You’re absolutely right. The problem you described is one of the reasons I've spun task execution into its own system, which operates independently of whatever’s doing the planning. In my code, this system is really the engine which drives everything else agent-ai-related. If anyone’s willing, I would appreciate your feedback on the approach - it’s been doing a good job, but I’m not sure how similar it is to existing solutions out there which might be better:
- - -
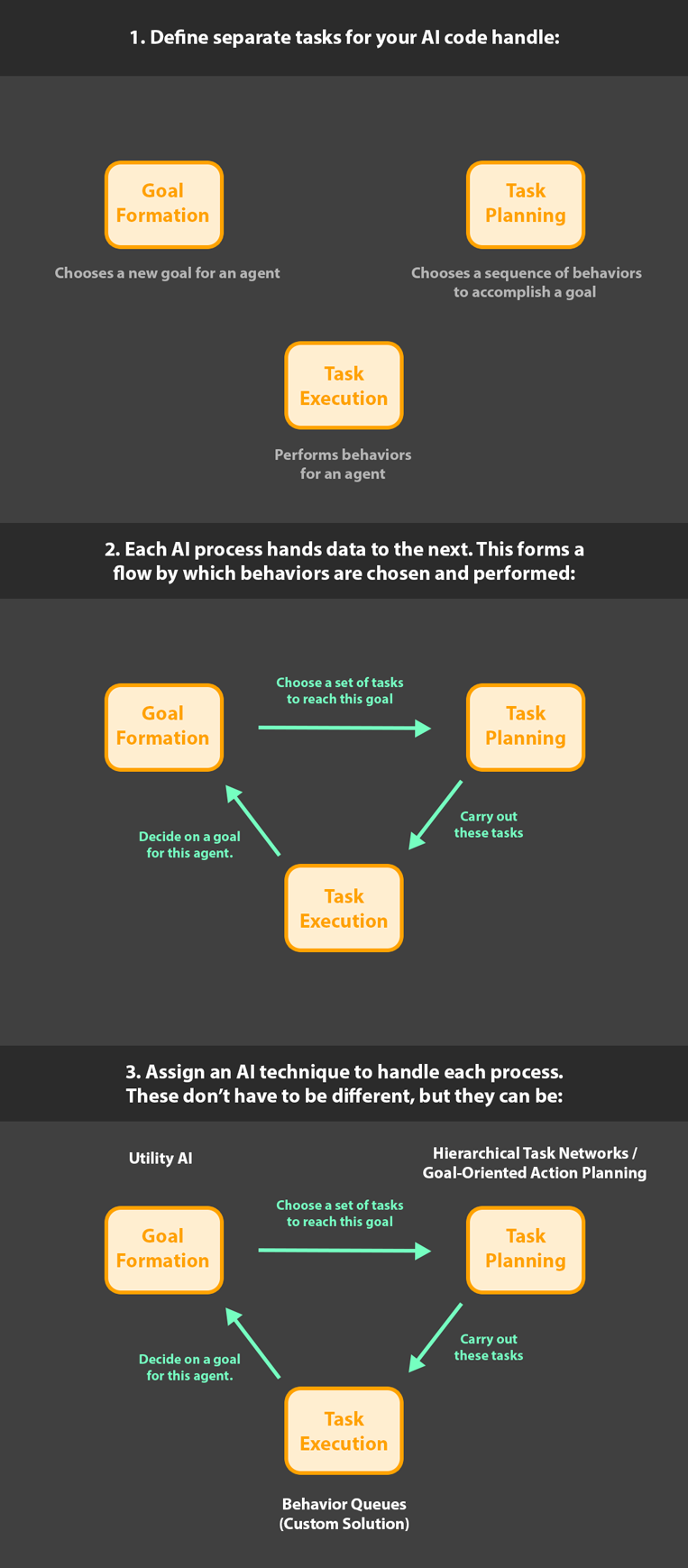
1. To handle task execution, I use a pattern I’ve been calling ‘behavior queues’. A behavior queue is a queue structure (first in, first out), which can hold a sequence of one or more agent behaviors.
(Skip the rest of this explanation if you'd rather see a visual version, below.)
