
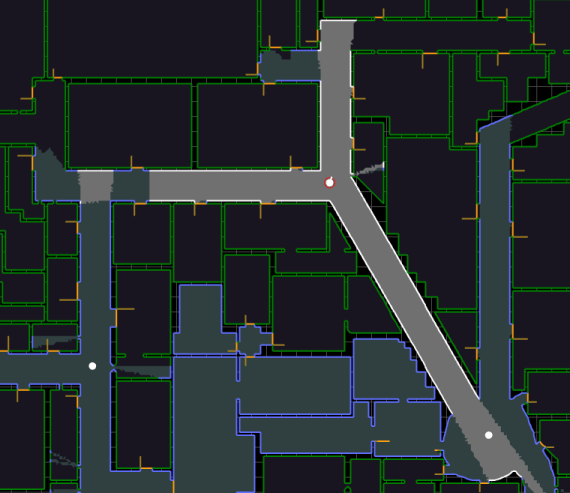
 Figure 1 - A simple example of a map
Figure 1 - A simple example of a map
 Figure 2 - You are in a maze of twisty triangles, all largely the same
Figure 2 - You are in a maze of twisty triangles, all largely the same
 Figure 3 - A "polygon" of light, with curved parts
Figure 3 - A "polygon" of light, with curved parts
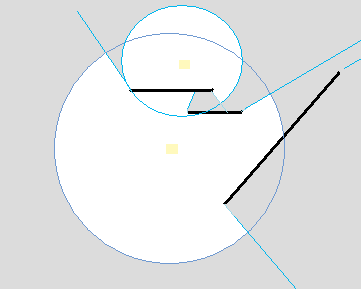 Figure 4 - Union of two lit areas
Figure 4 - Union of two lit areas
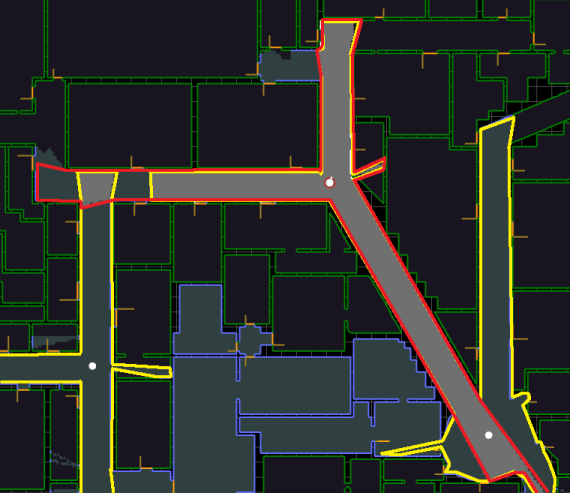 Figure 5 - Vision and Light compute Visibility
Figure 5 - Vision and Light compute Visibility
 Figure 6 - Columns, a Wall, and A Messy Polygon Union
Figure 6 - Columns, a Wall, and A Messy Polygon Union
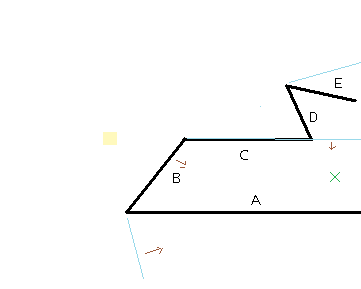
Figure 7 - Walls that do, and don't, matter
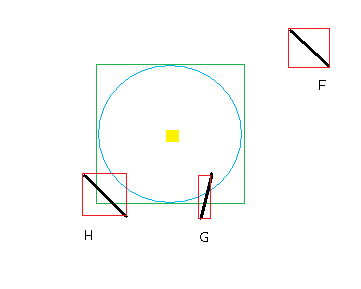
Figure 8 - Using rectangles and overlap to discard walls
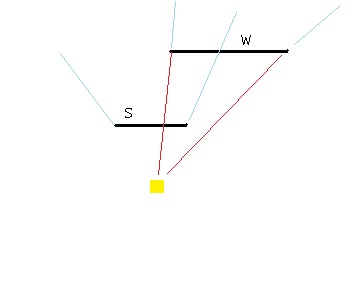
Figure 9 - Intersecting origin-to-endpoint with other walls
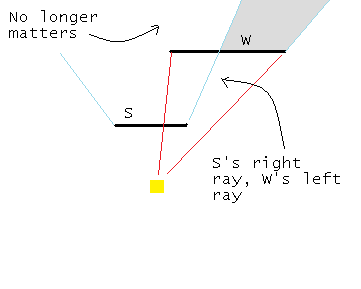
Figure 10 - Pushing W's left ray
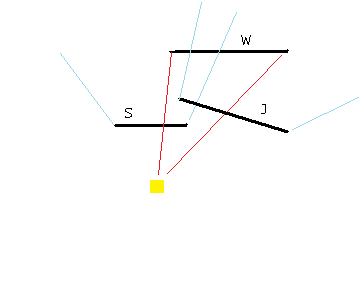
Figure 11 - Losing W
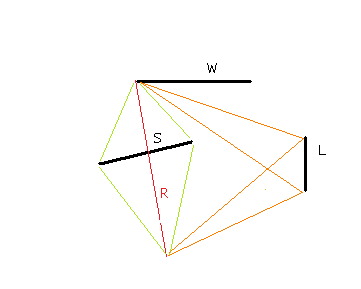
Figure 12 - Detecting intersections
Making it faster
Make sure all we just discussed makes sense to you, because we're about to add some complications. There are four optimizations that can be applied to all this, unrelated to each other. 1. In my maps, walls (except doors) always touch one other wall at their endpoint. (They are really wall surfaces - just as in a 3D model, all the surface polygons are just that, surfaces, always touching neighbor surfaces along edges.) This leads to an optimization, though it is a little fussy to apply. An example serves best. Imagine you're a light at the origin, and over at x=5 there's a wall stretching from (5,0) to (5,5), running north and south. It casts an obvious shadow to the east. We'll call that wall A. But imagine that at (5,5) there's another wall, running to (4,6), diagonally to the northwest. Call it B.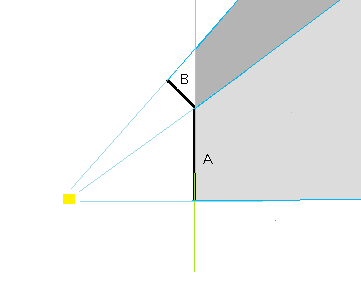 Figure 13 - Extending A's influence
Figure 13 - Extending A's influence
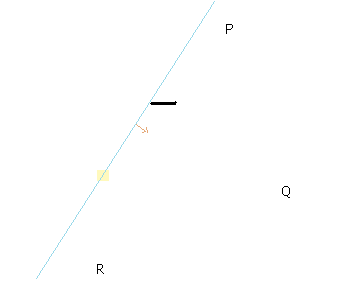 Figure 14 - The futility of any one test
Figure 14 - The futility of any one test
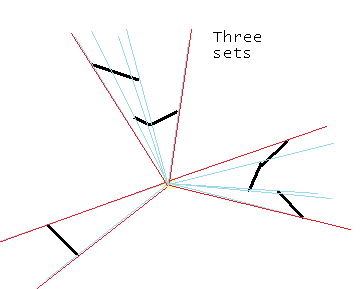 Figure 15 - Creating sets of shaodw wedges
Figure 15 - Creating sets of shaodw wedges
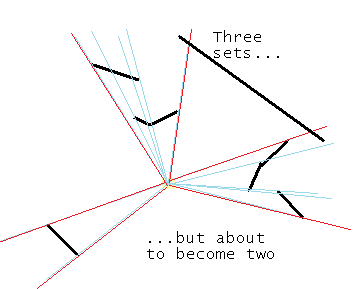 Figure 16 - Combining sets
Figure 16 - Combining sets
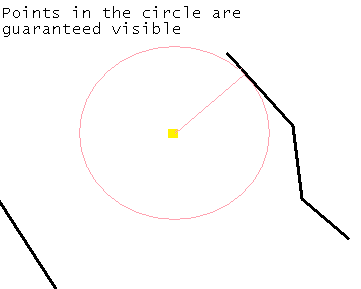 Figure 17 - Identifying points unaffected by walls
Figure 17 - Identifying points unaffected by walls
 Figure 18 - Neighbors often suffer the same fate
Figure 18 - Neighbors often suffer the same fate
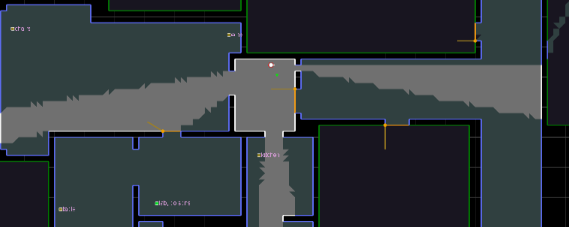 Figure 19 - Room in underground city
Figure 19 - Room in underground city
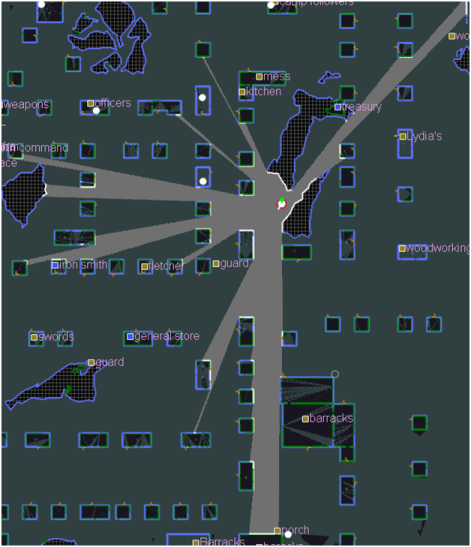 Figure 20 - Ambient light, buildings and rock outcrops
Figure 20 - Ambient light, buildings and rock outcrops
 Figure 21 - Limited lights, windows and doors
Figure 21 - Limited lights, windows and doors
Code Listing
What follows gives the general sense of the algorithms' implementation. Do note that the code is not compiler-ready: support classes like Point, Wall, WallSeg and SimpleTriangle are not provided, but their implementation is reasonably obvious. This code is released freely and for any purpose, commercial or private - it's free and I don't care what happens, nor do I need to be told. It is also without any warranty or promise of fitness, obviously. It works in my application as far as I know, and with some adjustment, may work in yours. The comments will show some of the battles that occurred in getting it to work. The code may contain optimizations I didn't discuss above. enum Clockness {Straight, Clockwise, Counterclockwise}; enum Facing {Colinear, Inside, Outside}; static inline Clockness clocknessOrigin(const Point& p1, const Point& P2) { const float a = p1.x * P2.y - P2.x * p1.y; if (a > 0) return Counterclockwise; // aka left if (a < 0) return Clockwise; return Straight; } static inline bool clocknessOriginIsCounterClockwise(const Point& p1, const Point& P2) { return p1.x * P2.y - P2.x * p1.y > 0; } static inline bool clocknessOriginIsClockwise(const Point& p1, const Point& P2) { return p1.x * P2.y - P2.x * p1.y < 0; } class LineSegment { public: Point begin_; Point vector_; //begin_+vector_ is the end point inline LineSegment(const Point& begin, const Point& end) : begin_(begin), vector_(end - begin) {} inline const Point& begin() const {return begin_;} inline Point end() const {return begin_ + vector_;} inline LineSegment(){} //We don't care *where* they intersect and we want to avoid divides and round off surprises. //So we don't attempt to solve the equations and check bounds. //We form a quadilateral with AB and CD, in ACBD order. This is a convex kite shape if the // segments cross. Anything else isn't a convex shape. If endpoints touch, we get a triangle, //which will be declared convex, which works for us. //Tripe about changes in sign in deltas at vertex didn't work. //life improves if a faster way is found to do this, but it has to be accurate. bool doTheyIntersect(const LineSegment &m) const { Point p[4]; p[0] = begin(); p[1] = m.begin(); p[2] = end(); p[3] = m.end(); unsigned char flag = 0; { float z = (p[1].x - p[0].x) * (p[2].y - p[1].y) - (p[1].y - p[0].y) * (p[2].x - p[1].x); if (z > 0) flag = 2; else if (z < 0) flag = 1; } { float z = (p[2].x - p[1].x) * (p[3].y - p[2].y) - (p[2].y - p[1].y) * (p[3].x - p[2].x); if (z > 0) flag |= 2; else if (z < 0) flag |= 1; if (flag == 3) return false; } { float z = (p[3].x - p[2].x) * (p[0].y - p[3].y) - (p[3].y - p[2].y) * (p[0].x - p[3].x); if (z > 0) flag |= 2; else if (z < 0) flag |= 1; if (flag == 3) return false; } { float z = (p[0].x - p[3].x) * (p[1].y - p[0].y) - (p[0].y - p[3].y) * (p[1].x - p[0].x); if (z > 0) flag |= 2; else if (z < 0) flag |= 1; } return flag != 3; } inline void set(const Point& begin, const Point& end) { begin_ = begin; vector_ = end - begin; } inline void setOriginAndVector(const Point& begin, const Point& v) { begin_ = begin; vector_ = v; } /* Given this Line, starting from begin_ and moving towards end, then turning towards P2, is the turn clockwise, counterclockwise, or straight? Note: for a counterclockwise polygon of which this segment is a side, Clockwise means P2 would "light the outer side" and Counterclockwise means P2 would "light the inner side". Straight means colinear. */ inline Clockness clockness(const Point& P2) const { const float a = vector_.x * (P2.y - begin_.y) - (P2.x - begin_.x) * vector_.y; if (a > 0) return Counterclockwise; // aka left if (a < 0) return Clockwise; return Straight; } inline bool clocknessIsClockwise(const Point& P2) const { return vector_.x * (P2.y - begin_.y) - (P2.x - begin_.x) * vector_.y < 0; } //relative to origin inline Clockness myClockness() const {return clocknessOrigin(begin(), end());} inline bool clockOK() const {return myClockness() == Counterclockwise;} //is clockOK(), this is true if p and center are on opposide sides of me //if p is on the line, this returns false inline bool outside(const Point p) const { return clockness(p) == Clockwise; } inline bool outsideOrColinear(const Point p) const { return clockness(p) != Counterclockwise; } void print() const { begin().print(); printf(" to "); end().print(); } }; class Wall; /* A wedge is a line segment that denotes a wall, and two rays from the center, that denote the relevant left and right bound that matter when looking at this wall. Initially, the left and right bound are set from the wall's endpoints, as those are the edges of the shadow. But walls in front of (eg, centerward) of this wall might occlude the end points, and we detect that when we add this wedge. If it happens, we use the occluding wall's endpoints to nudge our own shadow rays. The idea is to minimise the shadow bounds of any given wall by cutting away areas that are already occluded by closer walls. That way, a given point to test can often avoid being tested against multiple, overlapping areas. More important, if we nudge the effective left and right rays for this wall until they meet or pass each other, that means this wall is completely occluded, and we can discard it entirely, which is the holy grail of this code. Fewer walls means faster code. For any point that's between the effective left and right rays of a given wall, the next question is if it's behind the wall. If it is, it's definitively occluded and we don't need to test it any more. Otherwise, on to the next wall. */ class AggregateWedge; enum VectorComparison {ColinearWithVector, RightOfVector, OppositeVector, LeftOfVector}; static VectorComparison compareVectors(const Point& reference, const