
Introduction
While many simple programs fit into a single C or CPP source file, any serious project is going to become far more manageable if split up into several source files. However, many beginning programmers may not realize what the point of this is - especially since some may have tried it themselves and run into so many problems that they decided it wasn't worth the effort. This article will explain why to do it, and how to do it properly. A brief explanation of how compilers and linkers work will be given where necessary, to help understand why things have to be done in a certain way.
This article was originally published to GameDev.net back in 2002. It was revised by the original author in 2008 and published in the book Beginning Game Programming: A GameDev.net Collection, which is one of 4 books collecting both popular GameDev.net articles and new original content in print format.
Terminology
In this article, I will call standard C and C++ files (usually with the .C or .CPP extension) "source files". This will be to distinguish them from "header files" (usually with the .H or .HPP extension). This terminology is widely used. However, note that the difference is purely conceptual - they are both just text files with code inside them. However, as the rest of the article will show, this difference in the way you treat source and header files is very important.
Why split code into several files?
The first question some novice programmers ask when they see a directory full of separate code files is, "why isn't it all just in one file?" To them, they just don't see the point of scattering the code about. Splitting any reasonably-sized project up buys you some advantages, the most significant of which are the following:
- Reduce time wasted on re-compilation - most compilers work on one a file at a time, and have to process the entire file. So if all your 10000 lines of code is in one file, and you change one line, then you have to recompile 10000 lines of code. On the other hand, if your 10000 lines of code are spread evenly across 10 files, then changing one line will only require 1000 lines of code to be recompiled. The 9000 lines in the other 9 files will not need recompiling.
- Allow distributed or concurrent builds - it is becoming more common for developers to use concurrent builds now, where tools such as "distcc" or "Incredibuild" make it possible for separate source files to be compiled in parallel, either on separate cores or processors on your own computer, or perhaps distributed across other computers on a network. But obviously, if you only have one source file, you can't take advantage of this.
- Increase organization - Splitting your code along logical lines will make it easier for you (and any other programmers on the project) to find functions, variables, struct/class declarations, and so on. Even with the ability to jump directly to a given identifier that is provided in many editors and development environments (such as Microsoft Visual C++), there will always be times when you need to scan the code manually to look for something. Just as splitting the code up reduces the amount of code you need to recompile, it also reduces the amount of code you need to read in order to find something. Imagine that you need to find a fix you made to the sound code a few weeks ago. If you have one large file called GAME.C, that's potentially a lot of searching. If you have several small files called GRAPHICS.C, MAINLOOP.C, SOUND.C, and INPUT.C, you know where to look, cutting your code-browsing time by 3/4.
- Facilitate code reuse - If your code is carefully split up into sections that operate largely independently of each other, this makes it easy to use that code in another project, saving you a lot of rewriting later. There is a lot more to writing reusable code than just using a logical approach to file organization, but without such an organization it is very difficult to know which parts of the code work together and which do not. Therefore putting subsystems and classes in a single file or carefully delineated set of files will help you later if you try to use that code in another project.
- Share code between projects - The principle here is the same as with the reuse issue. By carefully separating code into certain files, you make it possible for multiple projects to use some of the same code files at the same time, without needing to duplicate them. The benefit of sharing a code file between projects rather than just using copy-and-paste is that any bug fixes you make to that file or files from one project will affect the other project, so both projects can be sure of using the most up-to-date version. If you decide to package the shared code into a library later, it will be easier to do if it already lives in files that are separate from the individual programs.
- Split coding responsibilities among programmers - For really large projects, this is perhaps the main reason for separating code into multiple files. It isn't ideal for more than one person to be making changes to a single file at the same time. Version control software such as CVS, Subversion, or even Visual SourceSafe can help to manage this, but the further you split your code up, the less likely you are to use the same file as someone else, and therefore less likely to encounter problems having to merge or coordinate your changes with someone else's.
All of the above can be considered to be aspects of modularity, a key element of both structured and object-oriented design.
