
It is good for programmers to understand what goes on inside a processor. The CPU is at the heart of our career.
What goes on inside the CPU? How long does it take for one instruction to run? What does it mean when a new CPU has a 12-stage pipeline, or 18-stage pipeline, or even a "deep" 31-stage pipeline?
Programs generally treat the CPU as a black box. Instructions go into the box in order, instructions come out of the box in order, and some processing magic happens inside.
As a programmer, it is useful to learn what happens inside the box. This is especially true if you will be working on tasks like program optimization. If you don't know what is going on inside the CPU, how can you optimize for it?
This article is about what goes on inside the x86 processor's deep pipeline.
Stuff You Should Already Know
First, this article assumes you know a bit about programming, and maybe even a little assembly language. If you don't know what I mean when I mention an instruction pointer, this article probably isn't for you. When I talk about registers, instructions, and caches, I assume you already know what they mean, can figure it out, or will look it up.
Second, this article is a simplification of a complex topic. If you feel I have left out important details, please add them to the comments at the end.
Third, I am focusing on Intel processors and the x86 family. I know there are many different processor families out there other than x86. I know that AMD introduced many useful features into the x86 family and Intel incorporated them. It is Intel's architecture and Intel's instruction set, and Intel introduced the most major feature being covered, so for simplicity and consistency I'm just going to stick with their processors.
Fourth, this article is already out of date. Newer processors are in the works and some are due out in a few months. I am very happy that technology is advancing at a rapid pace. I hope that someday all of these steps are completely outdated, replaced with even more amazing advances in computing power.
The Pipeline Basics
From an extremely broad perspective the x86 processor family has not changed very much over its 35 year history. There have been many additions but the original design (and nearly all of the original instruction set) is basically intact and visible in the modern processor.
The original 8086 processor has 14 CPU registers which are still in use today. Four are general purpose registers -- AX, BX, CX, and DX. Four are segment registers that are used to help with pointers -- Code Segment (CS), Data Segment (DS), Extra Segment (ES), and Stack Segment (SS). Four are index registers that point to various memory locations -- Source Index (SI), Destination Index (DI), Base Pointer (BP), and Stack Pointer (SP). One register contains bit flags. And finally, there is the most important register for this article: The Instruction Pointer (IP).
The instruction pointer's job is to point to the next instruction to be run. Usually it is updated every tick by the CPU internally.
All processors in the x86 family follow the same pattern. First, they follow the instruction pointer and decode the next CPU instruction at that location. After decoding, there is an execute stage where the instruction is run. Some instructions read from memory or write to it, others perform calculations or comparisons or do other work. When the work is done, the instruction goes through a retire stage and the instruction pointer is modified to point to the next instruction.
This decode, execute, and retire pipeline pattern applies to the original 8086 processor as much as it applies to the latest Core i7 processor. Additional pipeline stages have been added over the years, but the pattern remains.
What Has Changed Over 35 Years
The original processor was simple by today's standard. The original 8086 processor began by evaluating the instruction at the current instruction pointer, decoded it, executed it, retired it, and moved on to the next instruction that the instruction pointer pointed to.
Each new chip in the family added new functionality. Most chips added new instructions. Some chips added new registers. For the purposes of this article I am focusing on the changes that affect the main flow of instructions through the CPU. Other changes like adding virtual memory or parallel processing are certainly interesting and useful, but not applicable to this article.
In 1982 an instruction cache was added to the processor. Instead of jumping out to memory at every instruction, the CPU would read several bytes beyond the current instruction pointer. The instruction cache was only a few bytes in size, just large enough to fetch a few instructions, but it dramatically improved performance by removing round trips to memory every few cycles.
In 1985, the 386 added cache memory for data as well as expanding the instruction cache. This gave performance improvements by reading several bytes beyond a data request. By this point both the instruction cache and data cache were measured in kilobytes rather than bytes.
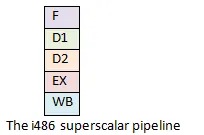
In 1989, the i486 moved to a five-stage pipeline. Instead of having a single instruction inside the CPU, each stage of the pipeline could have an instruction in it. This addition more than doubled the performance of a 386 processor of the same clock rate. The fetch stage extracted an instruction from the cache. (The instruction cache at this time was generally 8 kilobytes.) The second stage would decode the instruction. The third stage would translate memory addresses and displacements needed for the instruction. The fourth stage would execute the instruction. The fifth stage would retire the instruction, writing the results back to registers and memory as needed. By allowing multiple instructions in the processor at once, programs could run much faster.