Point& point) { switch (clocknessOrigin(reference, point)) { case Clockwise: return RightOfVector; case Counterclockwise: return LeftOfVector; } if (reference.dot(point) > 0) return ColinearWithVector; return OppositeVector; } class LittleTree { public: enum WhichVec {Left2, Right1, Right2} whichVector; //(sort tie-breaker), right must be greater than left const Point* position; //vector end LittleTree* greater; //that is, further around to the right LittleTree* lesser; //that is, less far around to the right LittleTree() {greater = lesser = NULL;} void readTree(WhichVec* at, int* ip) { if (lesser) lesser->readTree(at, ip); at[*ip] = whichVector; ++*ip; if (greater) greater->readTree(at, ip); } //walk the tree in order, filling an array void readTree(WhichVec* at) { int i = 0; readTree(at, &i); } }; class VectorPair { public: Point leftVector; Point rightVector; bool acute; VectorPair() {} VectorPair(const Point& left, const Point& right) { leftVector = left; rightVector = right; acute = true; } bool isAllEncompassing() const {return leftVector.x == 0 && leftVector.y == 0;} void set(const Point& left, const Point& right) { leftVector = left; rightVector = right; acute = clocknessOrigin(leftVector, rightVector) == Clockwise; } void setKnownAcute(const Point& left, const Point& right) { leftVector = left; rightVector = right; acute = true; } void setAllEncompassing() { acute = false; leftVector = rightVector = Point(0,0); } bool isIn(const Point p) const { if (acute) return clocknessOrigin( leftVector, p) != Counterclockwise && clocknessOrigin(rightVector, p) != Clockwise; //this accepts all points if leftVector == 0,0 return clocknessOrigin( leftVector, p) != Counterclockwise || clocknessOrigin(rightVector, p) != Clockwise; } //true if we adopted the pair into ourselves. False if disjoint. bool update(const VectorPair& v) { /* I might completely enclose him - that means no change I might be completely disjoint - that means no change, but work elsewhere He might enclose all of me - I take on his bounds We could overlap; I take on some of his bounds -- We figure this by starting at L1 and moving clockwise, hitting (in some order) R2, L2 and R1. Those 3 can appear in any order as we move clockwise, and some can be colinear (in which case, we pretend a convenient order). Where L1 and R1 are the bounds we want to update, we have 6 cases: L1 L2 R1 R2 - new bounds are L1 R2 (ie, update our R) L1 L2 R2 R1 - no change, L1 R1 already encloses L2 R2 L1 R1 L2 R2 - the pairs are disjoint, no change, but a new pair has to be managed L1 R1 R2 L2 - new bounds are L2 R2; it swallowed us (update both) L1 R2 L2 R1 - all encompassing; set bounds both to 0,0 L1 R2 R1 L2 - new bounds are L2 R1 (ie, update our L) If any two rays are colinear, sort them so that left comes first, then right. If 2 lefts or 2 rights, order doesn't really matter. The left/right case does because we want L1 R1 L2 R2, where R1=L2, to be processed as L1 L2 R1 R2 (update R, not disjoint) */ //special cases - if we already have the whole circle, update doesn't do anything if (isAllEncompassing()) return true; //v is part of this wedge (everything is) //if we're being updated by a full circle... if (v.isAllEncompassing()) { setAllEncompassing(); //we become one return true; } /* Now we just need to identify which order the 3 other lines are in, relative to L1. Not so easy since we don't want to resort to arctan or anything else that risks any roundoff. But clockness from L1 puts them either Clockwise (sooner), or Straight (use dot product to see if same as L1 or after Clockwise), or CounterClockwise (later). Within that, we can use clockness between points to sort between them. */ //get the points R1, L2 and R2 listed so we can sort them by how far around to the right // they are from L1 LittleTree list[3]; //order we add them in here doesn't matter list[0].whichVector = LittleTree::Right1; list[0].position = &this->rightVector; list[1].whichVector = LittleTree::Left2; list[1].position = &v.leftVector list[2].whichVector = LittleTree::Right2; list[2].position = &v.rightVector //[0] will be top of tree; add in 1 & 2 under it somewhere for (int i = 1; i < 3; ++i) { LittleTree* at = &list[0]; do { bool IisGreater = list.whichVector > at->whichVector; //default if nothing else works VectorComparison L1ToAt = compareVectors(leftVector, *at->position); VectorComparison L1ToI = compareVectors(leftVector, *list.position); if (L1ToI < L1ToAt) IisGreater = false; else if (L1ToI > L1ToAt) IisGreater = true; else { if (L1ToI != OppositeVector && L1ToI != ColinearWithVector) { //they are in the same general half circle, so this works switch (clocknessOrigin(*at->position, *list.position)) { case Clockwise: IisGreater = true; break; case Counterclockwise: IisGreater = false; break; } } } //now we know where goes (unless something else is there) if (IisGreater) { if (at->greater == NULL) { at->greater = &list; break; //done searching for 's place } at = at->greater; continue; } if (at->lesser == NULL) { at->lesser = &list; break; //done searching for 's place } at = at->lesser; continue; } while (true); } //we have a tree with proper order. Read out the vector ids LittleTree::WhichVec sortedList[3]; list[0].readTree(sortedList); unsigned int caseId = (sortedList[0] << 2) | sortedList[1]; //form ids into a key. Two is enough to be unique switch (caseId) { case (LittleTree::Left2 << 2) | LittleTree::Right2: //L1 L2 R2 R1 return true; //no change, we just adopt it case (LittleTree::Right1 << 2) | LittleTree::Left2: //L1 R1 L2 R2 return false; //disjoint! case (LittleTree::Right1 << 2) | LittleTree::Right2: //L1 R1 R2 L2 *this = v; return true; //we take on his bounds case (LittleTree::Right2 << 2) | LittleTree::Left2: //L1 R2 L2 R1 setAllEncompassing(); return true; //now we have everything case (LittleTree::Left2 << 2) | LittleTree::Right1: //L1 L2 R1 R2 rightVector = v.rightVector; break; default: //(LittleTree::Right2 << 2) | LittleTree::Right1: //L1 R2 R1 L2 leftVector = v.leftVector; break; } //we need to fix acute acute = clocknessOrigin(leftVector, rightVector) == Clockwise; return true; } }; class Wedge { public: //all points relative to center LineSegment wall; //begin is the clockwise, right hand direction Point leftSideVector; //ray from center to this defines left or "end" side Wedge* leftSidePoker; //if I'm updated, who did it Point rightSideVector; //ray from center to this defines left or "end" side Wedge* rightSidePoker; //if I'm updated, who did it Wall* source; //original Wall of .wall VectorPair outVectors; float nearestDistance; //how close wall gets to origin (squared) AggregateWedge* myAggregate; //what am I part of? inline Wedge(): source(NULL), leftSidePoker(NULL), rightSidePoker(NULL), myAggregate(NULL) {} void setInitialVectors() { leftSidePoker = rightSidePoker = NULL; rightSideVector = wall.begin(); leftSideVector = wall.end(); outVectors.setKnownAcute(wall.end(), wall.begin()); } inline bool testOccluded(const Point p, const float distSq) const //relative to center { if (distSq < nearestDistance) return false; //it cannot if (clocknessOriginIsCounterClockwise(leftSideVector, p)) return false; //not mine if (clocknessOriginIsClockwise(rightSideVector, p)) return false; //not mine return wall.outside(p); //on the outside } inline bool testOccludedOuter(const Point p, const float distSq) const //relative to center { if (distSq < nearestDistance) //this helps a surprising amount in at least Enya return false; //it cannot return wall.outside(p) && outVectors.isIn(p); //on the outside } inline bool nudgeLeftVector(Wedge* wedge) { /* So. wedge occludes at least part of my wall, on the left side. It might actually be the case of an adjacent wall to my left. If so, my end() is his begin(). And if so, I can change HIS rightSideVectorOut to my right (begin) point, assuming my begin point is forward of (or on) his wall. That means he can help kill other walls better. */ if (wedge->wall.begin() == wall.end() && !wedge->wall.outside(wall.begin())) //is it legal? { outVectors.update(VectorPair(wedge->wall.end(), wedge->wall.begin())); wedge->outVectors.update(VectorPair(wall.end(), wall.begin())); } //turning this on drives the final wedge down, but not very much bool okToDoOut = true; bool improved = false; do { if (wall.outside(wedge->wall.begin())) break; //illegal move, stop here if (clocknessOrigin(leftSideVector, wedge->wall.begin()) == Clockwise) { leftSideVector = wedge->wall.begin(); leftSidePoker = wedge; improved = true; } if (okToDoOut) { okToDoOut = !wall.outside(wedge->wall.end()); if (okToDoOut) outVectors.update(VectorPair(wedge->wall.end(), wall.begin())); } wedge = wedge->rightSidePoker; } while (wedge); return improved; } inline bool nudgeRightVector(Wedge* wedge) { /* So. wedge occludes at least part of