Regarding https://github.com/sjhalayka/light_blocking_asymmetric
I’ve finished the GPU calculation code like a month ago, so I doubt that it will change much. This is good, because I am going to implement a CPU calculation code that mimics the GPU code. This way I can use both the CPU and GPU at the same time to speed up the calculation. I will want to prefer doing it on the GPU, so there must be a code to keep that in mind; the CPU threads come second.
Any ideas on what to avoid when implementing the threads?
I have implemented the threads before, for a TCP server https://github.com/sjhalayka/tcpspeed3_multithreaded_listener
Tiled rendering

August 27, 2024 08:27 PM

4,343
August 27, 2024 10:46 PM
taby said:
This way I can use both the CPU and GPU at the same time to speed up the calculation.
Good luck.
taby said:
Any ideas on what to avoid when implementing the threads?
Creating them is costly. To avoid it a ‘job system’ is nice. If that's the proper word. What i mean is:
Create (core count) threads just once at application start. They go to sleep and do nothing until you give work to the job system. They also go to sleep after the work is done.
Mine has the following member data, just to show what kind of stuff is needed:
class ParallelDispatcher
{
std::mutex mutex;
std::condition_variable cvDispatch;
std::condition_variable cvComplete;
std::atomic<int> jobsLeft;
int workLoadSize;
int jobsProcessed; // todo: if we count backwards, no need for workLoadSize
int workloadID;
int threadSync;
std::vector< std::thread > threadPool;
uint64_t workInfo;
uint64_t ownerInfo;
void (*callback) (const int, const int, const uint64_t, const uint64_t);
bool alive;
To do work, i use a callback which gets jobIndex, threadIndex, workInfo, ownerInfo variables.
This is annoying, because i always need to write a little callback function if i want to use the job system.
A better way would be to give a lambda instead using old school callbacks. But being a noob with modern C++, i did not try this.
Otherwise i'm very happy. I never need to mess with threads and all its details again. This is all i need to do, for example:
jobSystem.DispatchWork (count, Callback_CellToProcess, 0, (uint64_t)this);
jobSystem.WaitWork();It wakes the threads up and starts the work.
The main thread can either continue and poll later, or wait to expose the core to the job system.
If the work requires synchronization, i can do mutexes as usual. But GPU alike stuff is usually lock free.
During the work there is no need for expensive synchronization, just atomic increment of the work index.
The hard part is ending the work, e.g. ensuring all threads are done with the work. That's where the condition variables stuff goes, iirc.
It's not easy to make this, but after that you can use it anywhere.
Afaik modern C++ has no alternative to job systems yet, so it's still needed if you want ideal performance.
August 28, 2024 03:50 AM
I see now that OpenGL does not do multithreading. So I’ll need to manually do the GPU compute chunks, not done in another thread.
So far my luck is good.
4,343
August 28, 2024 06:26 AM
taby said:
I see now that OpenGL does not do multithreading. So I’ll need to manually do the GPU compute chunks, not done in another thread.
I thought you plan to do some percentage of the work on CPU threads. (Which works, but chances are the need to upload the CPU results to GPU causes a net loss.)
Iirc, some guys have figured out hacks to command a OpenGL driver from multiple threads, but i might be wrong.
By default OpenGL neither supports a multithreaded device context, nor can it do async compute tasks while rendering. Only Vulkan or DX12 can do those things.
But there might be a way with using OpenGL and OpenCL for compute with OpenGL interop.
If the drivers are smart, it should be possible to do compute and rendering concurrently this way.
OpenCL also has multiple queues, so running multiple compute tasks concurrently should work as well. (Though, i have tried this 10 years ago and it did not help neither on NV nor on AMD GPUs.)
However, it really seems OpenCL is dying, so i would not do this for a game anymore. If you have many compute dispatches and performance is bad, that's a real reason to switch to Vulkan.
Unfortunately you never know if performance is bad, until you try such alternative.
In my case the number of dispatches was something like 100-200, and the speedup from using VK was a factor of two.
In any case, ideally generate as much work as possible on GPU directly, using indirect dispatches. OpenGL can do this. (But again when i had tried it, it was not really much faster than calling everything manually from CPU. Drivers might be better now.)
Interestingly i found VK easy to use for compute. Way more cumbersome then OpenCL, but less annoying than OpenGL compute.
It's just the rendering stuff which is crazy complicated on low level APIs.
August 28, 2024 02:50 PM
Well, I've got it all working, and it's not a lot faster, if at all.
I will have to follow your further advice, and try not to create the threads once per app instance instead of once per frame.
Thank you again JoeJ!