1993 saw the introduction of the Pentium processor. The processor family changed from numbers to names as a result of a lawsuit--that's why it is Pentium instead of the 586. The Pentium chip changed the pipeline even more than the i486. The Pentium architecture added a second separate superscalar pipeline. The main pipeline worked like the i486 pipeline, but the second pipeline ran some simpler instructions, such as direct integer math, in parallel and much faster.
In 1995, Intel released the Pentium Pro processor. This was a radically different processor design. This chip had several features including out-of-order execution processing core (OOO core) and speculative execution. The pipeline was expanded to 12 stages, and it included something termed a 'superpipeline' where many instructions could be processed simultaneously. This OOO core will be covered in depth later in the article.
There were many major changes between 1995 when the OOO core was introduced and 2002 when our next date appears. Additional registers were added. Instructions that processed multiple values at once (Single Instruction Multiple Data, or SIMD) were introduced. Caches were introduced and existing caches enlarged. Pipeline stages were sometimes split and sometimes consolidated to allow better use in real-world situations. These and other changes were important for overall performance, but they don't really matter very much when it comes to the flow of data through the chip.
In 2002, the Pentium 4 processor introduced a technology called Hyper-Threading. The OOO core was so successful at improving processing flow that it was able to process instructions faster than they could be sent to the core. For most users the CPU's OOO core was effectively idle much of the time, even under load. To help give a steady flow of instructions to the OOO core they attached a second front-end. The operating system would see two processors rather than one. There were two sets of x86 registers. There were two instruction decoders that looked at two sets of instruction pointers and processed both sets of results. The results were processed by a single, shared OOO core but this was invisible to the programs. Then the results were retired just like before, and the instructions were sent back to the two virtual processors they came from.
In 2006, Intel released the "Core" microarchitecture. For branding purposes, it was called "Core 2" (because everyone knows two is better than one). In a somewhat surprising move, CPU clock rates were reduced and Hyper-Threading was removed. By slowing down the clock they could expand all the pipeline stages. The OOO core was expanded. Caches and buffers were enlarged. Processors were re-designed focusing on dual-core and quad-core chips with shared caches.
In 2008, Intel went with a naming scheme of Core i3, Core i5, and Core i7. These processors re-introduced Hyper-Threading with a shared OOO core. The three different processors differed mainly by the size of the internal caches. Future Processors: The next microarchitecture update is currently named Haswell and speculation says it will be released late in 2013.
So far the published docs suggest it is a 14-stage OOO core pipeline, so it is likely the data flow will still follow the basic design of the Pentium Pro. So what is all this pipeline stuff, what is the OOO core, and how does it help processing speed?
CPU Instruction Pipelines
In the most basic form described above, a single instruction goes in, gets processed, and comes out the other side. That is fairly intuitive for most programmers.
The i486 has a 5-stage pipeline. The stages are - Fetch, D1 (main decode), D2 (secondary decode, also called translate), EX (execute), WB (write back to registers and memory). One instruction can be in each stage of the pipeline.

There is a major drawback to a CPU pipeline like this. Imagine the code below. Back before CPU pipelines the following three lines were a common way to swap two variables in place.
XOR a, b
XOR b, a
XOR a, b
The chips starting with the 8086 up through the 386 did not have an internal pipeline. They processed only a single instruction at a time, independently and completely. Three consecutive XOR instructions is not a problem in this architecture.
We'll consider what happens in the i486 since it was the first x86 chip with an internal pipeline. It can be a little confusing to watch many things in motion at once, so you may want to refer back to the diagram above.
The first instruction enters the Fetch stage and we are done with that step. On the next step the first instruction moves to D1 stage (main decode) and the second instruction is brought into fetch stage. On the third step the first instruction moves to D2 and the second instruction gets moved to D1 and another is fetched. On the next stage something goes wrong. The first instruction moves to EX ... but other instructions do not advance. The decoder stops because the second XOR instruction requires the results of the first instruction. The variable (a) is supposed to be used by the second instruction, but it won't be written to until the first instruction is done. So the instructions in the pipeline wait until the first instruction works its way through the EX and WB stages. Only after the first instruction is complete can the second instruction make its way through the pipeline. The third instruction will similarly get stuck, waiting for the second instruction to complete.
