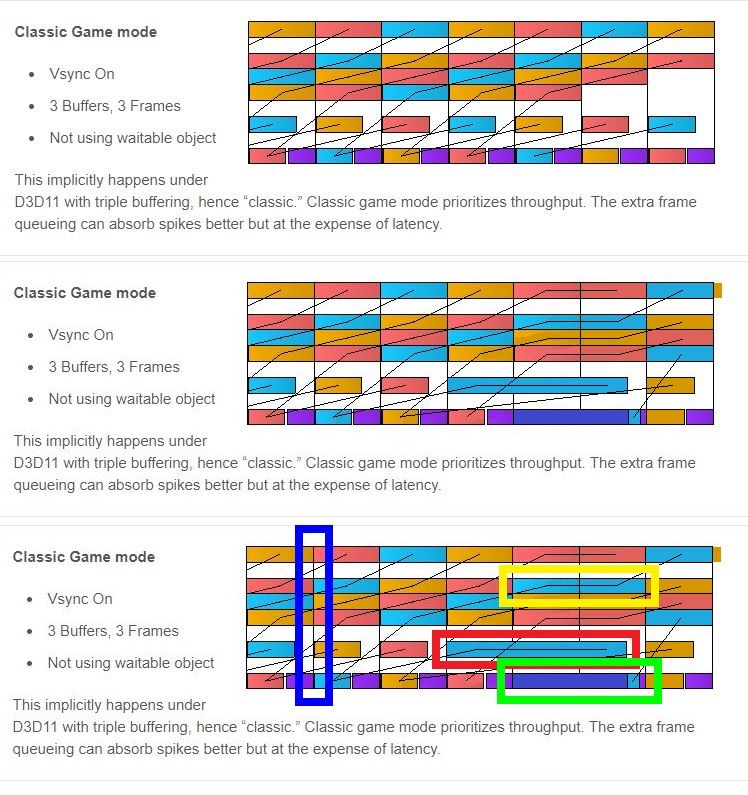
Based on your reply, I changed the original intel diagram a little bit just to make sure I understand what you mean.
The first diagram is the original one. The second diagram is what I made. The third one has some marks so that you know what I'm talking about.
Looking at the third diagram, you can notice the red rectangle indicates what I changed. I made the GPU work last longer. It caused some other changes to the pipeline. Indicated by the yellow rectangle, I presume this is what you mean by
1 hour ago, SoldierOfLight said:A frame in the "present queue" is waiting for all associated GPU work to finish before actually being processed and showing up on screen
. The GPU work lasts longer for that frame. Consequently, the "present queue" has to wait for the GPU to finish this frame. Also, by
1 hour ago, SoldierOfLight said:The way I prefer to think about / visualize it is that a frame is waiting in the GPU queue until all previous work is completed, and is then moved to a present queue after that, where it waits for all previous presents to complete.
I think you are saying now that the "present queue" will wait for GPU work to finish, we might as well think it as it will not be put in the "present queue" until GPU finish its work for that frame.
1.Now, my first question is, which way visualize what happens on the hardware level better? (Even though they make no difference conceptually. It only changes where the start of a "colored block" in "present queue" is conceptually and the start does not matter as much as the end.)
2.My second question is, within the green rectangle, the (light blue) CPU thread is blocked by a fence(dark blue) and then blocked by Present(purple), am I right?
3.My third question is, within the blue rectangle, the brown "GPU thread" (command queue) is blocked by a present to render target barrier, am I right?