Motivation
The motivation is very simple: regular hardware instancing is suddenly not enough for the current project. The reason for this is the amount of different trees, for which the simple arithmetic works:
- 9 base types of trees
- 3 growth stages for each tree (a branch, a small tree and a big tree)
- 3 health stages for each growth stage for each tree (healthy, sick and dying)
- 5 LODs for each health stage for each growth stage for each tree (including impostors)
- This creates a serious combinatorial explosion, which makes regular instancing a lot less effective.
Below I suggest a solution that allows one to bypass this problem and to render all these different trees with a single draw call, while having a unique mesh and unique constants per each object.
Main idea
D3D11 and GL4 support
[RW]StructuredBuffer (D3D) and
ARB_shader_storage_buffer_object (GL), which represent some GPU memory buffer with structured data. A shader can fetch the data from this buffer by an arbitrary index. I suggest to use 2 global buffers to store vertices and indices and to fetch the data from there in a vertex shader using a vertex ID. This way we can supply an offset to this buffer as a regular constant and start fetching vertices starting from this offset. How do we implement this?
Logical and physical buffers
Let us introduce two terms: a physical buffer and a logical buffer. A physical buffer is a GPU memory buffer which stores all indices and vertices of our geometry. Essentialy it is a sort of a "geometry atlas" - we pack all our mesh data there. A logical buffer is a data structure that contains physical buffer offset and a data block size. These two terms are easily illustrated with the following picture:
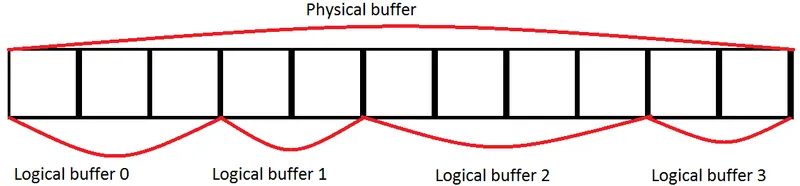
In C++ this will look like this:
struct DXLogicalMeshBuffer final { uint8_t* data = nullptr; size_t dataSize = 0; size_t dataFormatStride = 0; size_t physicalAddress = 0; }; The struct fields are used for:
- data : a pointer to the buffer data
- dataSize : Buffer data size in bytes
- dataFormatStride : One buffer element size
- physicalAddress : Physical buffer offset, by which this buffer data is located. This field is set when physical buffer is updated (see below)
Upon logical buffer creation a physical buffer must know about the logical buffer to create a storage space for it. Physical buffer class looks like this:
struct DXPhysicalMeshBuffer final { ID3D11Buffer* physicalBuffer = nullptr; ID3D11ShaderResourceView* physicalBufferView = nullptr; size_t physicalDataSize = 0; bool isDirty = false; typedef DynamicArray PageArray; PageArray allPages; DXPhysicalMeshBuffer() = default; inline ~DXPhysicalMeshBuffer() { if (physicalBuffer != nullptr) physicalBuffer->Release(); if (physicalBufferView != nullptr) physicalBufferView->Release(); } void allocate(DXLogicalMeshBuffer* logicalBuffer); void release(DXLogicalMeshBuffer* logicalBuffer); void rebuildPages(); // very expensive operation } The class fields are used for:
- physicalBuffer : An actual buffer with the data
- physicalBufferView : A shader resource view for shader data access
- physicalDataSize : Buffer data size in bytes
- isDirty : A flag that indicates the need for buffer update (it is needed after each logical buffer allocation/deallocation).
- allPages : All logical buffers allocated inside this physical buffer.
Each time a logical buffer is allocated/deallocated a physical buffer needs to be informed about this. Allocate/release operations are quite trivial:
void DXPhysicalBuffer::allocate(DXLogicalMeshBuffer* logicalBuffer) { allPages.Add(logicalBuffer); isDirty = true; } void DXPhysicalBuffer::release(DXLogicalMeshBuffer* logicalBuffer) { allPages.Remove(logicalBuffer); isDirty = true; } rebuildPages() method is much more interesting. This method must create a physical buffer and fill it with the data from all used logical buffers. A physical buffer must be mappable to RAM and bindable as a structured shader resource.