my wall, on the right side. It might actually be the case of an adjacent wall to my right. If so, my begin() is his end(). And if so, I can change HIS leftSideVectorOut to my left (end() point, assuming my begin point is forward of (or on) his wall. That means he can help kill other walls better. */ if (wedge->wall.end() == wall.begin() && !wedge->wall.outside(wall.end())) //is it legal? { outVectors.update(VectorPair(wedge->wall.end(), wedge->wall.begin())); wedge->outVectors.update(VectorPair(wall.end(), wall.begin())); } //turning this on drives the final wedge count down, but not very much bool okToDoOut = true; bool improved = false; do { if (wall.outside(wedge->wall.end())) return improved; //illegal move if (clocknessOrigin(rightSideVector, wedge->wall.end()) == Counterclockwise) { rightSideVector = wedge->wall.end(); rightSidePoker = wedge; improved = true; } if (okToDoOut) { okToDoOut = !wall.outside(wedge->wall.begin()); if (okToDoOut) outVectors.update(VectorPair(wall.end(), wedge->wall.begin())); } wedge = wedge->leftSidePoker; } while (wedge); return improved; } }; class AggregateWedge { public: VectorPair vectors; AggregateWedge* nowOwnedBy; bool dead; AggregateWedge() : nowOwnedBy(NULL), dead(false) {} bool isIn(const Point& p) const { return vectors.isIn(p); } bool isAllEncompassing() const {return vectors.leftVector.x == 0 && vectors.leftVector.y == 0;} void init(Wedge* w) { vectors.setKnownAcute(w->leftSideVector, w->rightSideVector); w->myAggregate = this; nowOwnedBy = NULL; dead = false; } //true if it caused a merge bool testAndAdd(Wedge* w) { if (dead) //was I redirected? return false; //then I don't do anything if (!vectors.update(VectorPair(w->wall.end(), w->wall.begin()))) return false; //disjoint AggregateWedge* previousAggregate = w->myAggregate; w->myAggregate = this; //now I belong to this if (previousAggregate != NULL) //then it's a merge { vectors.update(previousAggregate->vectors); //That means we have to redirect that to this assert(previousAggregate->nowOwnedBy == NULL); previousAggregate->nowOwnedBy = this; previousAggregate->dead = true; return true; } return false; } }; class AggregateWedgeSet { public: int at; int firstValid; AggregateWedge agList[8192]; float minDistanceSq; float maxDistanceSq; AggregateWedgeSet() : minDistanceSq(0), maxDistanceSq(FLT_MAX) {} void add(int numberWedges, Wedge* wedgeList) { at = 0; for (int j = 0; j < numberWedges; ++j) { Wedge* w = wedgeList + j; w->myAggregate = NULL; //none yet bool mergesHappened = false; for (int i = 0; i < at; ++i) mergesHappened |= agList.testAndAdd(w); if (mergesHappened) { //some number of aggregates got merged into w->myAggregate //We need to do fixups on the wedges' pointers for (int k = 0; k < j; ++k) { AggregateWedge* in = wedgeList[k].myAggregate; if (in->nowOwnedBy) //do you need an update? { in = in->nowOwnedBy; while (in->nowOwnedBy) //any more? in = in->nowOwnedBy; wedgeList[k].myAggregate = in; } } for (int k = 0; k < at; ++k) agList[k].nowOwnedBy = NULL; } if (w->myAggregate == NULL) //time to start a new one { agList[at++].init(w); } } // all wedges in minDistanceSq = FLT_MAX; for (int j = 0; j < numberWedges; ++j) { //get nearest approach float ds = wedgeList[j].nearestDistance; if (ds < minDistanceSq) minDistanceSq = ds; } minDistanceSq -= 0.25f; //fear roundoff - pull this is a little firstValid = 0; for (int i = 0; i < at; ++i) if (!agList.dead) { firstValid = i; #if 0 // Not sure this is working? Maybe relates to using L to change bounds? //if this is the only valid wedge and it is all-encompassing, then we can //walk all the wedges and find the furthest away point (which will be some //wall endpoint). Anything beyond that cannot be in bounds. if (agList.isAllEncompassing()) { maxDistanceSq = 0; for (int j = 0; j < numberWedges; ++j) { float ds = wedgeList[j].wall.begin().dotSelf(); if (ds > maxDistanceSq) maxDistanceSq = ds; ds = wedgeList[j].wall.end().dotSelf(); if (ds > maxDistanceSq) maxDistanceSq = ds; } } #endif break; } } const AggregateWedge* whichAggregateWedge(const Point p) const { for (int i = firstValid; i < at; ++i) { if (agList.dead) continue; if (agList.isIn(p)) { return agList + i; } } return NULL; } }; //#define UsingOuter //this slows us down. Do not use. #ifdef UsingOuter #define TheTest testOccludedOuter #else #define TheTest testOccluded #endif class AreaOfView { public: Point center; float radiusSquared; int