Aybe One said:
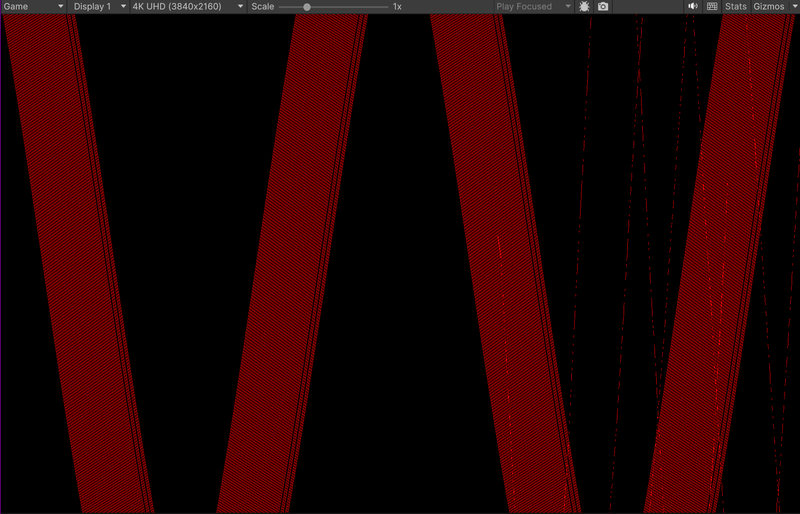
I switched to 3840x2160 to “assess” the power of compute shaders, got an amazing 5 FPS… Profiled, switched to ComputeShader.DispatchIndirect, it's smooth but GPU use is now 95%!!!*
You iterate over ALL lines in each thread of each invocation of your shader:
for (int i = 0; i < LinesCount; i++)
Int other words: For each of (all) 8 million pixels iterate over 4 (all) thousand lines. /:O\
This is like saying ‘hey, i have 4k little cores - let's make sure that each of those cores processes the same and as much work as possible’.
Ofc. it's slow. It's as inefficient as possible. You deserve the bad results to remind you that you should do at least a bit of optimization.
A trivial approach would be:
Notice each invocation draws a tile of 8x8 pixels.
1. Bin the lines to those tiles, so each tile gets its own list of lines intersecting this tile.
Technically this can be done with a shader processing one line per thread, increasing a atomic counter per tile in VRAM. That's not the fastest option, but it's simple and should be fast enough.
After the counts for all tiles (or ‘bins’) are known, calculate a prefix sum over the counters to know the amount of memory you need to store all per tile lists. So each tile knows it's beginning and end of it local list of lines.
Technically this requires one thread per tile, so a dispatch of (horizontal res / 8) x (vertical res / 8) threads to increase the counters.
If it's only 4K lines, i would do the prefix sum in a single workgroup of maximum size (which is 1024), which should be faster and much simpler than using more threads by using and synchronizing multiple workgroups but increasing the number of disptaches as well.
At this point you can also set up indirect dispatches for the tiles which are not empty for the next step.
Finally, draw the lines. We get one invocation for each tile that is not empty, and we have a list of lines covering this tile. So we draw the lines, but we need to clip them so we do not draw pixels multiple times from lines that appear in multiple segments.
Alternatively we could make sure each line appears only on one bin, by treating it as a point (center or first point of a line segment). Then there is no need for clipping and one thread just draws one whole line.
I guess this would be a bit faster if all your segments have a similar length.
The whole process is very similar to the common example of binning many lights to a low res screenspace grid, often done in deferred rendering to handle large amounts of lights.
It's a good exercise to learn some parallel programming basics, but it's still a serious effort just to draw some lines. So if you have no interest in GPU and parallel programming right now, ther should be still another way that is fast enough.
I see you only use vertical lines. But then it should be possible to match your compute reference with standard line rendering. Since they are all vertical, fill rules and subpixel conventions should not cause issues or confusion i would assume.
Another property (which i have ignored in my general proposal above) is the fact that your lines are probably already sorted horizontally, and that for each vertical row of pixels there will be only one pixel drawn.
This property should allow for a simpler and specific way to optimize, ideally nor requiring multiple dispatches for binning (which always is some kind of sorting as well).
That's surely the way to go if conventional triangle reasterization indeed fails.