size_t vfStride = allPages[0]->dataFormatStride; // TODO: right now will not work with different strides size_t numElements = physicalDataSize / vfStride; if (physicalBuffer != nullptr) physicalBuffer->Release(); if (physicalBufferView != nullptr) physicalBufferView->Release(); D3D11_BUFFER_DESC bufferDesc; bufferDesc.BindFlags = D3D11_BIND_SHADER_RESOURCE; bufferDesc.ByteWidth = physicalDataSize; bufferDesc.Usage = D3D11_USAGE_DYNAMIC; bufferDesc.MiscFlags = D3D11_RESOURCE_MISC_BUFFER_STRUCTURED; bufferDesc.StructureByteStride = vfStride; bufferDesc.CPUAccessFlags = D3D11_CPU_ACCESS_WRITE; if (FAILED(g_pd3dDevice->CreateBuffer(&bufferDesc, nullptr, &physicalBuffer))) { handleError(...); // handle your error here return; } Make sure that
StructureByteStride is equal to the size of a structure read by the vertex shader. Also, CPU write access is required. After that we need to create a shader resource view:
D3D11_SHADER_RESOURCE_VIEW_DESC viewDesc; std::memset(&viewDesc, 0, sizeof(viewDesc)); viewDesc.Format = DXGI_FORMAT_UNKNOWN; viewDesc.ViewDimension = D3D11_SRV_DIMENSION_BUFFER; viewDesc.Buffer.ElementWidth = numElements; if (FAILED(g_pd3dDevice->CreateShaderResourceView(physicalBuffer, &viewDesc, &physicalBufferView))) { // TODO: error handling return; } Whew. Now let us get straight to the physical buffer filling! The algorithm is:
- Map the physical buffer to RAM.
- for each logical buffer:
- Calculate logical buffer offset into the physical buffer (physicalAddress field).
- Copy the data from the logical buffer to the mapped memory with the needed offset.
- Go to the next logical buffer.
- Unmap the physical buffer.
The code is quite simple:
// fill the physical buffer D3D11_MAPPED_SUBRESOURCE mappedData; std::memset(&mappedData, 0, sizeof(mappedData)); if (FAILED(g_pImmediateContext->Map(physicalBuffer, 0, D3D11_MAP_WRITE_DISCARD, 0, &mappedData))) { handleError(...); // insert error handling here return; } uint8_t* dataPtr = reinterpret_cast(mappedData.pData); size_t pageOffset = 0; for (size_t i = 0; i < allPages.GetSize(); ++i) { DXLogicalMeshBuffer* logicalBuffer = allPages; // copy logical data to the mapped physical data std::memcpy(dataPtr + pageOffset, logicalBuffer->data, logicalBuffer->dataSize); // calculate physical address logicalBuffer->physicalAddress = pageOffset / logicalBuffer->dataFormatStride; // calculate offset pageOffset += logicalBuffer->dataSize; } g_pImmediateContext->Unmap(physicalBuffer, 0); Note that rebuilding a physical buffer is a very expensive operation, in our case it is around 500ms. This slowness is caused by the high amount of data that is being sent to the GPU (tens of megabytes!). This why it is not recommended to rebuild the physical buffer often.
Full code for rebuildPages() method for reference. Storing and rendering stuff like that requires a custom constant managing as well.
Managing per-object constants
Traditional constant buffers does not fit here for obvious reasons. That's why there is no other choice then to use one more global buffer, similar to the physical buffer described above. Apart from usual shader constants this buffer must contain logical buffer information, geometry type (indexed and non-indexed) and vertex count. Creating this buffer is trivial:
std::memset(&bufferDesc, 0, sizeof(bufferDesc)); bufferDesc.BindFlags = D3D11_BIND_SHADER_RESOURCE; bufferDesc.ByteWidth = dataBufferSize; bufferDesc.Usage = D3D11_USAGE_DYNAMIC; bufferDesc.MiscFlags = D3D11_RESOURCE_MISC_BUFFER_STRUCTURED; bufferDesc.StructureByteStride = stride; bufferDesc.CPUAccessFlags = D3D11_CPU_ACCESS_WRITE; if (FAILED(g_pd3dDevice->CreateBuffer(&bufferDesc, nullptr, &dataBuffer))) { handleError(...); // handle your error here return; } D3D11_SHADER_RESOURCE_VIEW_DESC viewDesc; std::memset(&viewDesc, 0, sizeof(viewDesc)); viewDesc.Format = DXGI_FORMAT_UNKNOWN; viewDesc.ViewDimension = D3D11_SRV_DIMENSION_BUFFER; viewDesc.Buffer.ElementWidth = numInstances; if (FAILED(g_pd3dDevice->CreateShaderResourceView(dataBuffer, &viewDesc, &dataView))) { handleError(...); // handle your error here return; } First, four 32-bit registers of this buffer are filled with a shader internal data used for rendering. This data looks like this:
