
In a basic implementation, simple data structures such as Health, Speed, Object Placement and other game values are read from data files. We often need to do more than just specify the different colors of the enemies in a game, so this only meets half of our requirements. The fixed data format constrains what options are ultimately possible and it simply does not provided enough flexibility. We must also drive the game's logic and rules.
This is accomplished using some form of scripting language. This article explains how you can easily create a simple scripting language for your game and provides some sample code that you can quickly integrate in to your own game engine.
Traditionally games developed in-house scripting languages such as QuakeC, UnrealScript or similar resulting in a plethora of obscure game specific languages. Most people do not want to spend the resources to develop their own robust scripting language. A common option is to leverage existing languages like LUA, Python, Ruby or Java. Even when not, we are re-creating the wheel, using another embedded language isn't a perfect solution. It's still a hell of a lot of work to get them functioning and at the end of the day, there's a huge time investment to properly embed another language in to your game engine. And we all want to avoid as much of this work stuff as we can.
3[sup]rd[/sup] party languages generally work great, especially some of the better supported ones but they do have their drawbacks.
[nbsp]
- Performance (Unless compiled to native code, but usually has limitations)
- Interface between C/C++ and script can be constraining
- Interface can be high overhead and maintenance even with automated tools
- Usually lacks of good debugging and development tools
- If interpreted there is no error checking until script is actually run
- Learning and supporting an entirely new language requires a lot of extra effort
- Lack of easily available libraries, extensions and documentation
[nbsp]
Instead of embedding in other external scripting languages, it would be useful if we could use one we are already familiar with. C makes a wonderful base for representing a custom scripting language for your game. C will probably do every thing needed and you will be leveraging the power of a language with which you are already comfortable. It is much easier to distill down to elements that you need than to add a lot of additional functionality to something that does not do what you require.
There are some obvious benefits
[nbsp]- A rich feature set with plenty of documentation
- A wealth of existing tools to leverage
- Fast, efficient, compiled, code
- Extremely easy to interface with engine code
[nbsp]
One of the biggest advantages is time and performance. It takes very little effort and time to learn and use. Chances are you are already coding in C/C++ and because it is all compiled code; the performance will be on par with whatever else you have written for your core engine. Using C is not without pitfalls either, the scripts can be very dangerous, and it would be difficult to create safe scripts that run in a sandbox. All this wonderful power means we could really hurt ourselves with a few bad scripts.
We cannot just use C as a script language without first jumping through a few hoops. It does have a serious limitation that we will illustrate with the following scenario. Let us say that a C function represents each script. The pseudo-code to call our C functions looks like the following.
main()
{
script1(); // Call Script 1
script2(); // Call Script 2
script3(); // Call Script 3
}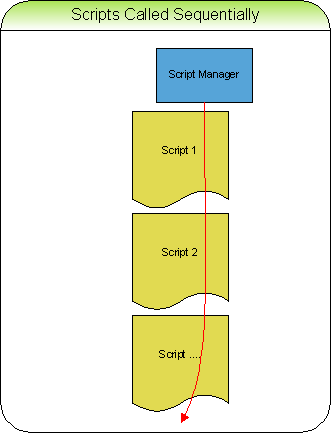
In C we are only able to run these scripts sequentially from start to finish. This does not do us any good. Since almost all of our scripts need to run over time during the course of the game. The following is a pseudo-code example of a script that describes an explosion effect.
Script_Explosion()
{
Create A Smoke Particle System
Create Explosion Sprite
Wait 1 Second
Create 2nd Explosion Sprite
Move 2nd Explosion Sprite Up 100 Units Over 3 Seconds
Wait 3 Seconds
Destroy Explosion Sprites
Destroy Smoke Particles
}
In order to run this script, we will need to run the script for a fixed time, draw a frame, run the script some more, and draw another frame etc. until our script terminates.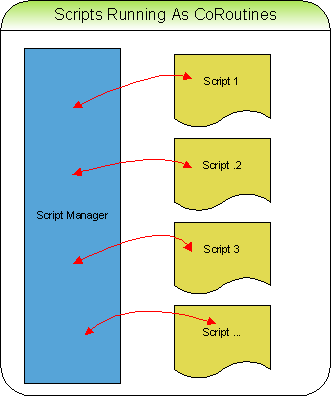
The simple solution would to create a separate thread for each script. However, threads are not practical due to their operational overhead and performance constraints. What we want is something that behaves like a thread but is more lightweight so it can support a large number of scripts.
