
A simple single unit adaptive network:
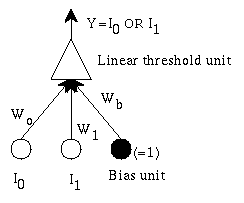
The network has 2 inputs, and one output. All are binary. The output
is
1 if W0 *I0 + W1 * I1+ Wb > 0
0 if W0 *I0 + W1 * I1+ Wb <= 0
We want it to learn simple OR: output a 1 if either I0 or I1 is 1.
For Solving this problem i have made this-
#include <iostream>
struct Newron
{
int value;
int weight;
};
int main()
{
Newron input_one, input_two, output;
int bias = 0;
input_one.weight = 1;
input_two.weight = 1;
std::cin >> input_one.value;
std::cin >> input_two.value;
output.value = (input_one.value * input_one.weight) + (input_two.value * input_two.weight) + bias;
if(output.value > 0)
std::cout << 1 << std::endl;
else
std::cout << 0 << std::endl;
return 0;
}
Is it the right way?
If not then how it can be done?
Thanks for your help in advance.


")

 )
)")