struct InternalData { uint32_t vb; uint32_t ib; uint32_t drawCallType; uint32_t count; }; After this structure goes the usual constant data used for generic mesh rendering (such as projection matrix). Now a small digression. I usually don't render anything directly, instead I use an array of
DrawCall structures, which also contain constants and all other data needed for a single DIP:
struct DrawCall final { enum Type : uint32_t { Draw = 0, DrawIndexed = 1 }; enum { ConstantBufferSize = 2048 // TODO: remove hardcode }; enum { MaxTextures = 8 }; uint8_t constantBufferData[ConstantBufferSize]; DXLogicalMeshBuffer* vertexBuffer; DXLogicalMeshBuffer* indexBuffer; uint32_t count; uint32_t startVertex; uint32_t startIndex; Type type; }; This is simplified to make reading easier. The application fills an array of these structures and submits them for rendering. After filling this draw call buffer we need to update the constant buffer, update
InternalData and, finally, issue a real DIP to render stuff. Updating constants is trivial, just loop through the command buffer and copy needed data to the right place:
// update constants { D3D11_MAPPED_SUBRESOURCE mappedData; if (FAILED(g_pImmediateContext->Map(psimpl->constantBuffer.dataBuffer, 0, D3D11_MAP_WRITE_DISCARD, 0, &mappedData))) { // TODO: error handling return; } uint8_t* dataPtr = reinterpret_cast(mappedData.pData); for (size_t i = 0; i < numInstances; ++i) { size_t offset = i * internal::DrawCall::ConstantBufferSize; const internal::DrawCall& call = queue->getDrawCalls(); std::memcpy(dataPtr + offset, call.constantBufferData, internal::DrawCall::ConstantBufferSize); // fill internal data structure InternalData* idata = reinterpret_cast(dataPtr + offset); DXLogicalMeshBuffer* vertexBuffer = static_cast(call.vertexBuffer.value); if (vertexBuffer != nullptr) idata->vb = vertexBuffer->physicalAddress; DXLogicalMeshBuffer* indexBuffer = static_cast(call.indexBuffer.value); if (indexBuffer != nullptr) idata->ib = indexBuffer->physicalAddress; idata->drawCallType = call.type; idata->count = call.count; } g_pImmediateContext->Unmap(psimpl->constantBuffer.dataBuffer, 0); } The data is now ready for actual rendering.
Shader and drawing
Time for drawing! To render everything we need to set the buffers and issue
DrawInstanced:
ID3D11ShaderResourceView* vbibViews[2] = { g_physicalVertexBuffer->physicalBufferView, g_physicalIndexBuffer->physicalBufferView }; g_pImmediateContext->VSSetShaderResources(0, 2, vbibViews); g_pImmediateContext->VSSetShaderResources(0 + 2, 1, &psimpl->constantBuffer.dataView); g_pImmediateContext->HSSetShaderResources(0 + 2, 1, &psimpl->constantBuffer.dataView); g_pImmediateContext->DSSetShaderResources(0 + 2, 1, &psimpl->constantBuffer.dataView); g_pImmediateContext->GSSetShaderResources(0 + 2, 1, &psimpl->constantBuffer.dataView); g_pImmediateContext->PSSetShaderResources(0 + 2, 1, &psimpl->constantBuffer.dataView); g_pImmediateContext->DrawInstanced(maxDrawCallVertexCount, numInstances, 0, 0); Almost done. A few notes:
- DrawInstanced needs to be called with a maximum amount of vertices the command buffer has. This is required because we have a single draw call and several meshes. Meshes can have different amount of vertices/indices and this needs to be taken into account. I suggest to render the maximum amount of vertices and dicard redunand vertices by sending them outside the clip plane.
- This introduces some additional vertex shader overhead, thus you need to carefully watch for the difference between maximum and minimun vertices being within a reasonable range (typically 10% difference is OK). Remember that these wasted vertices add overhead to each rendered instance and it grows insanely fast. Watch for the artists!
- One DrawInstanced call can handle both indexed and non-indexed geometry, because this is handled in the vertex shader. TriangleStrip, TriangleFan and similar topologies are not supported for obvious reasons. This method supports only *List topologies (TriangleList, PointList, etc.)