August 28, 2024 02:50 PM
JoeJ said:
However, it really seems OpenCL is dying, so i would not do this for a game anymore. If you have many compute dispatches and performance is bad, that's a real reason to switch to Vulkan.
OpenCL at this point is dead (it is still used by some older projects - but even GPU vendors are giving up on it, maybe with exception of Intel, but hard to say there).
For general purpose GPU programs you do want to either use CUDA (NVidia) or ROCm (AMD) - they're very close to each other. Both support cutting edge features by specific hardware (from both vendors) and wrapping them isn't as impossible as it sounds.
The other option is mentioned Vulkan or Direct3D 12. Both are reasonable for use even just for compute.
As for multiple queues, you generally can't have more than single graphics, plus multiple compute ones. Sometimes it is better, sometimes worse (see attached image from PIX):
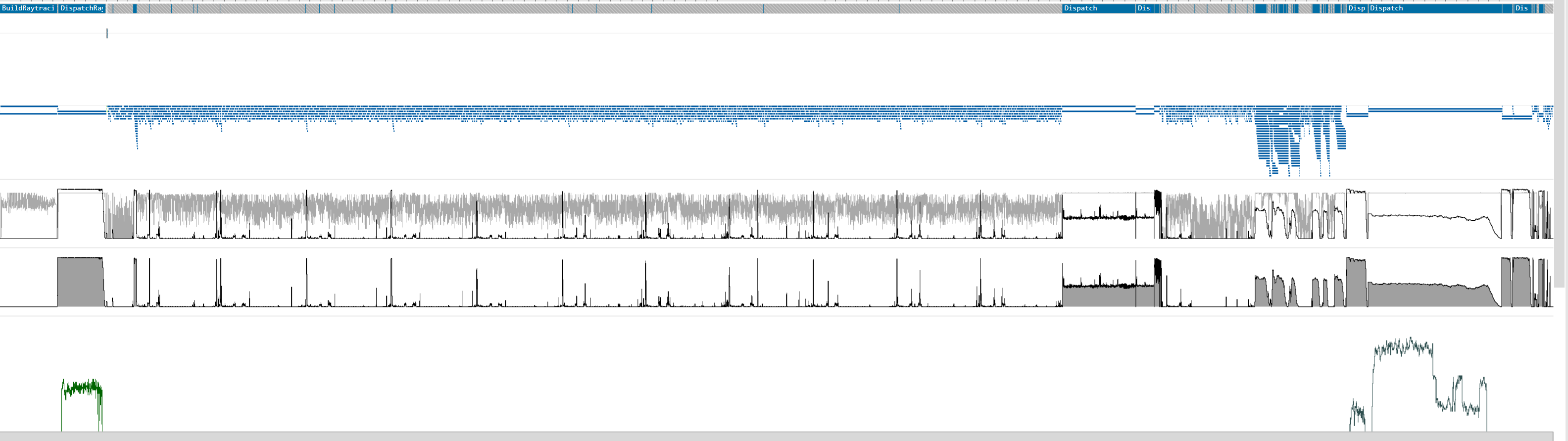
Although I still do a lot of work on graphics queue that should have been done on compute
My current blog on programming, linux and stuff - http://gameprogrammerdiary.blogspot.com
4,343
August 28, 2024 03:12 PM
Vilem Otte said:
For general purpose GPU programs you do want to either use CUDA (NVidia) or ROCm (AMD)
No and no. All those companies will go bankrupt when the AI bubble bursts, and so their proprietary APIs are as future proof as their shares. >:D
If they can't make some vendor independent standard together, all their GPUs are worthless too.
They should give them away for free, just like Jensen said. But including his own crap as well.
Hehehe : )
I'm currently working on my VK / OpenCL GI stuff again. Did not touch it for 10 years almost.
It's a terrible experience. Preprocessor is all i have to maintain changes, and debugging is like guessing.
But i prefer this over Cuda, which will be long dead til i'm done. \:D/
August 28, 2024 05:49 PM
I second this request
My current blog on programming, linux and stuff - http://gameprogrammerdiary.blogspot.com
4,343
August 28, 2024 08:37 PM
Well, i only have debug visualization of the probes, but looks like this:

The reflections would be:

It's not too bad, but i need to sharpen the filtered geometry. It has more impact on lighting than i've thought.
Another thing i should do is injecting direct lighting with an accurate method like shadow maps. Currently all lighting is done by the GI system, so the first bounce is already blurry.
But first i probably need open world streaming, so i can do larger scenes and more detail.
This topic is closed to new replies.
Advertisement
Popular Topics

Advertisement

