
[size="5"] Basic Alpha Blending
| equation 1 result = ALPHA * srcPixel + ( 1 - ALPHA ) * destPixel Where: ALPHA ranges from 0.0 to 1.0 |
Before we wrap this equation with some code we need to see if we can optimize it. The first thing that should stand out are the two multiplications in the equation. As costly as multiplication is let's see if we can do anything about it. Rearranging things a bit produces an equation with a single multiplication.
| equation 2 result = ALPHA* srcPixel + destPixel - ALPHA * destPixel result = ALPHA * ( srcPixel - destPixel ) + destPixel |
| equation 3 result = ( ALPHA * ( srcPixel - destPixel ) ) / 256 + destPixel Where: ALPHA ranges from 0 to 256 |
I will state millisecond and cycles per pixel timings through out this article, it is important to know the exact conditions under which these timings were taken. First, here are some specs for the PC that was used for all the timings:
[bquote]
[/bquote]
All of the functions I will be describing read from two buffers, manipulate the data, and then write the data out to a buffer. For these timings all of the buffers that were read from or written to resided in system memory, NOT video memory. Even though these routines will be able to handle transparency the timings were taken using a 320x240 pixel bitmap where none of the pixels in the bitmap were set to the transparent (or colorkey) value. Doing this levels the playing field. We want to take our timings on the worst case scenario which for us would be an image where we have to check all pixels for transparency but do not get to skip any of them because none of them match the colorkey value. There are many more factors that come into play when determining the "speed" of an algorithm. What is important is the difference in performance from one attempt to the next while holding these factors constant.| Processor | Intel Pentium II - 350 MHz |
| Ram | 128 MB |
| Video Card | Viper 550 16 MB |
| Video Mode | 640x480 16bpp (5-6-5) |
[size="5"] FIRST ATTEMPT: Just get it working
The basic idea for alpha blending a non-indexed color mode (16bpp, 24bpp, etc) pixel is to breakdown both the source and destination pixel into their red, green, and blue color components or channels. Perform the above alpha blending equation on each channel then recombine the channels to form the resulting alpha blended pixel. Listing 1 shows some sample code that puts all of this together.
i = height;
do
{
j = width;
do
{
sTemp = *((WORD*)lpSprite);
if ( sTemp != sColorKey )
{
dTemp = *((WORD*)lpDest);
sb = sTemp & 0x1f;
db = dTemp & 0x1f;
sg = (sTemp >> 5) & 0x3f;
dg = (dTemp >> 5) & 0x3f;
sr = (sTemp >> 11) & 0x1f;
dr = (dTemp >> 11) & 0x1f;
blue = (ALPHA * (sb - db) >> 8) + db;
green = (ALPHA * (sg - dg) >> 8) + dg;
red = (ALPHA * (sr - dr) >> 8) + dr;
*((WORD*)lpDest) = blue | (green << 5) | (red << 11);
}
lpDest += 2;
lpSprite += 2;
}while ( --j > 0 );
lpDest += dPadding;
lpSprite += sPadding;
}while (--i > 0);[size="3"] Performance of the First Attempt:
| Milliseconds / function call | 11.54 |
| Cycles per pixel | 53 |
[size="5"]SECOND ATTEMPT: Tried them all!
I coded many second attempts to improve upon the original. All of them improved the speed at which I processed the pixels but for a price! I tried using lookup tables with some good success I believe this resulted in a 40%-45% improvement in speed but you had the overhead and sloppiness of the lookup tables to contend with. Also the lookup tables for 16 bit color are huge and I have heard can cause cache-thrashing on higher end machines. If your goal is a fullscreen fade you can realize a two-fold increase in speed by only fading every other line per frame. This worked extremely well and produces an interesting effect. However, this does not look so hot if you are trying to alpha blend an explosion with your background tiles. If you can live with a single grade of alpha blending (50/50), then there is an extremely fast method to achieve this. For both the source and destination color values you mask off the low bit in each color channel then shift by one to the right, then add the two results together which gives you a 50% faded look. Listing 2 is the inner loop of a routine that show how to do to this for 16bpp 5-6-5 buffers.