The vertex shader is also very simple. First we need to define all the CPU-side structured (vertex format, constant format, etc.):
// vertex struct VertexData { float3 position; float2 texcoord0; float2 texcoord1; float3 normal; }; StructuredBuffer g_VertexBuffer; StructuredBuffer g_IndexBuffer; // pipeline state #define DRAW 0 #define DRAW_INDEXED 1 struct ConstantData { uint4 internalData; float4x4 World; float4x4 View; float4x4 Projection; }; StructuredBuffer g_ConstantBuffer; After that goes the code that fetches constant data and processes vertices (pay attention to indexed/non-indexed geometry handling):
uint instanceID = input.instanceID; uint vertexID = input.vertexID; uint vbID = g_ConstantBuffer[instanceID].internalData[0]; uint ibID = g_ConstantBuffer[instanceID].internalData[1]; uint drawType = g_ConstantBuffer[instanceID].internalData[2]; uint drawCount = g_ConstantBuffer[instanceID].internalData[3]; VertexData vdata; [branch] if (drawType == DRAW_INDEXED) vdata = g_VertexBuffer[vbID + g_IndexBuffer[ibID + vertexID]]; else if (drawType == DRAW) vdata = g_VertexBuffer[vbID + vertexID]; [flatten] if (vertexID > drawCount) vdata = g_VertexOutsideClipPlane; // discard vertex by moving it outside of the clip plane As you can see - there is no rocket science.
Full shader code for reference. An attentive reader will notice that I did not cover texturing. The next part is about it.
What shall we do with textures?
This is the biggest con of this method. With this approach it is highly desired to have unique textures per instance, but implementing this with D3D11 is problematic. Possible solutions:
- Use one texture atlas. Cons: One atlas cannot hold many textures, so you will need to batch instances by 3 or 4 and render them separately. This negates all the pros of this method.
- Use texture arrays (Texture2DArray, Sampler2DArray). Cons: better then texture atlas, but still limited to 2048 textures per array.