How to do it: The Basics
By now you're probably convinced that there are benefits to splitting up your project into several smaller files. So, how would you go about it? Although some of the decisions you make will be reasonably arbitrary, there are some basic rules that you should follow to ensure that it all works. Firstly, look at how you would split your code into logical sections, each handling a conceptually different part of your application. For example, you might be able to split your program up into separate subsystems or 'modules' such as sound, music, graphics, file handling, etc. You generally want one header file for every source file. In C, you might have a header for each subsystem you identified, and a source file containing the function implementations. And occasionally a single module could be split into two or more files, because it might make sense to do so on logical grounds. For example, perhaps your sound engine would split cleanly into code dealing with sound effects and code dealing with music. In C++ it is customary to go a bit further and put each class into its own pair of files - a header containing the class definition and a source file containing the implementation of the various methods. However, this is not really all that different from the C approach, since each class typically corresponds to one distinct area of functionality anyway. Either way, first create new source files with meaningful filenames so that you know at a glance which class or what kind of code is in them. Then move all the code that belongs to that class or module into that file. Once you have split it up in this way into separate source files, the next stage is to consider what will go into the corresponding header files. On a very simple level, code that you usually put at the top of the source file is a prime candidate for moving into a separate header file. This is presumably why they got termed 'header' files, after all. This code to go in a header usually includes some or all of the following:
- class and struct definitions
- typedefs
- function prototypes
- global variable declarations (but see below)
- constants
- #define macros
- #pragma directives
Additionally, when using C++, the definitions for template and inline functions usually need to be in the header file. The reasons for this should become clear later. Global variable declarations differ from a typical variable definition in that they need to be preceded by the 'extern' qualifier. eg. "extern int myGlobalInt;". This is important, but again, more on this later. If you're using namespaces in C++, don't forget to enclose any relevant parts of your header file in that namespace, in much the same way that the functions and variables in question would be within that namespace in your source file. These header files become the interface between your subsystems or classes. By #including a header, you gain access to all the structure definitions, function prototypes, constants etc. for that subsystem. Therefore, every source file that uses sprites in some way will probably have to #include "sprite.h", every source file that uses sound is likely to need to #include "sound.h", and so on. Note that you typically use double quotes rather than angular brackets when #including your own files. The quotes tell the compiler to look for your headers in the program directory first, rather than among the compiler's standard headers. As mentioned earlier, as far as the compiler is concerned there is absolutely no difference between a header file and a source file, both are plain text files that are filled with code (with a small exception: some compilers will refuse to compile a header file directly, assuming that you made a mistake in asking.) The distinction is a conceptual one that programmers must adhere to in order to keep the logical file structure intact. The key idea is that headers contain the interface, and the source files contain the actual implementation. This applies whether you are working in C or C++ in an object-oriented way or a structural way. This means that one source file uses the functionality provided by another source file by including the second source file's header. As a final point of interest, sometimes you have functions that exist purely as local helpers that you won't need to access from outside that file. In C, you would prefix these functions with the 'static' modifier. In C++ if they are not methods of a class, you would enclose them in an unnamed namespace. Since these functions aren't available outside of the source file, they wouldn't form part of the interface, so you wouldn't put their function prototypes in the header. Instead place them at the top of the source file if needed. This allows the other functions in that file to see the prototypes, but keeps them hidden from other files.
Potential Pitfalls
The rules given above are fairly vague and merely serve as a starting point for organizing your code. In simple cases, you can produce completely working programs by following those guidelines. However there are some more details that have to be accounted for, and it is often these details that cause novice programmers so much grief when they first start splitting their code up into header files and source files. Typically, there are four basic errors that people encounter when they first enter the murky world of user-defined header files.
- The source files no longer compile as they can't find the functions or variables that they need. (This often manifests itself in the form of "undeclared identifier" errors, although this can produce any number of different error messages depending on exactly what you are trying to reference.)