This is called a pipeline stall or a pipeline bubble.
Another issue with pipelines is some instructions could execute very quickly and other instructions would execute very slowly. This was made more visible with the Pentium's dual-pipeline system.
The Pentium Pro introduced a 12-stage pipeline. When that number was first announced there was a collective gasp from programmers who understood how the superscalar pipeline worked. If Intel followed the same design with a 12-stage superscalar pipeline then a pipeline stall or slow instruction would seriously harm execution speed. At the same time they announced a radically different internal pipeline, calling it the Out Of Order (OOO) core. It was difficult to understand from the documentation, but Intel assured developers that they would be thrilled with the results.
Let's have a look at this OOO core pipeline in more depth.
The Out Of Order Core Pipeline
The OOO Core pipeline is a case where a picture is worth a thousand words. So let's get some pictures.
Diagrams of CPU Pipelines
The i486 had a 5-stage pipeline that worked well. The idea was very common in other processor families and works well in the real world.
The Pentium pipeline was even better than the i486. It had two instruction pipelines that could run in parallel, and each pipeline could have multiple instructions in different stages. You could have nearly twice as many instructions being processed at the same time.

Having fast instructions waiting for slow instructions was still a problem with parallel pipelines. Having sequential instruction order was another issue thanks to stalls. The pipelines are still linear and can face a performance barrier that cannot be breached.
The OOO core is a huge departure from the previous chip designs with their linear paths. It added some complexity and introduced nonlinear paths:
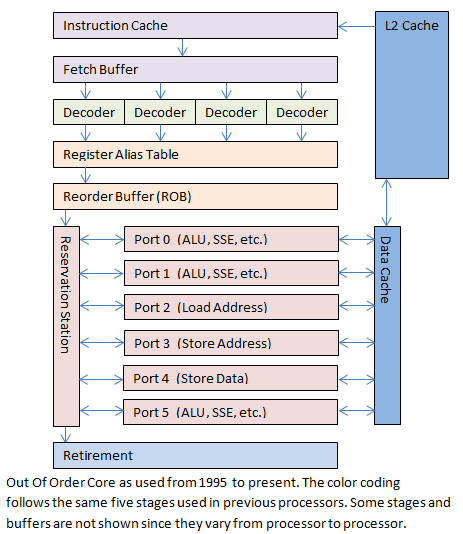
The first thing that happens is that instructions are fetched from memory into the processor's instruction cache. The decoder on the modern processors can detect when a large branch is about to happen (such as a function call) and can begin loading the instructions before they are needed.
The decoding stage was modified slightly from earlier chips. Instead of just processing a single instruction at the instruction pointer, the Pentium Pro processor could decode up to three instructions per cycle. Today's (circa 2008-2013) processors can decode up to four instructions at once. Decoding produces small fragments of operations called micro-ops or u-ops.
Next is a stage (or set of stages) called micro-op translation, followed by register aliasing. Many operations are going on at once and we will potentially be doing work out of order, so an instruction could read to a register at the same time another instruction is writing to it. Writing to a register could potentially stomp on a value that another instruction needs. Inside the processor the original registers (such as AX, BX, CX, DX, and so on) are translated (or aliased) into internal registers that are hidden from the programmer. The registers and memory addresses need to have their values mapped to a temporary value for processing. Currently 4 micro-ops can go through translation every cycle.
After micro-op translation is complete, all of the instruction's micro-ops enter a reorder buffer, or ROB. The ROB currently holds up to 128 micro-ops. On a processor with Hyper-Threading the ROB can also coordinate entries from multiple virtual processors. Both virtual processors come together into a single OOO core at the ROB stage.
These micro-ops are now ready for processing. They are placed in the Reservation Station (RS). The RS currently can hold 36 micro-ops at any one time.
Now the magic of the OOO core happens. The micro-ops are processed simultaneously on multiple execution units, and each execution unit runs as fast as it can. Micro-ops can be processed out of order as long as their data is ready, sometimes skipping over unready micro-ops for a long time while working on other micro-ops that are ready. This way a long operation does not block quick operations and the cost of pipeline stalls is greatly reduced.