This brings us right back to the original topic of co-routines. Think of them it as a simple co-operative multi-tasking mechanism. They are very much like a thread except they run in a pseudo-parallel manner. Each co-routine represents a path of execution: they are able to stop after a certain time, and later continue where they left off. Unlike threads each script only runs by manually receiving control of the CPU, they must then manually give up control of the CPU at specific points.
This suits us just fine, since we do not want them to run all the time and interfere with the rest of the finely tuned code in our game. Just as long as each co-routine gets their CPU time between a render-frame, we are good. Each C script represents a function and runs as a separate co-routine.
To jump back and forth between our management code and the script itself, we take advantage of the standard C library setjmp. We can use this library to do the dirty work of saving and restoring the current CPU state. There are only two functions in the library that we need to be concerned with:
setjmp - Saves the current state of the program and the stack environment
longjmp - Restores the saved state of the program and the stack environment
With these two functions we can safely pause and continue each script. While setjmp and longjmp does the nasty work of saving our CPU states, it only works for jumping to a previous point in our call stack. If we thought of it as a time machine you would only be able to travel to the past with it, never the future. In order for us to a longjmp in to function that was previously running, we have some further work to do.
To continue a script just before we do a longjmp back we need to manually restore the contents of our stack to match where it was left off. A basic memory copy will work fine for our purposes. We just need to copy the stack's memory into a buffer when we leave any script mid-execution.
To do all of this we only need to implement two additional key commands. One to get the address pointed to by the stack pointer, and another to modify the stack pointer directly.
// Copy to the stack pointer to local variable
#define TG_SAVE_STACK(var) __asm {mov var, ESP}
// Restore the stack with our own variable
#define TG_RESTORE_STACK __asm {sub ESP, stack}
The size you wish to assign the buffer is arbitrary but it constrains how many things you can store on the stack. We can even be real conservative with our memory and give our scripts a measly 128 bytes for stack space. This does not mean you can only use 128 bytes on the stack, you can use as much as you want, it just means at the point where you are pausing execution, that is the maximum amount at that point that can be in use. If all your scripts do is call functions and do a bit a match, you probably won't even use much memory at all. With this type of memory setup, even after 1000 co-routines, we will just be using about 125K of memory plus any internal structures.
The following are the steps we will need to take in order to run a script and then for the script to return control mid execution.
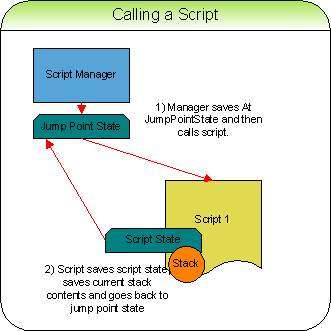
[nbsp]- Call setjmp just before start our script / function. This lets us to take a snapshot of the current CPU state.
- Mark the size of the stack at that point
- Call the C script (function) that we want to run
[nbsp]
When ready to return control back to the program:
[nbsp]- The script calls setjmp to save the state of the CPU at that point of the script
- Make a copy of the stack contents that we've used
- Call longjmp to return the CPU to where it was before we called the script
[nbsp]
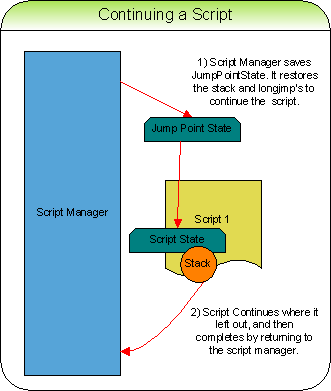
A frame later, we are ready to give some processing time back to the script and allow it to continue.
[nbsp]- Call setjmp to save our current CPU state again.