- Cyclic dependencies, where headers appear to need to #include each other to work as intended. A Sprite may contain a pointer to the Creature it represents, and a Creature may contain a pointer to the Sprite it uses. No matter how you do this, either Creature or Sprite must be declared first in the code, and that implies that it won't work since the other type isn't declared yet. This "chicken or egg" type of problem manifests itself at compile time in a variety of different ways, such as the compiler saying a class isn't defined when you have clearly included the relevant header, or by a class being redefined, etc.
- Duplicate definitions where a class or identifier ends up being included twice in a single source file. This is a compile time error and usually arises when multiple header files include one other header file, leading to that header being included twice when you compile a source file that uses them. (In MS Visual C++, this might look something like "error C2011: 'MyStruct' : 'struct' type redefinition.)
- Duplicate instances of objects within code that seemed to be fine when files are compiled individually. This is a linking error, and often comes with difficult to understand error messages. (In MS Visual C++, you might see something like "error LNK2005: "int myGlobal" (?myGlobal@@3HA) already defined in myotherfile.obj".)
So how do we prevent or fix these issues?
Fixing Problem 1
Luckily these issues are easy to avoid once you understand them. The first error, where a source file refuses to compile because one of the identifiers was undeclared, is easy to resolve. Simply #include the header file that contains the definition of the identifier you need. If your header files are organized logically and named well, this should be easy. For example, if you need to use the Sprite struct or class, then you probably need to #include "sprite.h" in every file that does so. One mistake that programmers often make is to assume that a file is #included simply because another header #includes it for itself. Example: /* Header1.h */ #include "header2.h" class ClassOne { ... }; /* Header2.h */ class ClassTwo { ... }; /* File1.cpp */ #include "Header1.h" ClassOne myClassOne_instance; ClassTwo myClassTwo_instance; In this case, File1.cpp will compile fine, as including Header1.h has indirectly #included Header2.h, meaning that File1.cpp has access to the Class2 class. But what happens if, at a later date, someone realises that Header1.h doesn't actually need to #include Header2.h? They can remove that #include line, and suddenly File1.cpp will break the next time you try to compile it. Similarly, if the situation arose where File1.cpp no longer required a ClassOne instance, removing that instance and the related #include for would cause the ClassTwo instances to stop compiling. The key here, is to explicitly #include any header files that you need for a given source file to compile. You should never rely on header files indirectly including extra headers for you, as that status may change. The 'extra' #includes also serve as documentation, by demonstrating what other code this file is dependent on. So if you know you need that header included somehow, put the #include line in.
Fixing Problem 2
Cyclic or two-way dependencies are a common problem in software engineering. Many constructs involve a two-way link of some sort, and this implies that both classes and structures know about each other. Often this ends up looking something like this: /* Parent.h */ #include "child.h" class Parent { Child* theChild; }; /* Child.h */ #include "parent.h" class Child { Parent* theParent; }; Given that one of these headers has to be compiled first in order for the other to compile, you need some way to break the cycle. In this case, it's actually quite trivial. The Parent class doesn't actually need to know the details of the Child class, as it only stores a pointer to one. Pointers are pretty much the same no matter what they point to, so you don't need to have the definition of the structure or class in order to store a pointer to an instance of that structure or class. So, the #include line is not actually needed here. However, simply taking it out will give you an "undeclared identifier" error when it encounters the word 'Child', as that class definition is no longer visible, so you need to let the compiler know that Child is a class or class that you wish to point to. This is done with a forward declaration, taking the form of a struct or class definition without a body. Example: /* Parent.h */ class Child; /* Forward declaration of Child; */ class Parent { Child* theChild; }; Notice how the #include line is replaced by the forward declaration. This has allowed you to break the dependency between Parent.h and Child.h. Additionally, it will speed up compilation as you are reading in one less header file. In this case, the same procedure can (and should) be followed in Child.h by forward declaring "class Parent;" As long as you are only referring to a pointer and not the actual type itself, you don't need to #include the full definition. In 99% of cases, this can be applied to one or both sides of a cycle to remove the need to #include one header from another, eliminating the cyclic dependency. When using C++, it's usually preferable to use a reference wherever possible rather than a pointer, as references are less error-prone. As with pointers, a forward declaration of the class being referred to is typically all you need in the header. In the source files, it's quite likely that there will be functions that apply to Parent that will manipulate the Child also, or vice versa. Therefore, it is probably necessary to #include both parent.h and child.h in parent.c and child.c.