numberWedges; BoundingRect bounds; Wedge wedges[8192]; //VERY experimental AggregateWedgeSet ags; inline AreaOfView(const Point& center_, const float radius) : center(center_), radiusSquared(radius * radius), numberWedges(0) { bounds.set(center, radius); addWalls(); } void changeTo(const Point& center_, const float radius) { center = center_; radiusSquared = radius * radius; bounds.set(center, radius); numberWedges = 0; addWalls(); } void recompute() //rebuild the wedges, with existing center and radius { bounds.set(center, sqrtf(radiusSquared)); numberWedges = 0; addWalls(); } inline bool isIn(Point p) const { p -= center; const float distSq = p.dotSelf(); if (distSq >= radiusSquared) return false; for (int i = 0; i < numberWedges; ++i) { if (wedges.TheTest(p, distSq)) return false; } return true; } /* On the theory that the wedge that rejected your last point has a higher than average chance of rejecting your next one, let the calling thread provide space to maintain the index of the last hit */ inline bool isInWithCheat(Point p, int* hack) const { p -= center; const float distSq = p.dotSelf(); if (distSq >= radiusSquared) return false; if (distSq < ags.minDistanceSq) return true; //this range is always unencumbered by walls if (distSq > ags.maxDistanceSq) //not working. Why? return false; if (numberWedges == 0) return true; //no boundaries //try whatever worked last time, first. It will tend to win again if (wedges[*hack].TheTest(p, distSq)) { return false; } #define UseAgg #define UseAggP #ifdef UseAgg const AggregateWedge* whichHasMe = ags.whichAggregateWedge(p); if (whichHasMe == NULL) return true; //can't be occluded! #endif //try everything else for (int i = 0; i < *hack; ++i) { #ifdef UseAggP #ifdef UseAgg if (wedges.myAggregate != whichHasMe) continue; #endif #endif if (wedges.TheTest(p, distSq)) { *hack = i; //remember what worked for next time return false; } } for (int i = *hack + 1; i < numberWedges ; ++i) { #ifdef UseAggP #ifdef UseAgg //does seem to help speed, but don't work yet if (wedges.myAggregate != whichHasMe) continue; #endif #endif if (wedges.TheTest(p, distSq)) { *hack = i; //remember what worked for next time return false; } } return true; } inline bool isInWithWallExclusion(Point p, const Wall* excludeWall) const { p -= center; const float distSq = p.dotSelf(); if (distSq >= radiusSquared) return false; for (int i = 0; i < numberWedges; ++i) { if (wedges.source == excludeWall)//this one doesn't count continue; if (wedges.TheTest(p, distSq )) return false; } return true; } void addWall(Wall* w, const float nearestDistance); void addWalls(); }; class AreaRef { public: AreaOfView* a; AreaRef() {a = NULL;} void set(const Point& p, float radius) { if (a == NULL) a = new AreaOfView(p, radius); else a->changeTo(p, radius); } ~AreaRef() {delete a;} void empty() {delete a; a = NULL;} AreaOfView* operator->() const {return a;} }; class WallSet { public: int length; int at; WallAndDist* list; WallSet() { at = 0; length = 2038; list = (WallAndDist*)malloc(length * sizeof(*list)); } ~WallSet() {free(list);} void add(Wall* w, const float distSq) { if (at >= length) { length *= 2; list = (WallAndDist*)realloc(list, length * sizeof(*list)); } list[at].wall = w; const LineSeg* s = w->getSeg(); list[at].lenSq = s->p[0].distanceSq(s->p[1]); list[at++].distSq = distSq; } inline void sortByCloseness() { qsort(list, at, sizeof *list, cmpWallDist); } }; void AreaOfView::addWall(Wall* w, const float nearestDistance) { if (numberWedges >= NUMOF(wedges)) return; //we are screwed const LineSeg* seg = w->getSeg(); Point w1 = seg->p[0] - center; Point w2 = seg->p[1] - center; LineSegment* wallSeg = &wedges[numberWedges].wall; switch (clocknessOrigin(w1, w2)) { case Clockwise: wallSeg->set(w2, w1); break; case Counterclockwise: wallSeg->set(w1, w2); break; default: return; //uninteresting, edge on } wedges[numberWedges].setInitialVectors(); //set left and right vectors from wall const LineSegment right(Point(0,0), wallSeg->begin()); const LineSegment left(Point(0,0), wallSeg->end()); //now we start trimming for (int i = 0; i < numberWedges; ++i) { //if this occludes both begin and it, it occludes the wall if (wedges.testOccludedOuter(wallSeg->begin(), wedges[numberWedges].nearestDistance) && wedges.testOccludedOuter(wallSeg->end(), wedges[numberWedges].nearestDistance)) return; bool changed = false; //test right side if (wedges.wall.doTheyIntersect(right)) { changed = wedges[numberWedges].nudgeRightVector(wedges + i); } //test left side if (wedges.wall.doTheyIntersect(left)) { changed |= wedges[numberWedges].nudgeLeftVector(wedges + i); } if (changed) { if (wedges[numberWedges].rightSidePoker && wedges[numberWedges].rightSidePoker == wedges[numberWedges].leftSidePoker) return; //cheap test for some total occlusion cases if ( //simplify LineSegment(Point(0,0), wedges[numberWedges].rightSideVector).clockness( wedges[numberWedges].leftSideVector) != Counterclockwise) { return; //occluded } } } //we have a keeper wedges[numberWedges].nearestDistance = nearestDistance; wedges[numberWedges].source = w; ++numberWedges; } void AreaOfView::addWalls() { //get the set of walls that can occlude. WallSet relevant; int initialRun = run1IsMapEdge? 2 : 1; for (int run = initialRun; run < wallRuns; ++run) { const WallRun* currentLoop = &wallLists[run]; //does this loop overlap our area? if (!currentLoop->bounds.overlapNonzero(bounds)) continue; //not an interesting loop, nothing in it can occlude //run 1 is the outer loop; we care about walls facing in. //subsequent runs are inner loops, and we care about walls facing out const Facing relevantFacing = run==1? Inside : Outside; //some walls in this loop may cast shadows. Here we go looking for them. for (int wall = 0; wall < currentLoop->wallCount; ++wall) { Wall* currentWall = currentLoop->list[wall]; //We don't currently have walls that are transparent (those are actually doors), but we could someday if (currentWall->isTransparent()) continue; //toss windows const LineSeg* currentSeg = currentWall->getSeg(); //We need to reject walls that are colinear with our rectangle bounds. //That's important because we don't want to deal with walls that *overlap* //any polygon sides; that complicates the intersection code. Walls don't // overlap other walls, and we will discard edge-on walls, so walls // don't overlap shadow lines; but without this they could overlap the // original bounding rectangle (the polygon-edge-of-last-resort). // We do have to consider overlap with creating shadows. // //Since we're looking at vertical and horisontal lines, which are pretty common, // we can also quickly discard those which are outside the rectangle, as well as // colinear with it. if (currentSeg->isVertical()) { if (currentSeg->p[0].x <= bounds.mins.x || currentSeg->p[0].x >= bounds.maxs.x) continue; } else if (currentSeg->isHorisontal() && (currentSeg->p[0].y <= bounds.mins.y || currentSeg->p[0].y >= bounds.maxs.y)) continue; //If the wall faces away from the center point, or is edge on, it // doesn't cast a shadow, so boot it. (Getting rid of edge-on stuff // avoids walls that overlap shadow lines). if (currentSeg->facing(center) != relevantFacing) continue; //faces away (or edge-on) //We still could be dealing with an angled wall that's entirely out of range - // and anyway we want to know the distances from the center to the line segment's // nearest point, so we can sort. //Getting the distance to a segment requires work. float distSq; if (currentSeg->p[1].dot(currentSeg->p[0], center) < 0) { //center is out beyond seg.p[1], so the distance is between p[1] and center distSq = center.distanceSq(currentSeg->p[1]); } else if (currentSeg->p[0].dot(currentSeg->p[1], center) < 0) { //center is out beyond seg.p[0], so the distance is between p[0] and center distSq = center.distanceSq(currentSeg->p[0]); } else { //distance from center to a perpendicular, dropped on the line segment //Our LineSeg class gives us a, b, c as Ax + By = C, so we adapt for -C float numerator = currentSeg->a * center.x + currentSeg->b * center.y + -currentSeg->c; float demonSq = currentSeg->a * currentSeg->a + currentSeg->b * currentSeg->b; distSq = numerator * numerator / demonSq; } //if the nearest point is outside or at the radius of interest, this wall can't matter. if (distSq >= radiusSquared) continue; //out of reach //Need to keep this one relevant.add(currentWall, distSq); } } //add doors, too. They don't have loops or bounding rectangles, and it's important to // get the right seg. Skip transparent ones. const WallRun* currentLoop = &wallLists[0]; //some walls in this loop may cast shadows. Here we go looking for them. for (int wall = 0; wall < currentLoop->wallCount; ++wall) { Wall* currentWall = currentLoop->list[wall]; if (currentWall->isTransparent()) continue; //toss