- Switch to OpenGL 4.3 with bindless textures. Cons: everything will fit, but there is one serious problem called OpenGL.
- Switch to D3D12/Mantle/Vulkan/etc. Cons: everything will fit, but with limited hardware/OS support.
- Virtual textures. Cons: virtual textures, anyone?:)
Detailed overview of all these methods goes beyond this article. I will only say that I use texture arrays for D3D11 and native features of D3D12.
Caveats and limitations
All major cons are described above, thus here is a little summary:
- Wasted vertices overhead.
- Indirection overhead: vertex and constant access is badly predicted, because it is a random access, thus they are not cached and always calculated dynamically. Indexed rendering is the slowest one because of double indirection.
- Not all primitive topologies supported.
- Unique textures per instance are not possible in the general case.
- Reallocating buffers is expensive and adds video memory fragmentation.
- Unusual vertex buffers require unusual algorithms for unusual cases, like dynamically generating vertices with compute shader (e.g. water simulation, cloth, etc.).
- It is required to hold all the logical buffer data in memory, this slightly increasing application memory consumption.
Demo and sources
The main source code for this method is
here. There is no binary version at the moment. Here are some screenshots:
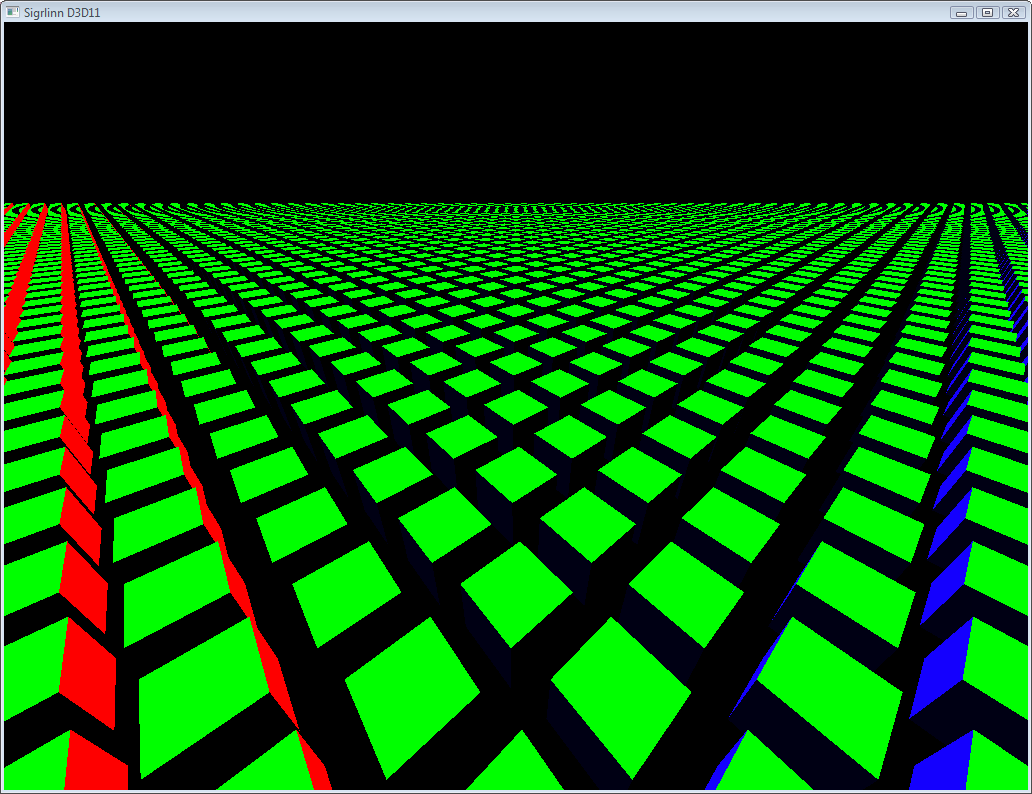
16384 unique cubes, 1.2ms per frame on Intel HD 4400: 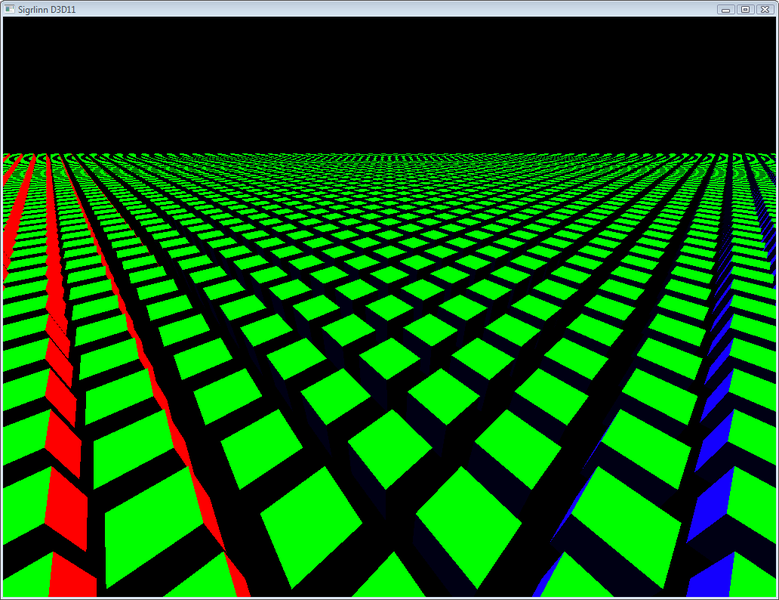 4096 unique instances of grass, 200k triangles:
4096 unique instances of grass, 200k triangles: 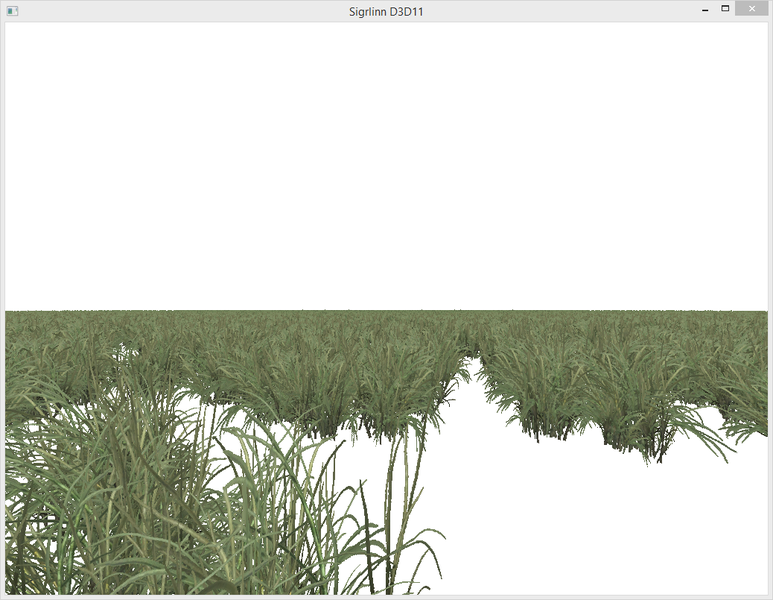
Further reading
OpenGL Insights, III Bending the Pipeline, Programmable vertex pulling by Daniel Rakos - almost the same method for OpenGL. Thanks for your attention!