j = width;
do
{
sTemp = *((WORD*)lpSprite);
if ( sTemp != sColorKey )
{
dTemp = *((WORD*)lpDest);
Result = ( (sTemp & 0xF7DE) >> 1) + ( (dTemp & 0xF7DE) >> 1);
}
*((DWORD*)lpDest) = Result;
lpDest += 2;
lpSprite += 2;
}while ( --j > 0 );[size="3"] Performance of the 50/50 single shade alpha blending function:
| Milliseconds / function call | 5.84 |
| Cycles per pixel | 27 |
| Improvement over baseline | 98% |
[size="5"]THIRD ATTEMPT: Who Needs MMX?
Well, we all need MMX and the other SIMD instruction sets, but who says we can't mimic them in "C. The advantage of MMX is that you can perform the same operation on multiple data elements all in the same cycle. If we pack two 16 bit pixels into a single 32 bit value and operate on them as a unit we could eliminate at least 3 multiplication per every 2 pixels!
In order to pull this off we will need to modify our alpha blending equation. We cannot afford to have any negative values at any time during the calculation. Our 2 packed pixels are defined as an unsigned 32bit value and if our destination color channel is greater then our source we will get a negative value, which will cause strange things to happen. Negative values are acceptable if you are blending one pixel at a time because the result of equations 1, 2, and 3 will always be a positive value. We need to add the maximum value of a color channel to the source color channel so when we subtract the destination we are assured to have a positive value. For 16 bit color this maximum value is 64 (the green channel can have 6 bits, 111111 binary or 64 in decimal). Of course we need to subtract it back out later to maintain the integrity of the equation. Note that this trick only works for the 16 bit color modes because we are stuffing two 16 bit pixels into one 32 bit value. We will start with equation 3.
result = ( ALPHA * ( s - d ) ) / 256 + dresult = ( ALPHA * ( ( s + 64 ) - d ) ) / 256 + dresult = ( ALPHA * s) / 256 + (ALPHA * 64) / 256 - ( ALPHA * d ) / 256 + dresult = ( ALPHA * s) / 256 + (ALPHA * 64) / 256 - ( ALPHA * d ) / 256 + d - (ALPHA * 64) / 256| equation 4 result = ( ALPHA * ( ( s + 64 ) - d ) ) / 256 + d - (ALPHA / 4) |
DWORD PLUS64 = 64 | (64 << 16);
DWORD ALPHABY4 = (ALPHA / 4) | ((ALPHA / 4) << 16);
DWORD doubleColorKey = sColorKey | (sColorKey << 16);
...
// Is the Sprite width odd or even?
If ( width % 2 == 1 )
{
oddWidth = TRUE;
width = (width - 1) / 2; //div by 2, processing 2 pixels at a time.
}
else
{
width = width / 2; //div by 2, processing 2 pixels at a time.