The original Pentium Pro OOO core had six execution units: two integer processors, one floating-point processor, a load unit, a store address unit, and a store data unit. The two integer processors were specialized; one could handle the complex integer operations, the other could solve up to two simple operations at once. In an ideal situation the Pentium Pro OOO Core execution units could process seven micro-ops in a single clock cycle.
Today's OOO core still has six execution units. It still has the load address, store address, and store data execution units, the other three have changed somewhat. Each of the three execution units perform basic math operations, or instead they perform a more complex micro-op. Each of the three execution units are specialized to different micro-ops allowing them to complete the work faster than if they were general purpose. In an ideal situation today's OOO core can process 11 micro-ops in a single cycle.
Eventually the micro-op is run. It goes through a few more small stages (which vary from processor to processor) and eventually gets retired. At this point it is returned back to the outside world and the instruction pointer is advanced. From the program's point of view the instruction has simply entered the CPU and exited the other side in exactly the same way it did back on the old 8086.
If you were following carefully you may have noticed one very important issue in the way it was just described. What happens if there is a change in execution location? For example, what happens when the code hits an 'if' statement or a 'switch" statement? On the older processors this meant discarding the work in the superscalar pipeline and waiting for the new branch to begin processing.
A pipeline stall when the CPU holds one hundred instructions or more is an extreme performance penalty. Every instruction needs to wait while the instructions at the new location are loaded and the pipeline restarted. In this situation the OOO core needs to cancel work in progress, roll back to the earlier state, wait until all the micro-ops are retired, discard them and their results, and then continue at the new location. This was a very difficult problem and happened frequently in the design. The performance of this situation was unacceptable to the engineers. This is where the other major feature of the OOO core comes in. Speculative execution was their answer.
Speculative execution means that when a conditional statement (such as an 'if' block) is encountered the OOO core will simply decode and run all the branches of the code. As soon as the core figures out which branch was the correct one, the results from the unused branches would be discarded. This prevents the stall at the small cost of running the code inside the wrong branch. The CPU designers also included a branch prediction cache which further improved the results when it was forced to guess at multiple branch locations. We still have CPU stalls from this problem, but the solutions in place have reduced it to the point where it is a rare exception rather than a usual condition.
Finally, CPUs with Hyper-Threading enabled will expose two virtual processors for a single shared OOO core. They share a Reorder Buffer and OOO core, appearing as two separate processors to the operating system. That looks like this:
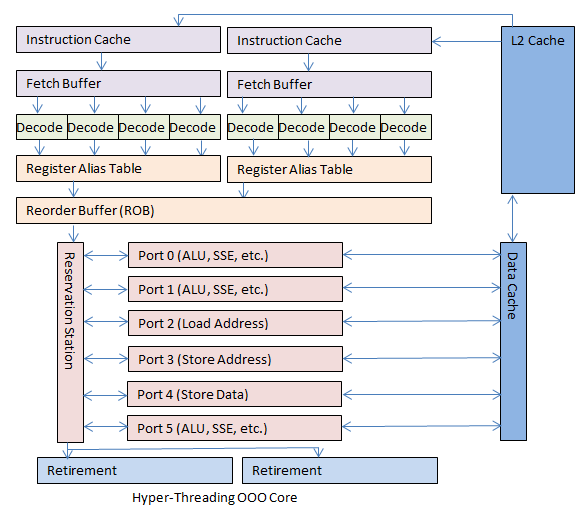
A processor with Hyper-Threading gives two virtual processors which in turn gives more data to the OOO core. This gives a performance increase during general workloads. A few compute-intensive workflows that are written to take advantage of every processor can saturate the OOO core. During those situations Hyper-Threading can slightly decrease overall performance. Those workflows are relatively rare; Hyper-Threading usually provides consumers with approximately double the speed they would see for their everyday computer tasks.
An Example
All of this may seem a little confusing. Hopefully an example will clear everything up.
From the application's perspective, we are still running on the same instruction pipeline as the old 8086. There is a black box. The instruction pointed to by the instruction pointer is processed by the black box, and when it comes out the results are reflected in memory.