- Restore the values on to the stack that we have saved from earlier.
- Call longjmp to return the CPU to the state that the script was last in
[nbsp]
The following is some simplified code from the sample code. It checks whether to start a script if it is fresh, and what to do if it needs to continue an old script.
// Mark where are current stack pointer is at
TG_SAVE_STACK(stack);
a_pRoutine->m_StackBegin = stack;
if (setjmp(*(a_pRoutine->m_pExecSystem)) == 0)
{
// New script, spawn
if (a_pRoutine->m_RunState == routineProcedure::RS_START)
{
a_pRoutine->m_RunState = routineProcedure::RS_RUN;
a_pRoutine->m_pFunction(a_pRoutine);
a_pRoutine->m_RunState = routineProcedure::RS_INVALID;
return;
}
else // old script, continues
{
stack = a_pRoutine->m_StackUsed;
TG_RESTORE_STACK;
TG_SAVE_STACK(stack);
// Copy contents of stack for long jumping forward.
memcpy((char*)(stack), a_pRoutine->m_Stack,
a_pRoutine->m_StackUsed);
longjmp(a_pRoutine->m_pExecCurrent, 1);
}
}
The pause macro implements the stop in mid-execution and returns back to the calling function, and the setup to be continued later.
#define PAUSE(time) if (setjmp(a_pProc->m_pExecCurrent) == 0) { \
int volatile stackEnd; \
TG_SAVE_STACK(stackEnd) \
a_pProc->m_PauseTime = time; \
a_pProc->m_StackUsed = a_pProc->m_StackBegin-stackEnd; \
assert (!(a_pProc->m_StackUsed >= STACK_SIZE)); \
memcpy(a_pProc->m_Stack, (void*)stackEnd, a_pProc->m_StackUsed); \
longjmp(*(a_pProc->m_pExecSystem), 1); }
So you are thinking "is this really fast enough to run in my game engine?" The scripts themselves are compiled C or CPP code so they will run at the same speed as the rest of your game engine. The overhead for calling one is about the same as a function call plus an additional memory copy. (See the notes for a way to optimize further by avoiding the memory copy) In terms of raw speed, you will not see much in wasted over-head. You would probably be able to run thousands of these scripts on a typical game without seeing a performance penalty.
Part of this article is a set of sample code that shows an implementation that runs two scripts concurrently. You can uncomment a test case that will run approximately 20,000 co-routines that count from 0 to 15. I think that's far more anyone would reasonably use, but serves an interesting stress test on how little time the routine management actually incurs. The sample code also shows that co-routines are defined in a cross platform manner. It compiles and runs perfectly under Linux GCC for the Playstation2, a platform that is quite different from the standard Intel machine.
To extend on this you could load up additional C - Scripts using a re-locatable code solution such as DLL's, or use a tiny run-time C compiler. The co-routine mechanism has worked very well for me in some extremely complex cases, with hundreds of scripts. Try it in your own game, I would love to hear how it works out for you.Notes
1) Declaring C++ objects on the stack using this method will not be safe unless you know exactly what you're doing. Depending on your compiler flags with exception handling, the destructor for C++ objects may get called during the longjmp out.
2) The performance of the system can be improved by just adjusting the stack pointers to point to memory on the heap instead of copying the stack information around although it raises quite a few other restrictions and issues that will result a in a much more convoluted implementation.
3) On the PS2 the script manager or the jump off point where you call your routines must be compiled with no optimizations in release mode. It is not a big performance issue as you just move the call function to its own file. If anyone figures out a way around this, I would love to know. =)Related links
http://fabrice.bellard.free.fr/tcc/ - Tiny C Compiler
http://www.lua.org - LUA
http://xmailserver.org/libpcl.html - Portable Co-Routine Library
Thanks to Joseph Millman for the editing assistance and feedback.
- Call setjmp to save our current CPU state again.
- The script calls setjmp to save the state of the CPU at that point of the script
- Call setjmp just before start our script / function. This lets us to take a snapshot of the current CPU state.
- A rich feature set with plenty of documentation