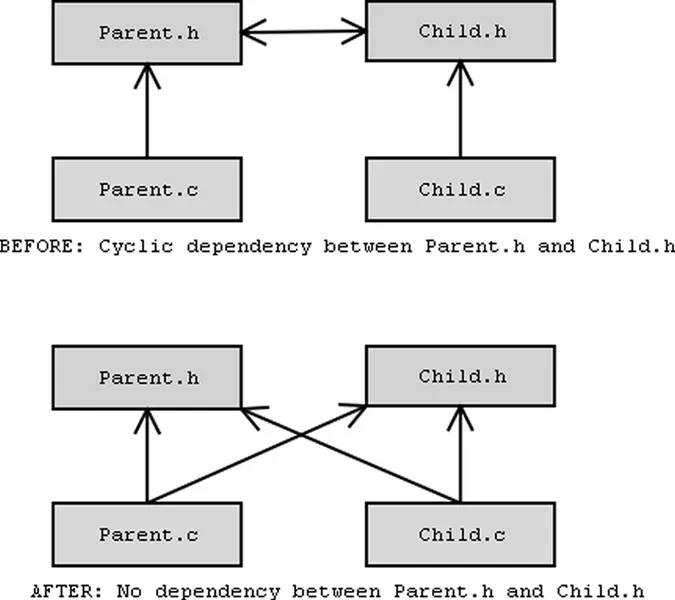
Another situation where cyclic dependencies can often arise in C++ is where inline functions are defined in the header file. Inline functions are potentially faster but typically must be fully defined in the header, rather than just having a prototype (the reason for this will be explained below). However, since the inline function may need to know details of classes it operates on, this tends to mean that the header file it's in will need to #include more headers in order for the function to compile. The first piece of advice here is that you should only make functions inline when you are sure that they are too slow otherwise. If you have tested your code and certain functions absolutely need to be inlined - and thus have their definitions in the header file - try and ensure that the dependency between 2 header files is only one way by isolating the inline functions in one of the two headers. Note that being able to eliminate a dependency entirely is not always possible. Many classes and structs are composed of other classes and structs, which is a dependency you cannot avoid. However, as long as this dependency is one-way, the order of compilation will be fixed and there should be no problem. There are more in-depth ways of resolving cyclic dependencies, but they are beyond the scope of this article. In 99% of cases, using forward declarations and favoring normal functions in C./.CPP files over inline functions in header files will be enough.
Fixing Problem 3
Duplicate definitions at compile time imply that a header ended up being included more than once for a given source file. This leads to a class or struct being defined twice, causing an error. The first thing you should do is ensure that for each source file you only include the headers that you need. This will aid compilation speed since the compiler is not reading and compiling headers that serve no purpose for this file. Sadly, this is rarely enough, since some headers will include other headers. Let's revisit an example from earlier, slightly modified: /* Header1.h */ #include "Header3.h" class ClassOne { ... }; /* Header2.h */ #include "Header3.h" class ClassTwo { ... }; /* File1.cpp */ #include "Header1.h" #include "Header2.h" ClassOne myClassOne_instance; ClassTwo myClassTwo_instance; Header1.h and Header2.h #include Header3.h for some reason. Maybe ClassOne and ClassTwo are composed out of some class defined in Header3.h, or perhaps Header3.h contains basic functionality that is used all over your program. The reason itself is not important; the point is that sometimes headers include other headers indirectly, which means that sometimes a header will end up being #included twice for a given source file despite your best intentions. Note that it doesn't matter that header3.h is being #included from different header files: during compilation, these all resolve to one file. The #include directive literally says "include the specified file right here in this file while we process it", so all the headers get dumped inline into your source file before it gets compiled. The end result looks conceptually something like this:
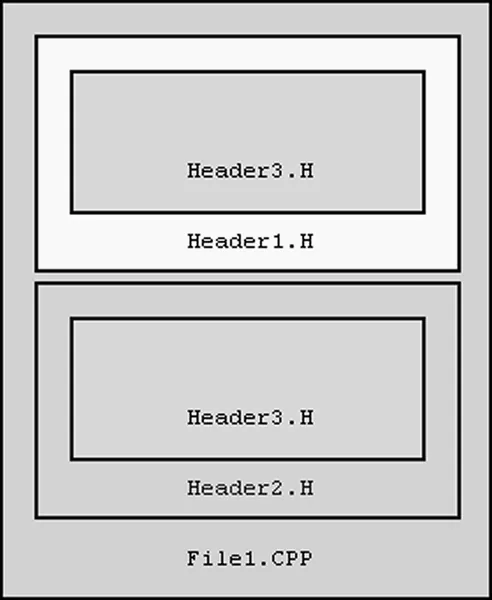
