
Doom3 implements a hard coded compiler, and as known by C++ developers, it's not an easy task to develop parsers and compilers. However, the implementation of the Doom3 is very easy to understand and its code is very clean. Here's the dependency graph of the classes used by the compiler:
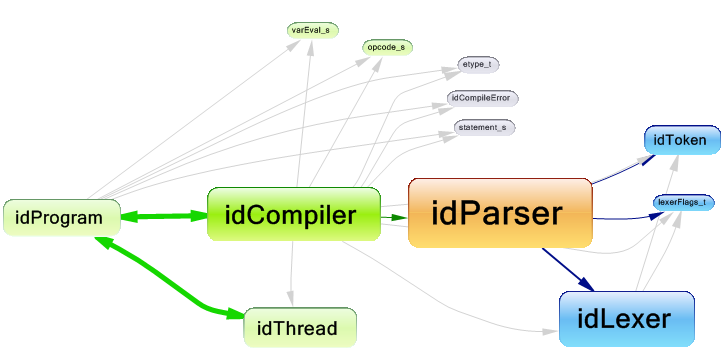
And here's a code snippet from the compiler source code:
We already study the code source of many parsers and compiler. But it's the first time we discover a compiler with a source code very easy to be understood, it's the same for the whole Doom3 source code. It's magic. When we explore the Doom3 source code, we can't say: WOW it's beautiful!
Summary
Even if the Doom3 design choices are very basic, but its designers make many decisions to let developers focus more on the game logic, and facilitate all the technical layer stuff. Which increase a lot the productivity. However when using "C with Classes", you have to know exactly what you are doing. You have to be expert like Doom3 developers. It's not recommended for a beginner to take risk and ignore the Modern C++ recommendations.




 ). After pressing through the initial confusion (About a week worth of headaches and confusion of focused trying to understand them), I found them easy to understand and use.
). After pressing through the initial confusion (About a week worth of headaches and confusion of focused trying to understand them), I found them easy to understand and use.

Are you saying that it's not recommended for a beginner to write code that is easier to fully comprehend? I would say that it should be the opposite, otherwise, if just hiding behind abstractions, there's little hope for ever becoming an expert.
And regardless of the coding style, I don't think a beginner could take on a project like this anyway. Obviously, one has to be some kind of expert to work on a game like this. Whether you use 'auto', initializer lists or lambdas or not isn't going to change that.