27 April 2015: Initial release

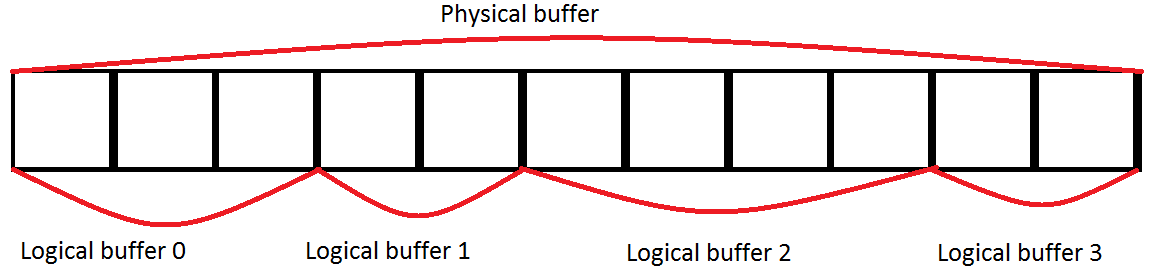
 4096 unique instances of grass, 200k triangles:
4096 unique instances of grass, 200k triangles: 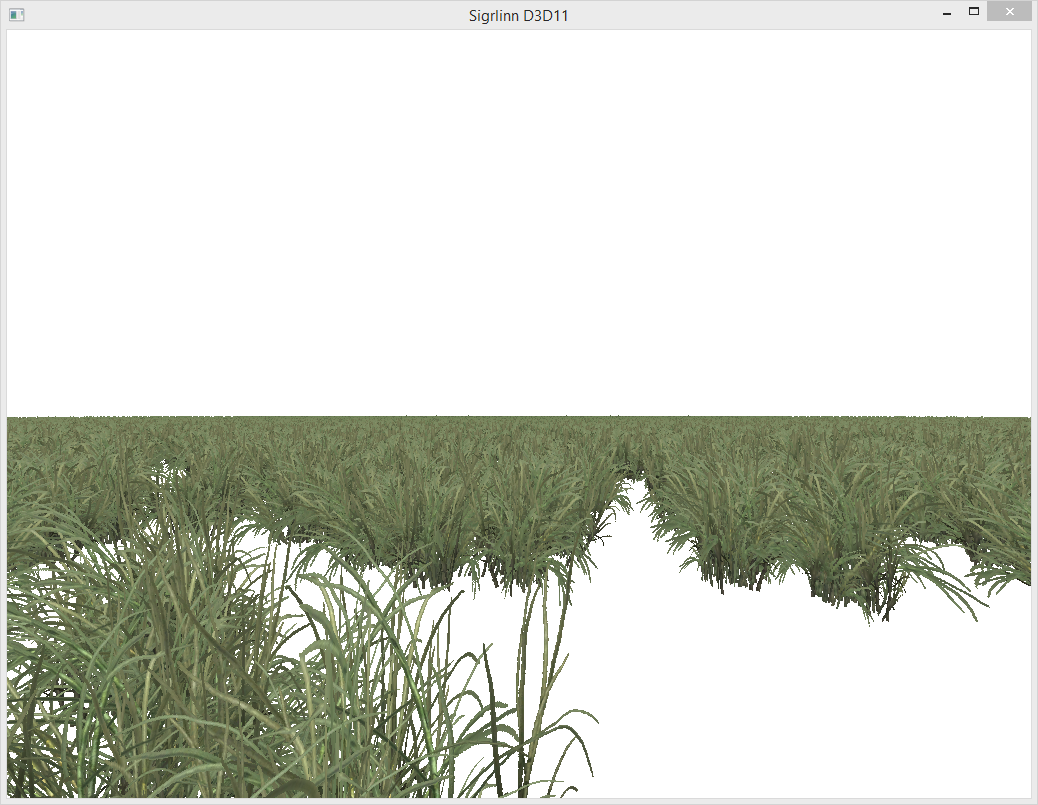


Nice. I'm curious: The vertex shader displayed here "discards" vertices above the count, the linked shader ignores the count value. Was there actually a performance difference ?