windows const LineSeg* currentSeg = currentWall->getSeg(); //Horisontal and vertical lines are common, and easy to test for out of bounds. //That saves a more expensive distance check. if (currentSeg->isVertical()) { if (currentSeg->p[0].x <= bounds.mins.x || currentSeg->p[0].x >= bounds.maxs.x) continue; } else if (currentSeg->isHorisontal() && (currentSeg->p[0].y <= bounds.mins.y || currentSeg->p[0].y >= bounds.maxs.y)) continue; if (currentSeg->facing(center) == Straight) continue; //kill edge on walls float distSq; if (currentSeg->p[1].dot(currentSeg->p[0], center) < 0) { //center is out beyond seg.p[1], so the distance is between p[1] and center distSq = center.distanceSq(currentSeg->p[1]); } else if (currentSeg->p[0].dot(currentSeg->p[1], center) < 0) { //center is out beyond seg.p[0], so the distance is between p[0] and center distSq = center.distanceSq(currentSeg->p[0]); } else { //distance from center to a perpendicular, dropped on the line segment //Our LineSeg class gives us a, b, c as Ax + By = C, so we adapt for -C float numerator = currentSeg->a * center.x + currentSeg->b * center.y + -currentSeg->c; float demonSq = currentSeg->a * currentSeg->a + currentSeg->b * currentSeg->b; distSq = numerator * numerator / demonSq; } //if the nearest point is outside the radius of interest, this wall can't matter. if (distSq > radiusSquared) continue; //out of reach //Need to keep this one relevant.add(currentWall, distSq); } //sort by nearness; nearer ones should be done first, as that might make more walls //identifiably irrelevant. relevant.sortByCloseness(); //relevant.print(); //now, "do" each wall for (int i = 0; i < relevant.at; ++i) { addWall(relevant.list.wall, relevant.list.distSq); } //build the aggregate wedge list ags.add(numberWedges, wedges); #if 0 if (center == lastAtD) { char buf[256]; sprintf(buf, "%d wedges in set", numberWedges); MessageBox(gHwnd, buf, "Wedge Count", MB_OK); } #endif } static AreaRef areaOfView; static Number visionMaxDistance; static BoundingRect inView; static Point viewPoint; static unsigned char* changedTriangleFlags; static unsigned char changedLightFlags[NUMOF(lights)]; static bool inComputeVisible = false; //multithreaded, we do triangles i..lim-1 static inline void doVisibleWork(int i, const int lim) { //if the only lights on are at the viewpoint (and no superlight), and the //lights all stay within the visiion limit (they usually do) then we don't // have to do anything but copy the "lit" flag to the "you're visible" state. //That's a huge win; we do't have to consult the area of view bool soloLightRulesVisibility = !superLight; if (soloLightRulesVisibility) { for (int k = 0; k < NUMOF(lights); ++k) if (lights[k].on) { if (lights[k].p != lastAtD || lights[k].range() > vmd) { soloLightRulesVisibility = false; break; } } } if (soloLightRulesVisibility) { //what's visible here is simply what's lit. We just copy the lit flag, no math needed. for (; i < lim; ++i) { if (simpleTriList->setVisiblity( simpleTriList->lit() )) { unsigned char v = 0x4 | (simpleTriList->wasVisible << 1) | (simpleTriList->isVisible & 1); changedTriangleFlags = v; } } return; } int lookupHack[3] = {0,0,0}; for (; i < lim; ++i) { //we get a huge win from not calculating lightOfSight to unlit things if (simpleTriList->setVisiblity( simpleTriList->lit() && areaOfView->isInWithCheat(simpleTriList->center, lookupHack) )) { unsigned char v = 0x4 | (simpleTriList->wasVisible << 1) | (simpleTriList->isVisible & 1); changedTriangleFlags = v; } } } //End [aname=cite1][sup]1[/sup]To give a sense of the algorithm's performance, computing the currently visible area in figure 5, and combining it with the previous area, took 0.003 seconds on a dual core 2Ghz processor. However, keep mind that figure 5 represents very small and simple map (containing less than 100,000 triangles). [aname=cite2][sup]2[/sup]GPC, PolyBoolean and LEDA are among these packages. Some discussion of the problems of runtime, runspace, and accuracy can be found at http://www.complex-a5.ru/polyboolean/comp.html. Boost's GTL is promising, but it forces the user of integers for coordinates, and the implementation is still evolving.[aname=cite3][sup]3[/sup]Formally speaking, there isn't a cross product defined in 2D; they only work in 3 or 7 dimensions. What's referred to here is the z value computed as part of a 3D cross product, according to u.x * v.y - v.x * u.y.