}
i = height;
do
{
if ( oddWidth )
{
sTemp = *((WORD*)lpSprite);
if ( sTemp != sColorKey )
{
dTemp = *((WORD*)lpDest);
sb = sTemp & 0x1f;
db = dTemp & 0x1f;
sg = (sTemp >> 5) & 0x3f;
dg = (dTemp >> 5) & 0x3f;
sr = (sTemp >> 11) & 0x1f;
dr = (dTemp >> 11) & 0x1f;
*((WORD*)lpDest) = (DWORD)((ALPHA * (sb - db) >> 8) + db |
((ALPHA * (sg - dg) >> 8) + dg) << 5 |
((ALPHA * (sr - dr) >> 8) + dr) << 11);
}
lpDest += 2;
lpSprite += 2;
}
j = width;
do
{
sTemp = *((DWORD*)lpSprite);
if ( sTemp != doubleColorKey )
{
dTemp = *((DWORD*)lpDest);
sb = sTemp & 0x001F001F;
db = dTemp & 0x001F001F;
sg = (sTemp >> 5) & 0x003F003F;
dg = (dTemp >> 5) & 0x003F003F;
sr = (sTemp >> 11) & 0x001F001F;
dr = (dTemp >> 11) & 0x001F001F;
BLUEC = ((((ALPHA * ((sb + PLUS64) - db)) >> 8) + db) - ALPHABY4) & 0x001F001F;
GREENC = (((((ALPHA * ((sg + PLUS64) - dg)) >> 8) + dg) - ALPHABY4) & 0x003F003F) << 5;
REDC = (((((ALPHA * ((sr + PLUS64) - dr)) >> 8) + dr) - ALPHABY4) & 0x001F001F) << 1;
Result = BLUEC | GREENC | REDC;
if ( (sTemp >> 16) == sColorKey )
Result = (Result & 0xFFFF) | (dTemp & 0xFFFF0000);
else if ( (sTemp & 0xFFFF) == sColorKey )
Result = (Result & 0xFFFF0000) | (dTemp & 0xFFFF);
*((DWORD*)lpDest) = Result;
}
lpDest += 4;
lpSprite += 4;
}while ( --j > 0 );
lpDest += dbuf;
lpSprite += sbuf;
}while ( --i > 0 );[size="5"]THIRD ATTEMPT: Who Needs MMX? (continued)
We are using packed data just like the MMX instructions do. We have two 16 bit values packed into a single 32 bit value. If you want to add or subtract a value from packed data you must shift into place multiple copies of the value you wish to add/subtract. Here are some examples:
DWORD PLUS256 = 256 | (256 << 16);
DWORD ALPHAPLUS = ALPHA | (ALPHA << 16);
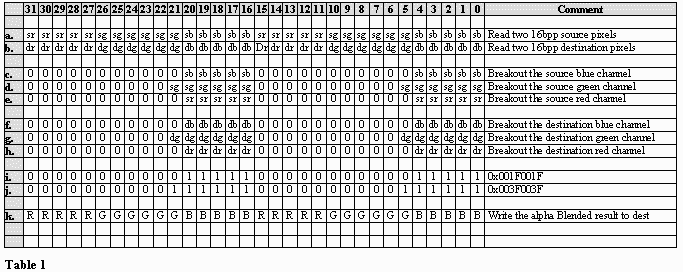
DWORD doubleColorKey = sColorKey | (sColorKey << 16);BLUEC = ((((ALPHA * ((sb + PLUS256) - db)) >> 8) + db) - ALPHAPLUS) & 0x001F001F;Inside the inner loop we read in two pixels from our source buffer and I check to see if this value is equal to doubleColorKey. If it is we can skip the majority of the processing. If the two values are not equal we read in two pixels from the destination buffer. Seeing the individual bits of each data element might be helpful so I will refer to Table 1 as we go along. Table 1a and b show the pixels in their 32 bit packed state.
Now we need to separate out the red, green, and blue color components. This is easy enough to do if you know the color format of your buffer. We have 16 bits in which to describe the 3 color channels. Unfortunately, 3 does not divide evenly into 16 so the video chip manufacturers must make a choice. Either they only use 15 bits, giving each color channel 5 bits or they use all 16 bits but give one of the color channels 6 bits and the other two 5 bits. These two formats are referred to as 16bpp 5-5-5 or 16bpp 5-6-5. The numbers map respectively to the red, green and blue color channels. It is possible that other combinations could exist but it is very rare. Listing 3 is tailored for the 5-6-5 format. Below is the code that does this for us (See table 1c-h).