For the purposes of compilation, File1.cpp ends up containing copies of Header1.h and Header2.h, both of which include their own copies of Header3.h. The resulting file, with all headers expanded inline into your original file, is known as a translation unit. Due to this inline expansion, anything declared in Header3.h is going to appear twice in this translation unit, causing an error. So, what do you do? You can't do without Header1.h or Header2.h, since you need to access the structures declared within them. You need some way of ensuring that, no matter what, Header3.h is not going to appear twice in your File1.cpp translation unit when it gets compiled. This is where inclusion guards come in. If you've looked at other people's code, or perhaps through your compiler's standard libraries, you may have noticed lines near the top similar to the following, taken from one compiler's 'stdlib.h': #ifndef _INC_STDLIB #define _INC_STDLIB And at the bottom of the file, after all the important declarations and function prototypes, something like: #endif /* _INC_STDLIB */ This is what is known as an inclusion guard. In plain English, it says "if we haven't defined the symbol "_INC_STDLIB" yet, then define it and continue. Otherwise, skip to the #endif." This is a similar concept to writing the following code to get something to run once: static bool done = false; if (!done) { /* Do something here */ /* Ensure we won't get this far again */ done = true; } This ensures that the 'do something' part only ever happens once. The same principle goes for the inclusion guards. Imagine we included the stdlib.h header described above in File1.cpp. During compilation it would reach the #ifndef line and continues because "_INC_STDLIB" is not yet defined. The very next line defines that symbol and carries on reading in stdlib.h. If stdlib.h is included again during the compilation of File1.cpp, perhaps indirectly through another header, it will read to the #ifndef check and then skip to the #endif at the end of the file, leaving out all the declarations in the middle. This is because everything between the #ifndef and the #endif is only executed if "_INC_STDLIB" is not defined; and it got defined the first time we included it. This way, it is ensured that the definitions within stdlib.h are only ever included once by putting them within this #ifndef / #endif pair. This is trivial to apply to your own projects. At the start of every header file you write, put the following: #ifndef INC_FILENAME_H #define INC_FILENAME_H Note that the symbol (in this case, "INC_FILENAME_H") needs to be unique across your project. This is why it is a good idea to incorporate the filename into the symbol. Don't add an underscore at the start like stdlib.h does, as identifiers starting with an underscore followed by a capital letter are supposed to be reserved for "the implementation" (ie. the compiler, the standard libraries, and so on). Then add the #endif /* INC_FILENAME_H */ at the end of the file. The comment is not necessary, but will help you remember what that #endif is there for. On a related note, you may have also noticed the "#pragma once" directive used occasionally at the top of a header file. This effectively achieves the same thing as the inclusion guards, without having to worry about filenames, or adding the #endif at the bottom of the file, by saying that "for this translation unit, only include this file once". However, remember that this, as with all #pragma directives, is not standard across all compilers. Although the Visual C++ and GCC compilers support the #pragma once directive, not all do, so it's a good habit to use the standard inclusion guard mechanism anyway, even if you do use #pragma once. With inclusion guards in all your headers, there should be no way for any given header's contents to end up included more than once in any translation unit, meaning you should get no more compile-time redefinition errors. So that's compile-time redefinition fixed. But what about the link-time duplicate definition problems?