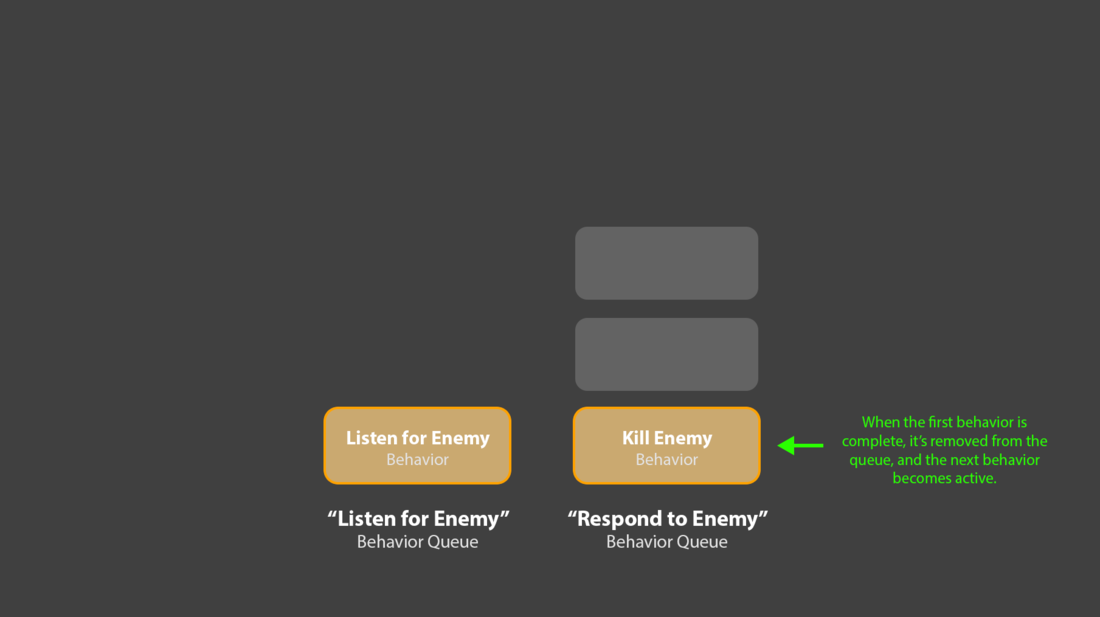
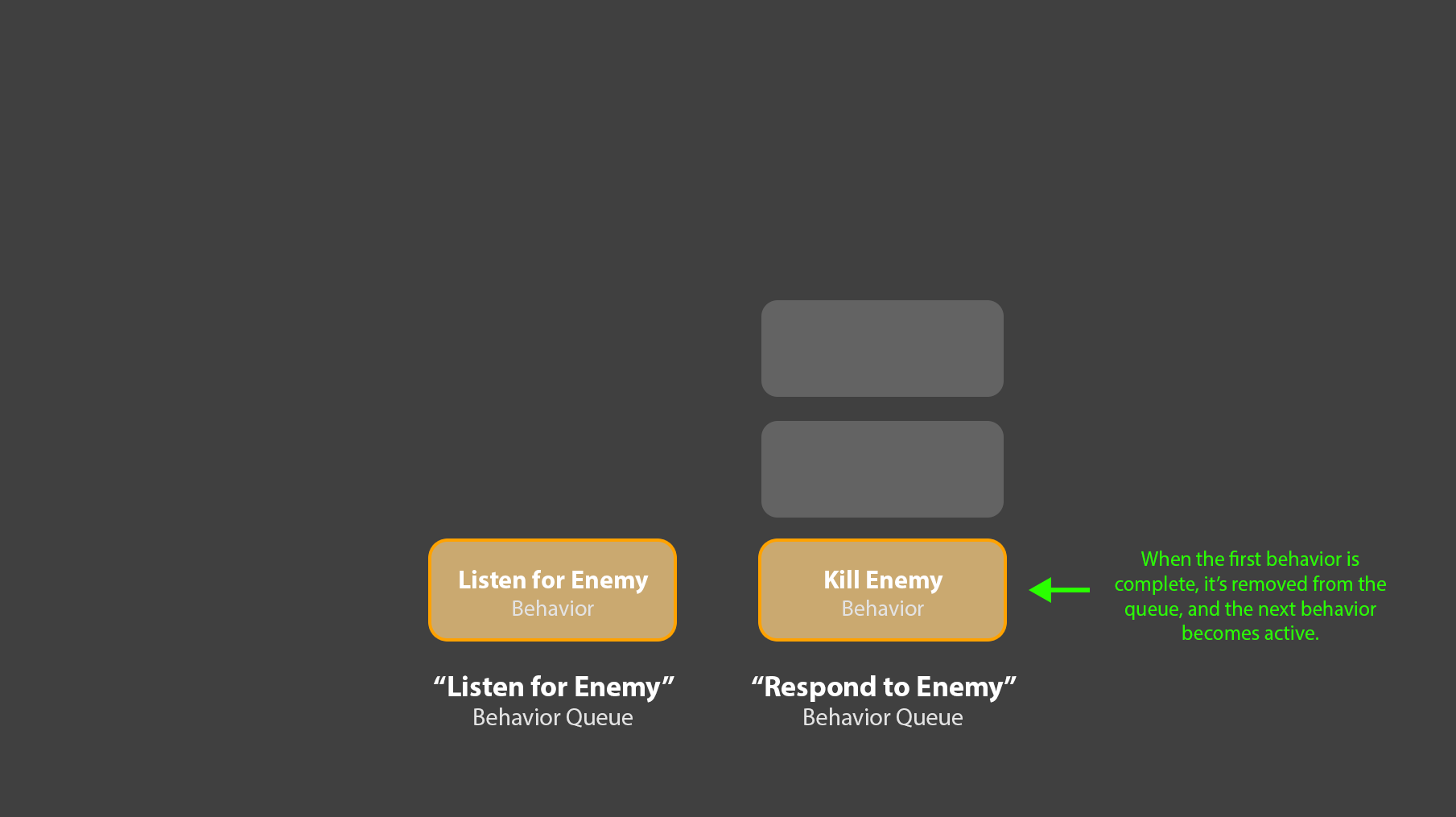
2. Only the oldest behavior in the queue is active at one time. When the active behavior notifies the queue that it’s complete, that behavior is popped from the queue, and the next behavior in line is activated. By this process, an agent performs behaviors.
3. An agent can own multiple behavior queues, and this is where the more complex problem solving comes in: Each of an agent’s queues has an Id, and these Ids can be themed to different, specific purposes.