sb = sTemp & 0x001F001F;
db = dTemp & 0x001F001F;
sg = (sTemp >> 5) & 0x003F003F;
dg = (dTemp >> 5) & 0x003F003F;
sr = (sTemp >> 11) & 0x001F001F;
dr = (dTemp >> 11) & 0x001F001F;Result = BLUEC | GREENC | REDC;if ((sTemp >> 16) == sColorKey)
Result = (Result & 0xFFFF) | (dTemp & 0xFFFF0000);
else if ((sTemp & 0xFFFF) == sColorKey)
Result = (Result & 0xFFFF0000) | (dTemp & 0xFFFF);[size="3"] Performance of the Third Attempt:
| Milliseconds / function call | 8.52 |
| Cycles per pixel | 39 |
| Improvement over baseline | 35% |
[size="5"]FOURTH ATTEMPT: The MMX version
There are two alpha blending examples using MMX on Intel's website. This is what I used to learn the MMX instruction set. Once I was comfortable with the ins and outs of the packed data instructions I put together my own MMX version of alpha blending. You can find the code in the zip file. It is well commented but the interlacing of the instructions makes it difficult to follow. The logic is the same as Listing 3 but instead of working on 2 pixels at a time it operates on 4 at a time! The code is very fast, here are the comparisons.
[size="3"] Performance of the Fourth Attempt:
| Milliseconds / function call | 3.73 |
| Cycles per pixel | 17 |
| Improvement over baseline | 309% |
[size="5"]Optimizations
None of the functions I have designed take into consideration that we may be reading or writing to non-aligned addresses. I believe you pay a 3-cycle penalty for this. We need to minimize the number of non-aligned reads and writes. Another optimization that applies only to the MMX function is to test if your four source pixels are all equal to the colorkey value before running through all the calculations. For bitmaps with 50% or more set to the colorkey value this would significantly increase the drawing speed. I'm sure there are countless other optimizations as well.
[size="5"]Conclusion
The MMX version is more than 3 times as fast as the basic alpha blending routine and can alpha blend a 640x480 16bpp screen in about 16 milliseconds. I hope I was clear enough for you to be able to follow my theories. If you have questions about anything e-mail me and I will do my best to answer them. Also, if you see additional improvement please drop me a line, I am always interested in improving this code. Although I feel some of the ideas I have outlined here are original they would not have been possible without all the excellent information I mined from the web. Therefore, thy taketh from the web thy shall giveth back to the web. All that is contained in this document is public domain. All I ask is that the document be maintained as a whole.
[size="5"] Source Code
A zip file named "ht_alpha.zip" contains all the source code and a sample application to demonstrate what I have talked about in this article. The zip file should contain a VC++ project and these main files:
[bquote]
[/bquote]
There are also debug and release versions of the executable. To run the app you need to move one of these exe's into the directory where the bmp files are located (or visa versa). The sample application uses the function keys 1-7 and the ESC key.| Ht_alpha.doc | This article in Word '97 format. |
| Ht_ddutil.cpp | Modified ddutil.cpp from the DX SDK |
| Ht_Ddutil.h | Modified ddutil.h from the DX SDK |
| Ht_logo.bmp | HoundstootH logo bitmap |
| Ht_bkgrnd.bmp | Background bitmap |
| Ht_alpha.cpp | Contains all the alpha blending code |
[bquote]F1 - Use DX BltFast to render image (no alpha blending)
F2 - Use the 50/50 function to alpha blend the image
F3 - Use the basic alpha blending function to render image
F4 - Use the improved alpha blending function to render the image
F5 - Use the MMX alpha blending function to render the image
F6 - Render in transparent mode
F7 - Render in block mode (no transparency)
ESC - Exit the application[/bquote]
By: John HebertF2 - Use the 50/50 function to alpha blend the image
F3 - Use the basic alpha blending function to render image
F4 - Use the improved alpha blending function to render the image
F5 - Use the MMX alpha blending function to render the image
F6 - Render in transparent mode
F7 - Render in block mode (no transparency)
ESC - Exit the application[/bquote]
Email: [email="hebertjo@w-link.net"]hebertjo@w-link.net[/email]
You can also contact me through the CDX mailing list. CDX is an open source DirectX wrapper that has many great features, one of which is alpha blending contributed by myself. CDX can be found at: http://www.cdx.sk/