Fixing Problem 4
When the linker comes to create an executable (or library) from your code, it takes all the object (.obj or .o) files it created during compilation, one per translation unit, and joins them together. The linker's main job is to resolve identifiers (basically, variable or function names) to machine addresses in the file. This is what links the various object files together. The problem arises when the linker finds two or more instances of a single identifier in the object files, as then it cannot determine which the 'correct' one to use is. The identifier should be unique to avoid any such ambiguity. So how come the compiler doesn't see an identifier as being duplicated, yet the linker does? Imagine the following code, showing a global variable used in 2 files: /* Header.h */ #ifndef INC_HEADER_H #define INC_HEADER_H int my_global; #endif /* INC_HEADER_H */ /* code1.cpp */ #include "header1.h" void DoSomething() { ++my_global; } /* code2.cpp */ #include "header1.h" void DoSomethingElse() { --my_global; } This first gets compiled into two object files, called something like code1.obj and code2.obj. Remember that a translation unit contains full copies of all the headers included by the file you are compiling. Finally, the object files are combined to produce the final file. Here's a visual depiction of the way these files (and their contents) are combined:
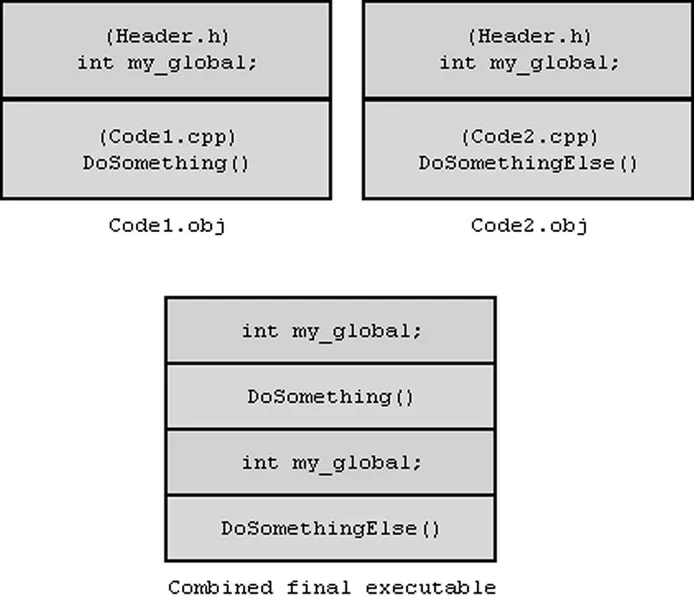
Notice how there are two copies of "my_global" in that final block. Although "my_global" was unique within each translation unit (this would be assured by the correct use of the inclusion guards), combining the object files generated from each translation unit would result in there being more than one instance of my_global in the file. This is flagged as an error, as the linker has no way of knowing whether these two identifiers are actually supposed to be the same one, or if one of them was just misnamed and they were actually supposed to be 2 separate variables. So you have to fix it. The answer is not to define variables or functions in headers. Instead, you define them in the source files where you can be sure that they will only get compiled once (assuming you don't ever #include any source files, which is a bad idea for exactly this reason). This gives you a new problem: how do you make the functions and variables globally visible if they aren't in a common header any more? How will other files "see" them? The answer is to declare the functions and variables in the header, but not to define them. This subtle distinction lets the compiler know that the function or variable exists, but delegates the act of resolving the address to the linker. To do this for a variable, you add the keyword 'extern' before its name: extern int my_global; The 'extern' specifier is like telling the compiler to wait until link time to resolve the 'connection'. And for a function, you just put the function prototype -- the first line of the function without the body: int SomeFunction(int parameter); Functions are considered 'extern' by default so it is customary to omit the 'extern' in a function prototype. Of course, since these are just declarations that my_global and SomeFunction exist somewhere, it doesn't actually create them. You still have to do this in one of the source files, as otherwise you will see a new linker error when it finds it cannot resolve one of the identifiers to an actual variable or function. So for this example, you would add "int my_global" to either Code1.cpp or Code2.cpp, and everything should work fine. If it was a function, you'd add the function including its body (the code of the function) into one of the source files. The rule here is to remember that header files define an interface, not an implementation. They specify which functions, variables, and objects exist, but it is not responsible for creating them. They may say what a struct or class must contain, but it shouldn't actually create any instances of that struct or class. They can specify what parameters a function takes and what it returns, but not how it gets the result. And so on. This is why the list of what can go into a header file earlier in this article is important. For convenience, some people like to put all the 'extern' declarations into a Globals.h file and all the actual definitions into a Globals.cpp file. Of course, most experienced programmers would tell you that global variables are generally bad, and therefore making an effort to reduce or eliminate them will improve your program anyway. Besides, most