Both talk about “building a Bounding Volume Hierarchy (BVH) over the lights in the scene”. I can't get my head around this. How does a BVH for lights look a like? How doe's it differ from octree or kdtree? If someone could explain it simple worlds or show a small 2d illustration of lights in BVH, I would greatly appreciate it.
Picture with some point and spot lights. It's just beautiful:
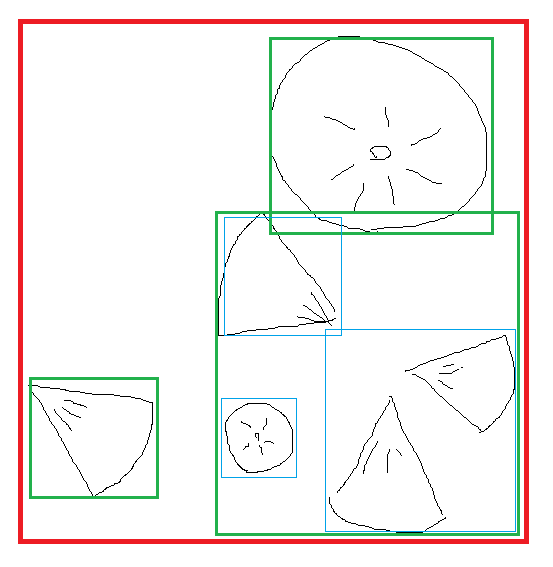
Assuming 2D BVH4 and splitting nodes at the center of bounding rectangle (not best quality tree, but fast to build)
Red: Root, level 0
Blue: level 1 (top left child is empty)
Green level 2, all are children of bottom right green box, top right is empty.
Algorithm to build the tree (talking about 3D BVH8 from now on):
Make bounding boxes for all lights, root node with bounding everything, set as current node and make all lights its children.
Set split point at the center of the current box, or at the average position from all children which would give better balance, or do something fancy like surface area heuristic for best quality.
iterate over all children, determinate which octant their center falls into, remember octant per child and increase octant counters.
Reorder children so they are linear lists for each octant: From the prefix sum of octant counters you know the starting index for each octants child list, use this to bin the children to their octant and while doing so calculate octant bounding boxes.
Make child nodes from the octants, and recursively continue with step 2.
I guess 4 is a bit hard to get, but think of it as shuffling the lights in memory so each node only needs a first child pointer and the number of children. This also results in ideal memory access patterns while traversing the tree. The whole process is similar as sorting stuff in morton order (which is what happens if you would use the same algorithm for an octree).
On GPU it makes sense to build multiple top levels of the tree in a single wide workgroup shader, and after enough nodes are around to saturate better use small workgroups per level. Good candidate for async compute, bacuse GPU is likely underutilized the whole time.
… pseudo code on step 4. It's just the usual binning algorithm.
shared int octantCount[8] = {};
shared or global int lightListIndex[totalNumberOfLights];
for each light in parallel
{
int octant = (x>center) | ((y>center)<<1) | ((z>center)<<2);
lightListIndex[light] = atomic_add(octantCount[octant], 1);
}
// now we know the sub index of each light per octant, but not yet the total index after compacting all 8 sub lists to a single list.
if (threadID==0) for (int i=1; i<8; i++) octantCount[i] += octantCount[i-1]; // ofc. use the faster parallel version using 4 threads, to save a cycle or two : )
for each light in parallel
{
int octant = (x>center) | ((y>center)<<1) | ((z>center)<<2);
int listStart = octant==0 ? 0 : octantCount[octant-1];
int finalCompactedListIndex = listStart + lightListIndex[light];
// copy the ordered lights from old to new buffer, now nicely sorted
newLightsBuffer[finalCompactedListIndex] = oldLightsBuffer[light];
}
if (threadID==0) // remember list start and count per octant sou you can access child range of lights in the next interation…
I hope it makes some sense and i have no one off bugs. (Edit, fixed terrible bug - although i did this really often it's still confusing)
Notice the overlapping bounds of BVH is a big disadvantage here, because it requires a stack or alternative during traversal. (Personally i used stackless with skip pointer approach (or ‘miss’-pointer as called in your linked blog post), but there are other methods like short stack)
Because a shading sample is just a point with no volume, you could get away with a simple point query if you had a tree with no overlapping bounds, like (non loose) octree.
This requires to put one light into multiple nodes, which makes the tree building slower and harder.
So again the best choice i s a matter of data. Are most lights static? yes → octree, with a coarse uniform grid for few dynamic lights / no → BVH… just one idea.
Be sure to gather some resources of what solutions other devs propose…
Edit: After reading paper from your link i see tehy use BVH only to bin lights to tiles / froxels. BVH is not traversed per pixel, so my argument from this post does not apply here.
How many lights do you need to support, and why so many? Do you surely need BVH at all?
@JoeJ I just wanted to understand what is BVH and how / where does it help to improve light shading performance. Not sure I got it yet :D. I will read ur answers over again.
@JoeJ Not did not get it. You dived way to deep in details, where I for starters wanted a simple theoretical explanation on what principle BVH's are created and how do they help with shading speedup. Like real for Dummies explanation :D
The given problem is: I have many lights around - how can i know for a given shading point which lights are close enough to affect it?
Iterating all 100k lights for each pixel to shade is much too slow.