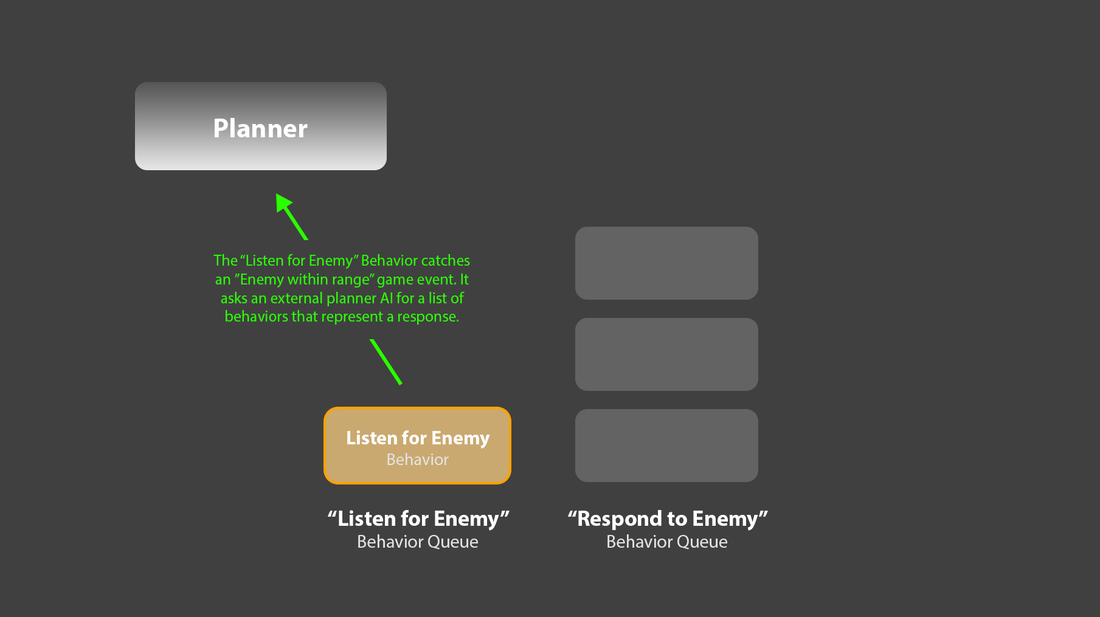
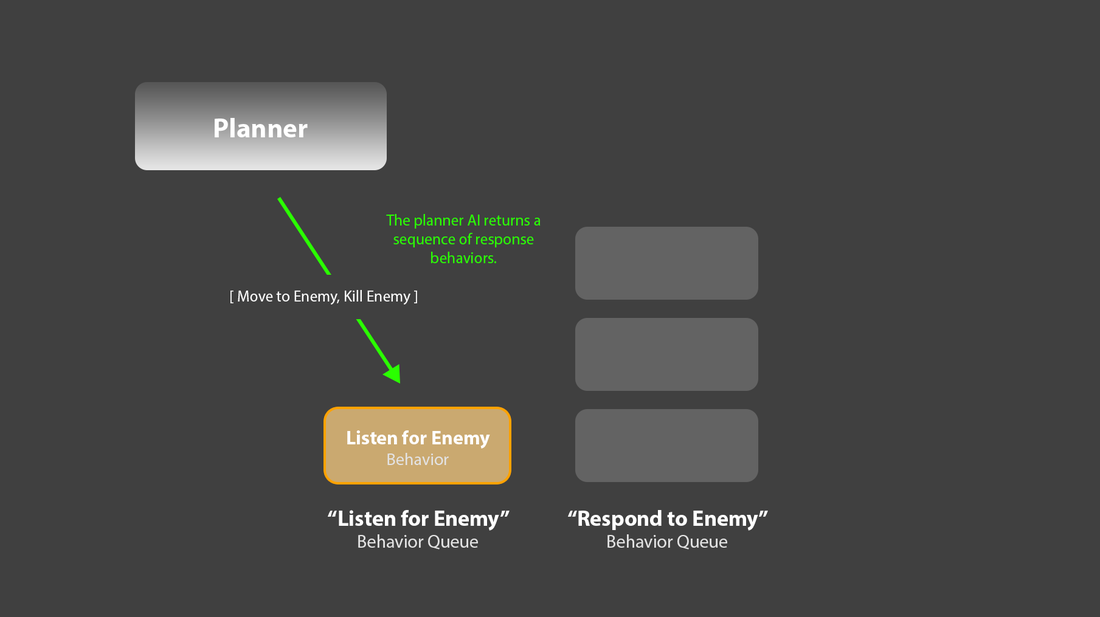
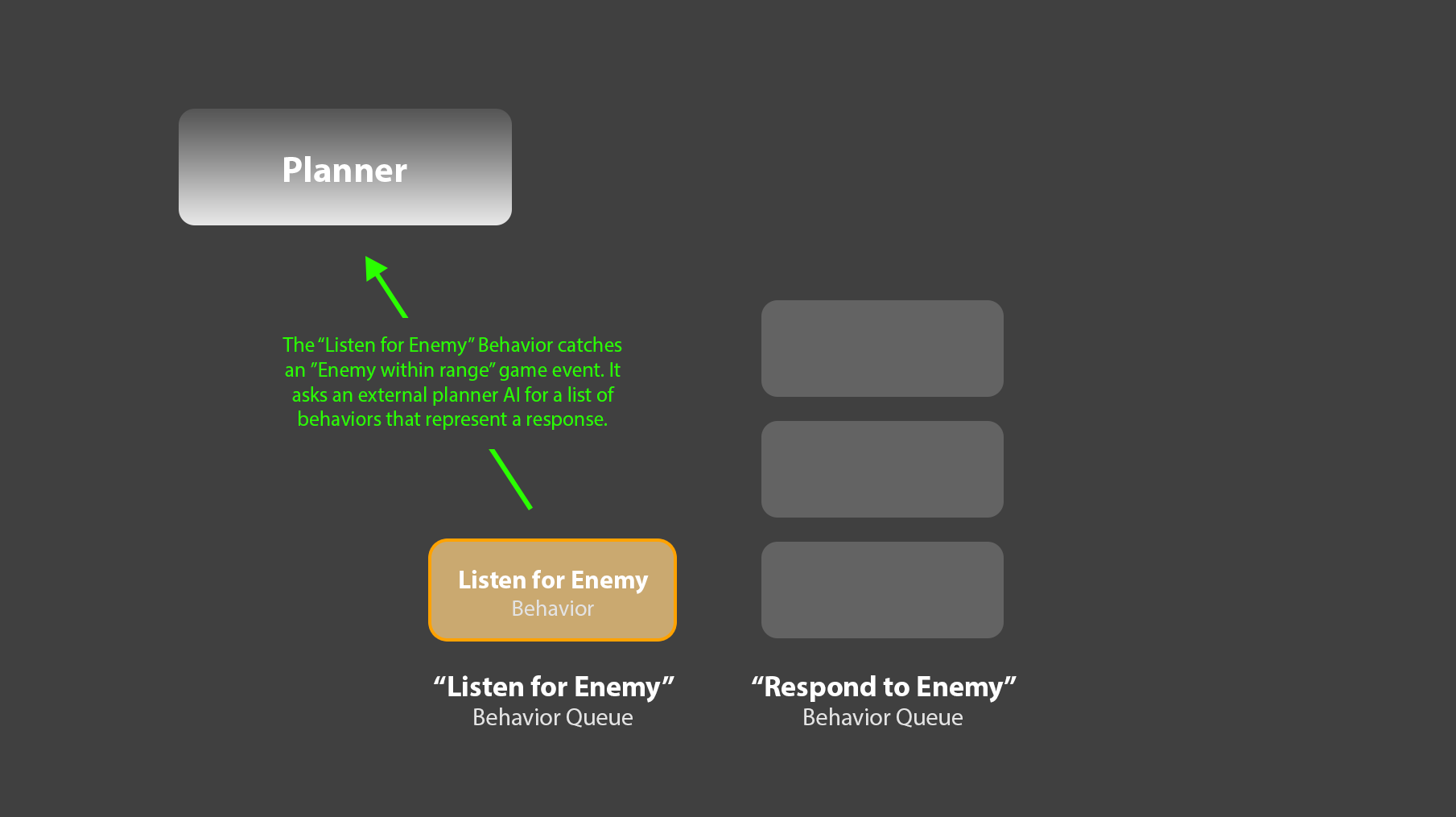
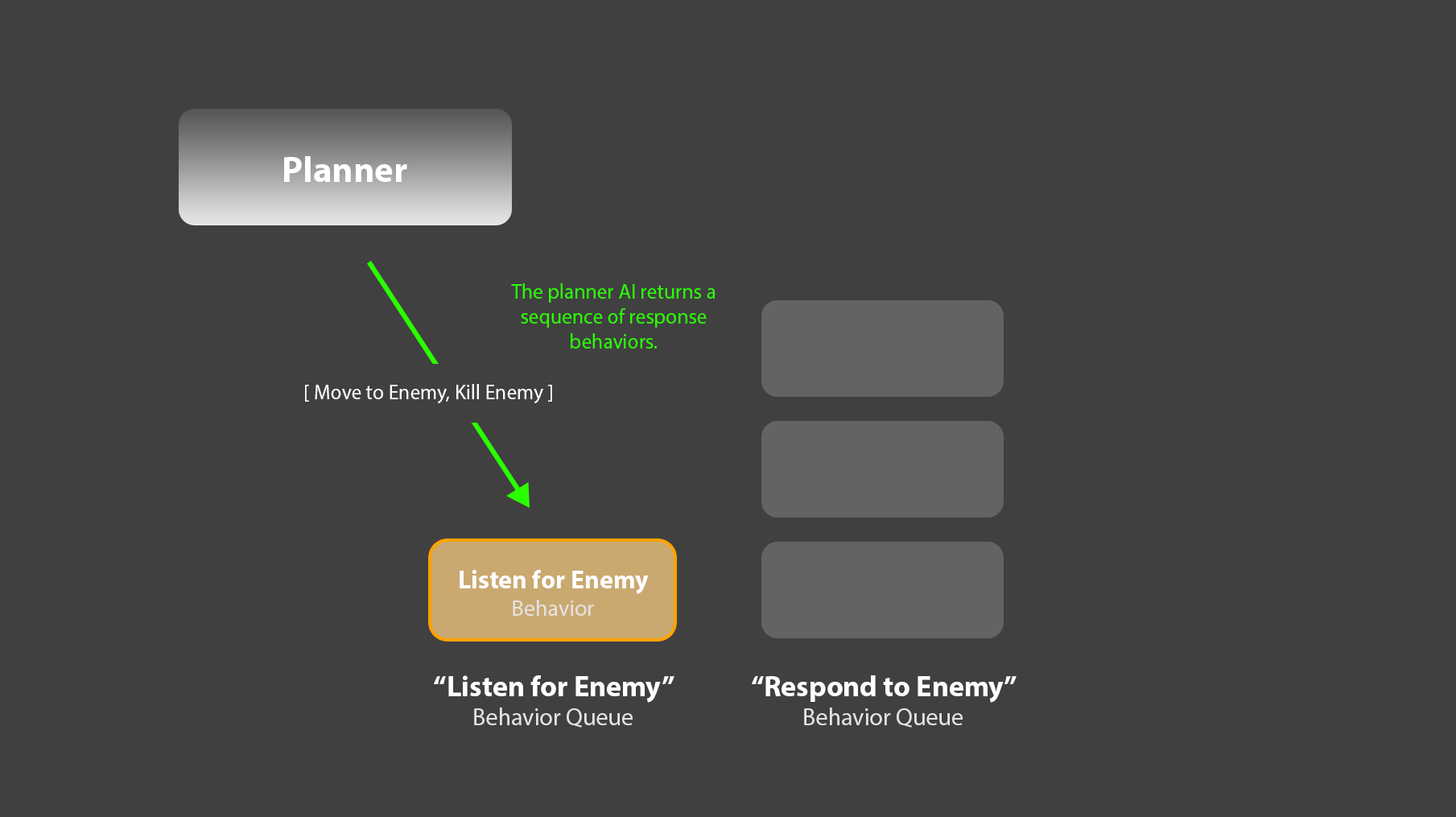
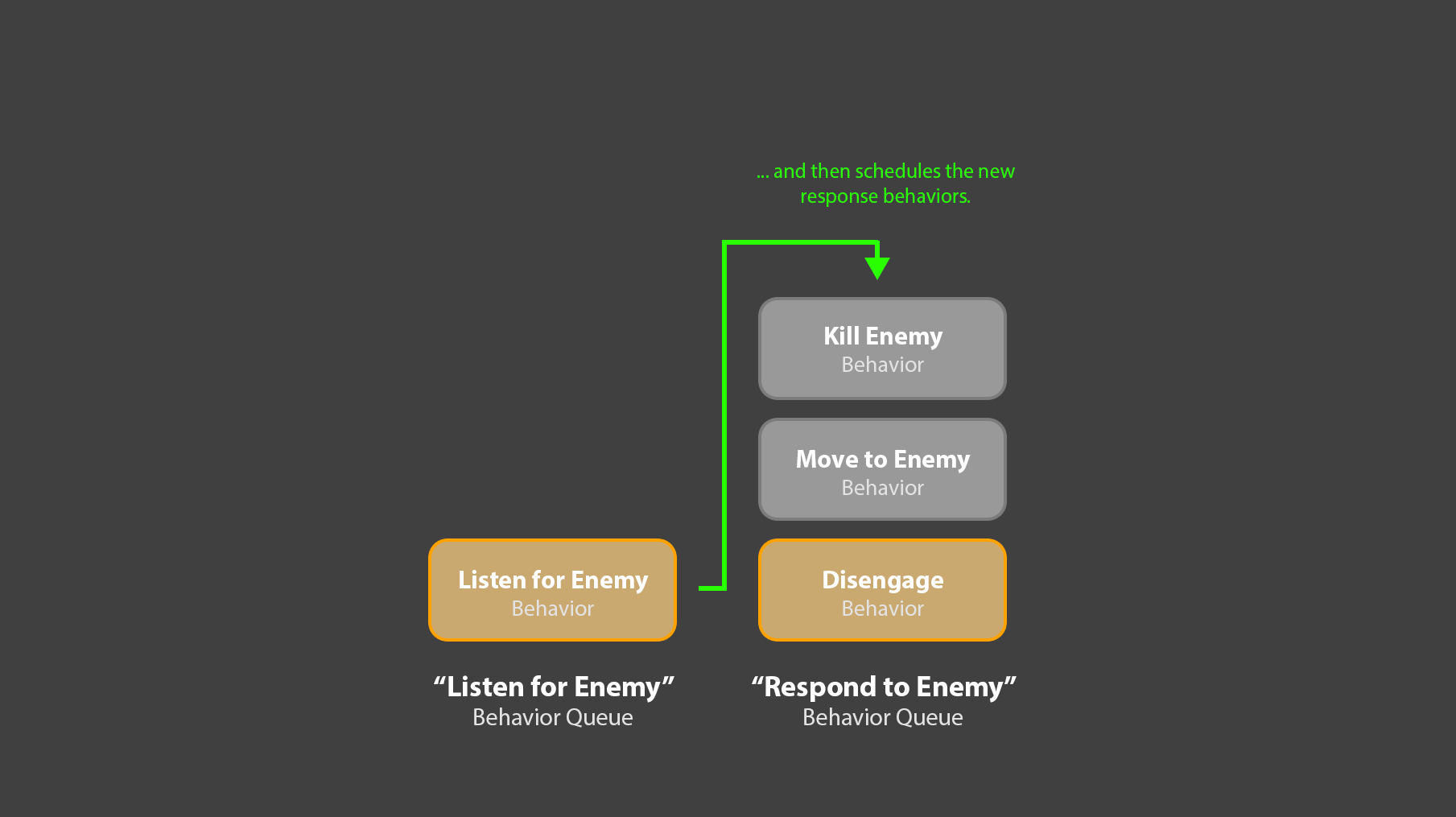
4. For example: One queue, “Listen for Enemies”, could have a length of 1, and run a single behavior which never completes. This behavior would listen for enemy game events, for example, “Enemy within range”. Upon catching such an