The GDC 2016 presentation “Optimizing the Graphics Pipeline with Compute" (I'm not sure I can post the non GDC-vault link, which does not seem to work for me at the moment) at slide 79 has the following passage:
“When we determine that we’ve exhausted our buffers, we can do a mid-dispatch flush of the rendering.”
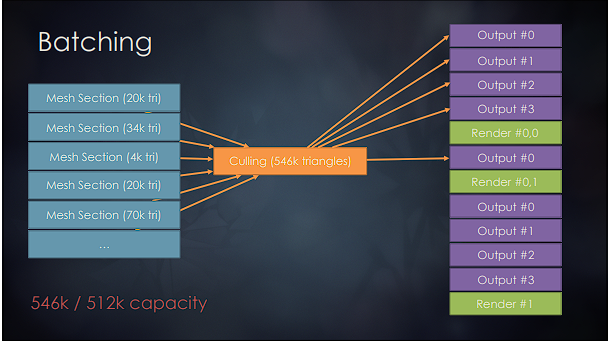
How can I achieve something like that? I have already implemented the triangle culling as a PoC with one large buffer to store all the indices, and now am trying to do it the proper way.
The only way I see to do it is by waiting on the fence (I'm using Vulkan) to later read-back some buffer with triangles overflow info from the GPU, but it seems like it will stall CPU way too much, considering that there may be many such “mid-dispatches" per frame.
The GDC vault link: gdcvault.com/play/1023109/Optimizing-the-Graphics-Pipeline-With
(again, not sure if it's working)

GDC Frostbite "mid-dispatch flush"


No, the link does not work for anyone who doesn't have an up-to-date vault subscription.
To be clear: your question is how do a mid-dispatch flush of the rendering, correct?
-- Tom Sloper -- sloperama.com

I'm not experienced enough with the gfx pipeline to tell an answer, but i can think of some options.
We could pre-record two command buffers for two queues. The first is CS on compute queue to cull and fill indirect draw buffers, the second runs on gfx queue and draws the buffer after it's full or done.
But idk about synchronization across multiple queues. Maybe events work, maybe fences are needed.
However, the point is that we enqueue say 10 of those dispatches on each queue. So we put 10 dispatches in our command buffer. This means we can not draw more than x * 10 triangles, and it has to be enough in any situation.
Under usual conditions say the latter 5 dispatches will do zero work, because all current triangles have been drawn already. So we pay a little price on executing zero work dispatches, which in my experience does have a cost due to memory barriers being executed although no work has been done at all.
Personally i think this zero dispatch cost is the main flaw of modern low level APIs.
With Mantle for example, we could run a section of command buffer in a loop, and break out after all work is done. That's a good solution, which has not made it into the VK specs because other IHVs could not support the feature, i've heard.
Years later Khorons has added conditional draws, which is the same idea. It works for draw and compute dispatches. But unfortunately, the brilliant API designers have forgotten to add support for memory barriers. So it's useless. :(
Same for NVs earlier GPU generated command buffer extension. No support for memory barriers. Although coincidentally i got to talk with the responsible API dev from NV, and he said adding support would be possible. Maybe they have improved this meanwhile already.
But i'm not sure you even need barriers, since you just draw stuff and there is no dependency on computed results. Likely conditional draws work for you as is, so i would look this up. It came came up after 2016 iirc, so maybe you can do better now than Dice back then.
Another new option is AMDs Work Graphs. Finally, after all those years, somebody tackles the urgent problem of GPUs being able to generate their own work. \:D/ … after compute APIs like OpenCL 2.0 or Cuda can do it since a decade already.
Some link, but there also related extensions for VK: https://community.amd.com/t5/gaming/gpu-work-graphs-a-great-day-for-gpu-programmability/ba-p/613612
Finally, you could also look up Epics sources and talks on Nanite. They have the same problem here, and they solved it with persistent compute threads to implement a multiple producer, multiple consumer model on GPU.
Their culling threads generate indirect drawing work for both HW and SW rasterizers. API specs do not guarantee this would work, as there is no guarantee persistent threads keep running at some priority over other dispatches, but currently it works well on all platforms for them.
@JoeJ Thank you so much for such a detailed reply! I for some reason thought that the conditional rendering is for draws only 🙃
These work graphs seem super interesting, I will definitely look into that.