so-called globals don't need to be truly global. Your sound module probably doesn't need to see your Screen object or your Keyboard object. So try to keep variables in their own modules rather than placing them all together just because they happen to be 'global'. There are two notable exceptions to the "no function bodies in header files", because although they look like function bodies, they aren't exactly the same. The first exception is that of template functions. Most compilers and linkers can't handle templates being defined in different files to that which they are used in, so templates almost always need to be defined in a header so that the definition can be included in every file that needs to use it. Because of the way templates are instantiated in the code, this doesn't lead to the same errors that you would get by defining a normal function in a header. This is because templates aren't actually compiled at the place of definition, but are generated and compiled as they are used by code elsewhere. The second exception is inline functions, briefly mentioned earlier. Like template functions, inline functions are not like normal functions, but are blueprints for different code depending on how they're used. An inline function is compiled directly into the code that calls it, rather than called in the normal way. This means that any translation unit where the code 'calls' an inline function needs to be able to see the inner workings (the implementation) of that function in order to insert that function's code directly. This means that a simple function prototype is insufficient for calling the inline function, meaning that wherever you would normally just use a function prototype, you need the whole function body for an inline function. As with templates, this doesn't cause linker errors as the inline function is not actually compiled at the place of definition, but is inserted at the place of calling.
Other Considerations
So, your code is nicely split across various files, giving you all the benefits mentioned at the start like increased compilation speed and better organization. Is there anything else you need to know? Firstly, if you use the C++ standard library, or any other library that uses namespaces, you may find yourself using their identifiers in your header files. If so, don't use the "using" keyword in your headers, as it reduces the effectiveness of namespaces almost to the point of uselessness. Instead, put the using keyword in the source files if necessary, and explicitly qualify the names with their namespace prefix in the header files. Otherwise, when you start using functions that have the same names as the standard library, whether your own or from another library, you'll either have to start renaming them or go back and edit your header anyway, which in turn will affect all the files that depend on it. Better to do it properly in the first place. Secondly, the use of macros should be carefully controlled. C programmers have to rely on macros for a lot of functionality, but C++ programmers should avoid them wherever possible. If you want a constant in C++, use the 'const' keyword, and if you want an inline function in C++, use the 'inline' keyword. If you want a function that operates on different types in C++, use templates or overloading. But if you do need to use a macro for some reason, and you place it in a header file, try not to write macros that could potentially interfere with code in the files that include it. When you get weird compilation errors, you don't want to have to search through every header file to see if someone used a #define to inadvertently change your function or its parameters to something else. So wherever possible, keep macros out of headers unless you can be sure that you don't mind them affecting everything in the project.
Conclusion
If done properly, organizing your files this way can speed your development without hindering you at all or introducing any extra problems. Although it seems like there is a lot to consider when doing so, it becomes second nature in no time. Just remember these key points:
- Split your code up along logical module divisions
- Put the interface into the header files and the implementation into the source files
- Use forward declarations wherever possible to reduce dependencies
- Add an inclusion guard to every header file you make
- Don't put code in the headers that might adversely affect source files that include it
Good luck!




Nice article, it remembers me of a lot of time I've wasted when not knowing this :)