event, it could ask a separate planner system for an appropriate response, in the form of a sequence of behaviors. For example, this response might look like:
[“Move to Enemy”, “Kill Enemy”]
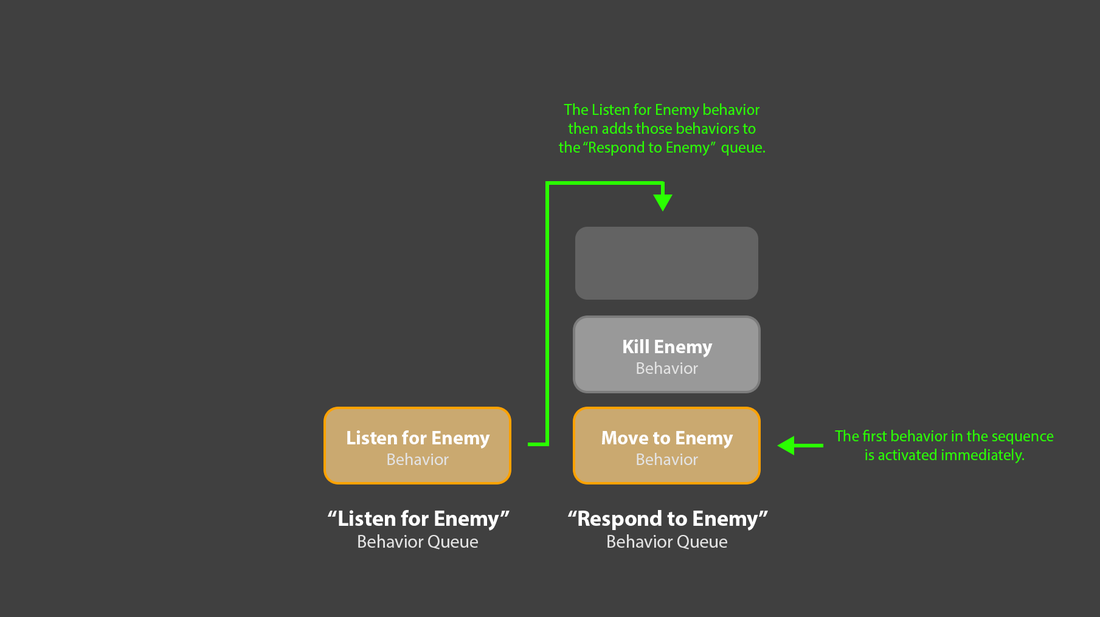
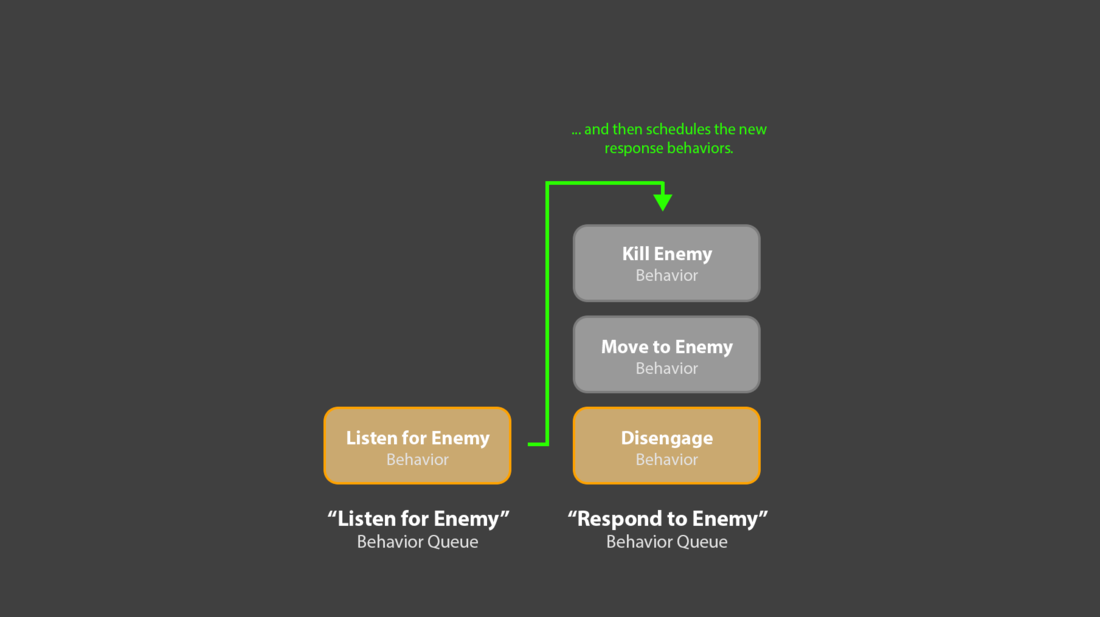
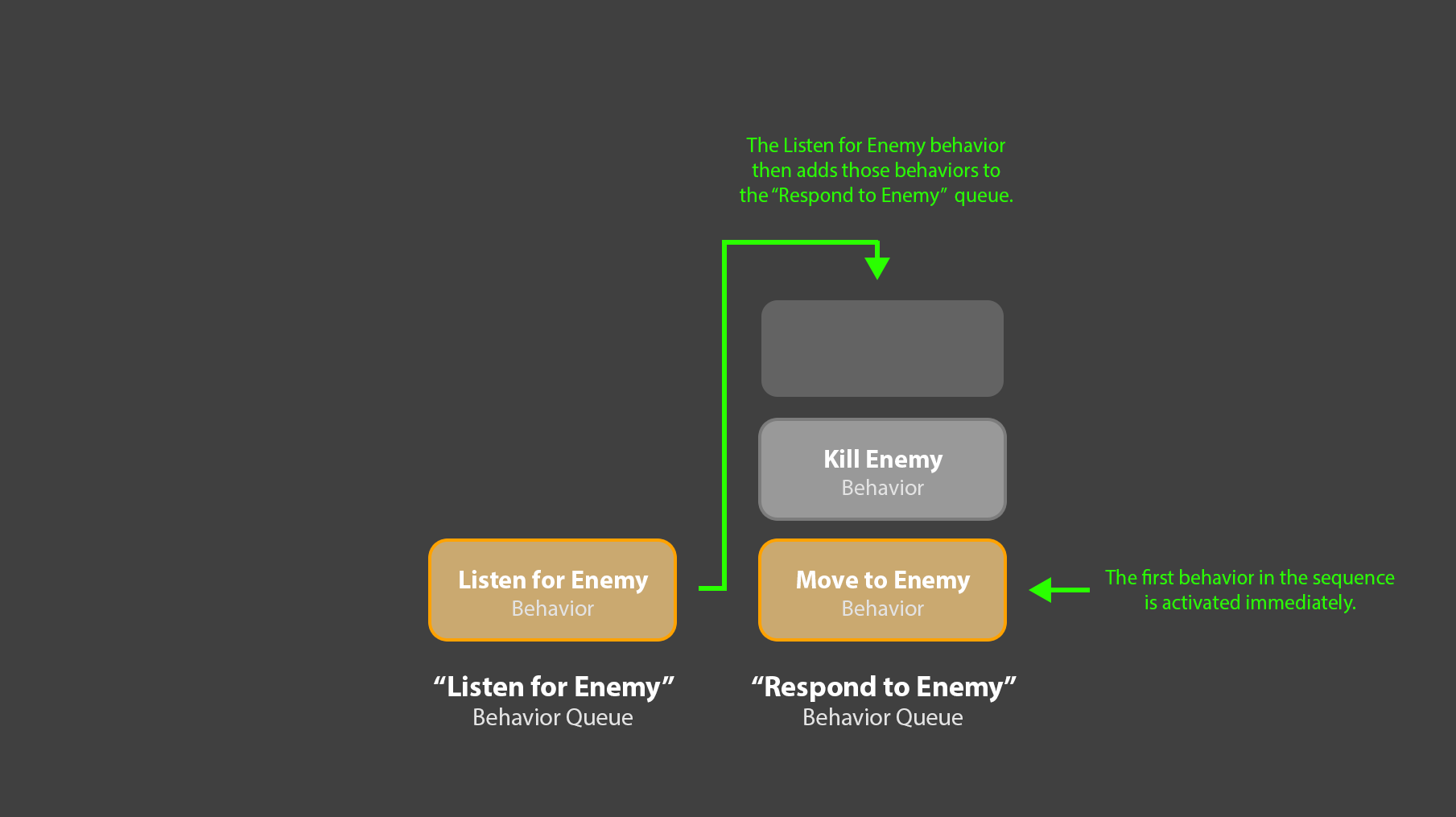
5. The “Listen for Enemies” queue could then take that sequence of ‘response’ behaviors, and add them to a second, “Respond