Rasterizing the light bounds and accumulate contributed lighting to a buffer is an option, but it's fillrate intense. (And if i want to light random points like ray intersections it's again no option at all.)
So we need a form of spatial acceleration structure to find close lights to speed things up.
3D Uniform grid? Super fast, no traversal necessary - just a lookup to get the list of lights. But it takes too much memory eventually.
Nested hierarchical (or ‘cascaded’) grid? This is an option if you can cull lights at the distance, or combine multiple lights to a single one (like ‘lightcuts’ does for example)
Still too much memory or not applicable? Then we need a tree. Popular choices: Octree, kd-tree, BVH. All those are similar, they are just trees. We can talk for hours which one to pick, but it won't make a difference of night and day.
What matters is that we need to jump around in memory while we traverse any kind of tree, which sucks on GPU even more than on CPU. A need for a stack also hurts GPU more, because GPU threads can not have a lot of fast memory available.
So to get a practical compromise of grid and tree, we can partition the screen into a 2D grid of tiles, or a perspective 3D grid of ‘froxels’. Then for each tile traverse the tree and record all lights that affect the tile. Finally when shading a pixel look up the compact list of lights from the tile. (Unfortunately this would not help for ray intersections - if they are out of screen, they would still need to traverse the tree because the grid is of no help.)
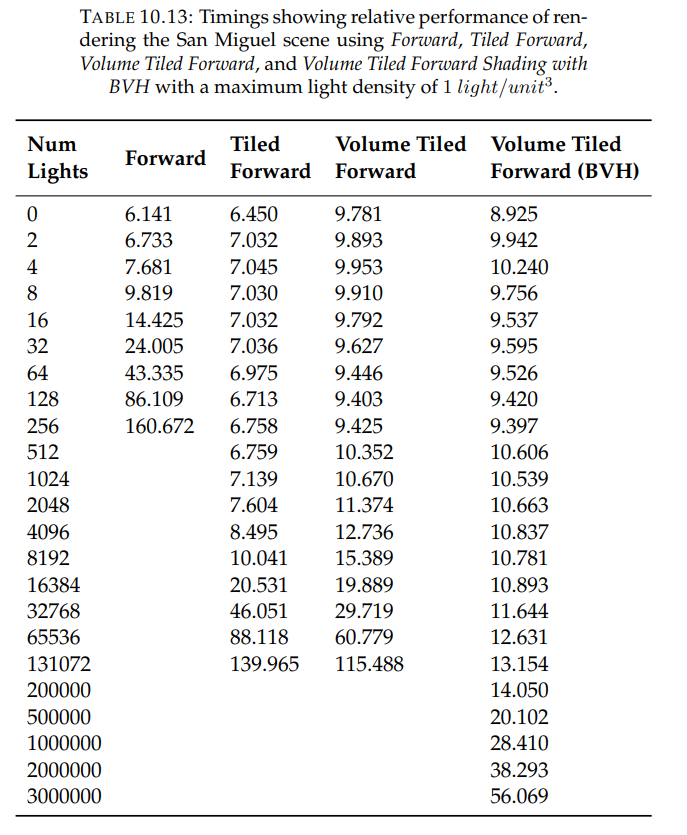
The paper you linked has nice table about perf:
I guess Forward means iterating all lights per pixel
Tiled Forward: Bin lights to 2D screen grid first, get reduced list of lights when shading from that
Volume likely means using 3D froxels instead 2D grid to handle depth
I, for sure, know there exist implementations of SAH-BVH and Split-SAH BVH (SBVH) that run entirely on GPU. It is possible but most likely an overkill.
For small BVHs (like for light sources), using GPU to do the computation is most likely an overkill. This of course depends where the target data is needed (F.e. if you do the processing and have source data both in CPU memory, then you don't need to do the building on GPU side - as copying data source there and results back … would most likely take more time than building the BVH itself on CPU).
@vilem otte Thanks, but BVH construction is something i have solved for my needs and it's cost is negligible. I get away with only transforming bottom level structures (no need for refitting, so no inter level dependencies), and building top level tree on GPU is something like 0.1ms on GPU iirc.
But i'm still facing a similar problem as discussed here, just it's not about lights but a surfel hierarchy i have to associate with the visible geometry. The surfels are on the surface of geometry, and i plan to access them with textures where each texel points to a corresponding surfel. I can then do simple bilinear interpolation like regular texture mapping to blend 4 surfels per pixel.
The Problem is: The indices from the textures will not match the current LOD cut of the surfel tree in memory. This depends on camara position, with 100k of surfels in use at a time, while the entire world will need many millions of surfels.
So i'm looking for a way to resolve the indirection from global surfel indices stored in textures.
The trivial solution would be to traverse the surfel tree to find them for each texture fetch, but it hurts to do this just to resolve some indirection. Updating the textures per frame could work maybe, or more likely use some form of hashing. Have not thought much about it yet, but i realize i have underestimated this problem.
@joej I see, so you're technically not requiring building BVHs for F.e. skinned geometry (which requires you to use GPU). I have never needed GPU builder for top-level trees, you can build them instantly (even for thousands objects it is pretty much instant).
As for your problem - you have a scene with geometry and huge amount of surfels (millions). From those millions you pick few hundred thousand for given frame, and now for geometry you need to find 4 closest surfels for each pixel and interpolate between them (to get F.e. indirect light or something … not that different from how generic final gathering works for photon mapping). Do I understand your problem correctly?