One of the most crucial part of a particle system is the container for all the particles. It has to hold all the data that describe particles, it should be easy to extend and fast enough. In this post I will write about choices, problems and possible solutions for such a container.
The Series
Introduction
What is wrong with this code?
class Particle { public: bool m_alive; Vec4d m_pos; Vec4d m_col; float time; // ... other fields public: // ctors... void update(float deltaTime); void render(); }; and then usage of this class:
std::vector particles; // update function: for (auto &p : particles) p.update(dt); // rendering code: for (auto &p : particles) p.render(); Actually one could say that it is OK. And for some simple cases indeed it is. But let us ask several questions:
- Are we OK with SRP principle here?
- What if we would like to add one field to the particle? Or have one particle system with pos/col and other with pos/col/rotations/size? Is our structure capable of such configuration?
- What if we would like to implement a new update method? Should we implement it in some derived class?
- Is the code efficient?
My answers:
- It looks like SRP is violated here. The Particle class is responsible not only for holding the data but also performs updates, generations and rendering. Maybe it would be better to have one configurable class for storing the data, some other systems/modules for its update and another for rendering? I think that this option is much better designed.
- Having the Particle class built that way we are blocked from the possibility to add new properties dynamically. The problem is that we use here an AoS (Array of Structs) pattern rather than SoA (Structure of Arrays). In SoA when you want to have one more particle property you simply create/add a new array.
- As I mentioned in the first point: we are violating SRP so it is better to have a separate system for updates and rendering. For simple particle systems our original solution will work, but when you want some modularity/flexibility/usability then it will not be good.
- There are at least three performance issues with the design:
- AoS pattern might hurt performance.
- In the update code for each particle we have not only the computation code, but also a (virtual) function call. We will not see almost any difference for 100 particles, but when we aim for 100k or more it will be visible for sure.
- The same problem goes for rendering. We cannot render each particle on its own, we need to batch them in a vertex buffer and make as few draw calls as possible.
All of above problems must be addressed in the design phase.
Add/Remove Particles
It was not visible in the above code, but another important topic for a particle system is an algorithm for adding and killing particles:
void kill(particleID) { ?? } void wake(particleID) { ?? } How to do it efficiently?
First thing: Particle Pool
It looks like particles need a dynamic data structure - we would like to dynamically add and delete particles. Of course we could use
list or
std::vector and change it every time, but would that be efficient? Is it good to reallocate memory often (each time we create a particle)? One thing that we can initially assume is that we can allocate one huge buffer that will contain the maximum number of particles. That way we do not need to have memory reallocations all the time.
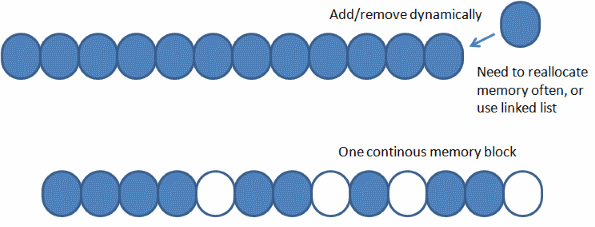
We solved one problem: numerous buffer reallocations, but on the other hand we now face a problem with fragmentation. Some particles are alive and some of them are not. So how to manage them in one single buffer?
Second thing: Management
We can manage the buffer it at least two ways:
- Use an alive flag and in the for loop update/render only active particles.
- this unfortunately causes another problem with rendering because there we need to have a continuous buffer of things to render. We cannot easily check if a particle is alive or not. To solve this we could, for instance, create another buffer and copy alive particles to it every time before rendering.
- Dynamically move killed particles to the end so that the front of the buffer contains only alive particles.
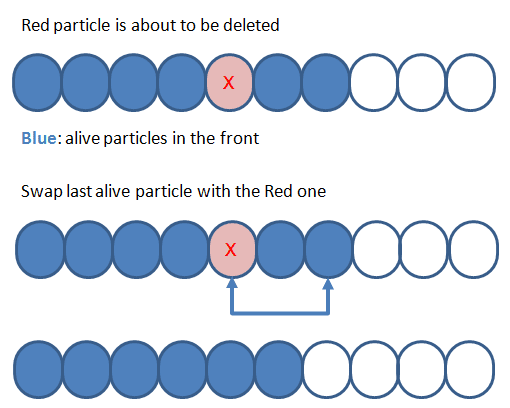
As you can see in the above picture when we decide that a particle needs to be killed we swap it with the last active one. This method is faster than the first idea:
- When we update particles there is no need to check if it is alive. We update only the front of the buffer.
- No need to copy only alive particles to some other buffer
What's Next
In the article I've introduced several problems we can face when designing a particle container.
Next time I will show my implementation of the system and how I solved described problems. BTW: do you see any more problems with the design? Please share your opinions in the comments.
Links
14 Jun 2014: Initial version, reposted from
Code and Graphics blog







")








I went to your site and it is a real interesting series so far, but wouldn't it have made more sense to upload the start of the article series and link to the rest rather than put the second part here and link to the previous and later series articles? I know it is part one of the in-depth part of the series, but it skips the introduction. Just my two cents on it.