to Enemies” behavior queue. That sequence of behaviors would then immediately begin executing.
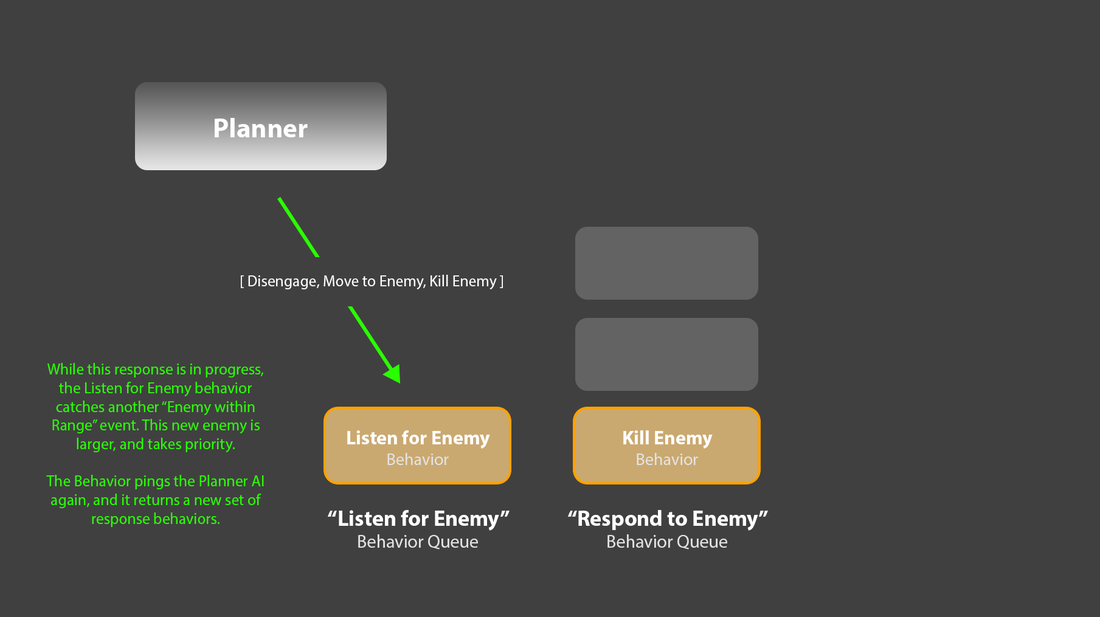
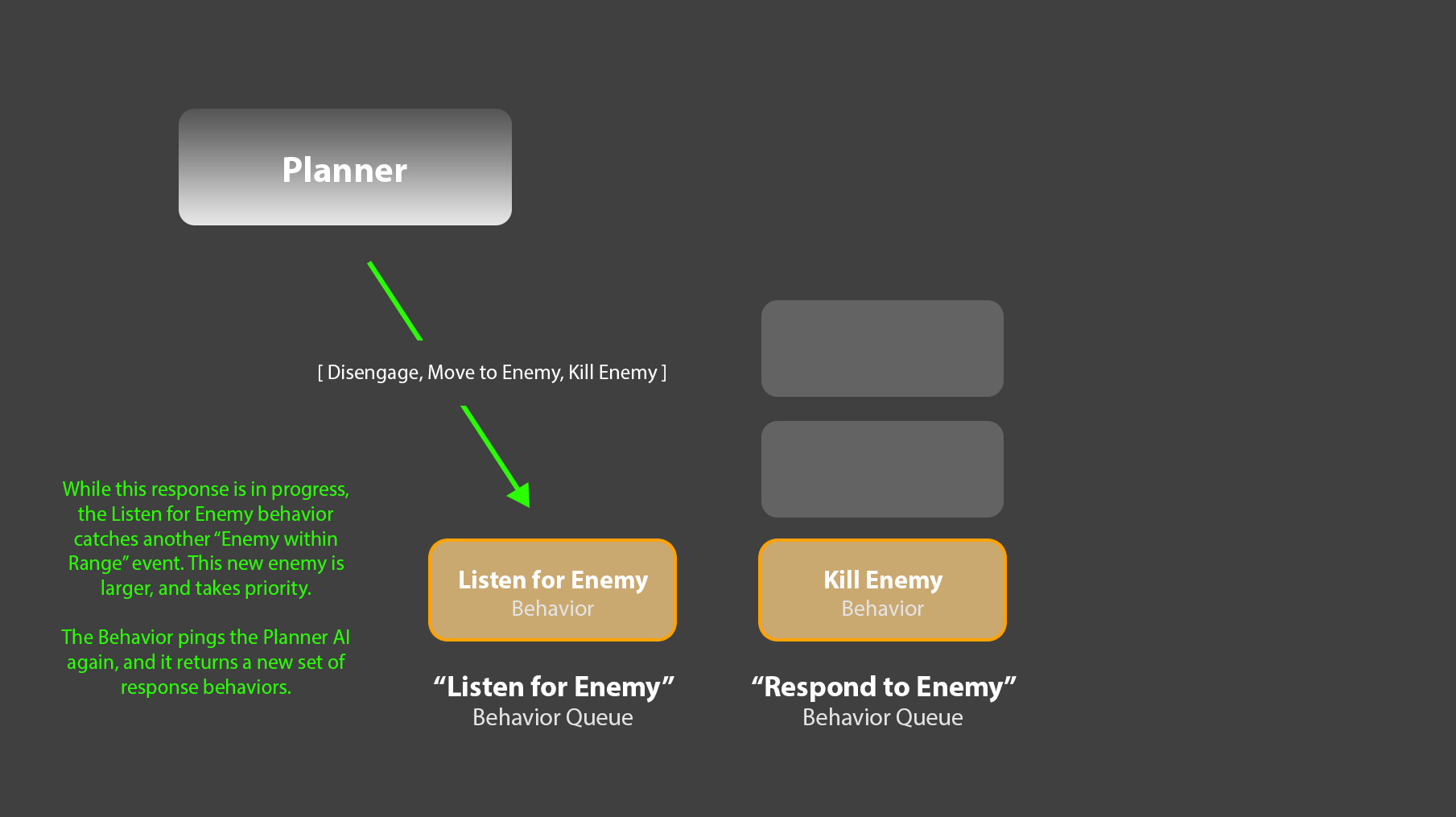
6. Crucially, the original “Listen for Enemies” behavior would still be active, back in its own queue. If another, bigger enemy appeared, it could ask the planner for the new set of response behaviors, clear out any remaining behaviors in the “Response” queue, and replace them with the new sequence.
7. This “Listen for Enemies” behavior could also listen for enemy death events, and clear the “Response” queue if the target enemy has died. That approach is how I’ve generally avoided the “agent whacking away at nothing” problem you described in your comment.
- - -
A few more notes about behavior queues, for posterity:
-
In my implementation, each behavior queue has its own blackboard structure, which its active behavior can use to store some state data. The agent itself also has a blackboard, which multiple behaviors can use to communicate with each other.
-
In my code, each behavior queue can have a set of tags. This makes it simple to do thing like “pause all behavior queues dealing with movement”, for example.
-
beyond clearing a behavior queue, a new behavior can be inserted at any index in a queue. So for example, an agent with a plan to interact with ‘thing A’, and then ‘thing B’ could have new behaviors inserted in the middle of the queue to give it a third stop along the way.
Do you have any thoughts on this pattern? How does this compare to what's already out there for handling task execution work?
Regardless, thank you for reading such a long post. ")
(Apologies for the image spam below. I don't know how to make these appear smaller. ?)