From the instruction's point of view, however, that black box is quite a ride.
Here is today's (circa 2008-2013) CPU ride, as seen by an instruction:
First, you are a program instruction. Your program is being run.
You are waiting patiently for the instruction pointer to point to you so you can be processed. When the instruction pointer gets about 4 kilobytes away from you -- about 1500 instructions away -- you get collected into the instruction cache. Loading into the cache takes some time, but you are far away from being run. This prefetch is part of the first pipeline stage.
The instruction pointer gets closer and closer. When the instruction pointer gets about 24 instructions away, you and five neighbors get pulled into the instruction queue.
This processor has four decoders. It has room for one complex instruction and up to three simple instructions. You happen to be a complex instruction and are decoded into four micro-ops.
Decoding is a multi-step process. Part of the decode process involved a scan to see what data you need and if you are likely to cause a jump to somewhere new. The decoder detected a need for some additional data. Unknown to you, somewhere on the far side of the computer, your data starts getting loaded into the data cache.
Your four micro-ops step up to the register alias table. You announce which memory address you read from (it happens to be fs:[eax+18h]) and the chip translates that into temporary addresses for your micro-ops. Your micro-ops enter the reorder buffer, or ROB. At the first available opportunity they move to the Reservation Station.
The Reservation Station holds instructions that are ready to be run. Your third micro-op is immediately picked up by Execution Port 5. You don't know why it was selected first, but it is gone. A few cycles later your first micro-op rushes to Port 2, the Load Address execution unit. The remaining micro-ops wait as various ports collect other micro-ops. They wait as Port 2 loads data from the memory cache and puts it in temporary memory slots.
They wait a long time...
A very long time...
Other micro-ops come and go while you wait for your micro-op to load the right data. Good thing this processor knows how to handle things out of order.
Suddenly both of the remaining micro-ops are picked up by Execution Ports 0 and 1. The data load must be complete. The micro-ops are all run, and eventually the four micro-ops meet back in the Reservation Station.
As they travel back through the gate the micro-ops hand in their tickets listing their temporary addresses. The micro-ops are collected and joined, and you, as an instruction, feel whole again. The CPU hands you your result, and gently directs you to the exit.
There is a short line through a door marked "Retirement". You get in line, and discover you are standing next to the same instructions you came in with. You are even standing in the same order. It turns out this out-of-order core really knows its business.
You and your neighboring instructions all exit the CPU together, in the same order pointed to by the instruction pointer.
Conclusion
This little lecture has hopefully shed some light on what happens inside a CPU. It isn't all magic, smoke, and mirrors.
Getting back to the original questions, we now have some good answers.
What goes on inside the CPU? There is a complex world where instructions are broken down into micro-operations, processed as soon as possible in any order, then put back together in order and in place. To an outsider it looks like they are being processed sequentially and independently. But now we know that on the inside they are handled out of order, sometimes even running braches of code based on a prediction that they will be useful.
How long does it take for one instruction to run? While there was a good answer to this in the non-pipelined world, in today's processors the time it takes is based on what instructions are nearby, and the size and contents of the neighboring caches. There is a minimum amount of time it takes to go through the processor, but that is roughly constant. A good programmer and optimizing compiler can make many instructions run in around amortized zero time. With an amortized zero time it is not the cost of the instruction that is slow; instead it means it takes the time to work through the OOO core and the time to wait for cache memory to load and unload.
What does it mean when a new CPU has a 12-stage pipeline, or 18-stage, or even a "deep" 31-stage pipeline? It means more instructions are invited to the party at once. A very deep pipeline can mean that several hundred instructions can be marked as 'in progress' at once. When everything is going well the OOO core is kept very busy and the processor gains an impressive throughput of instructions. Unfortunately, this also means that a pipeline stall moves from being a mild annoyance like it was in the early days, to becoming a performance nightmare as hundreds of instructions need to wait around for the pipeline to clear out.
How can I apply this to my programs? The good news is that CPUs can anticipate most common patterns, and compilers have been optimizing for OOO core for nearly two decades. The CPU runs best when instructions and data are all in order. Always keep your code simple. Simple and straightforward code will help the compiler's optimizer identify and speed up the results. Don't jump around if you can help it, and if you need to jump, try to jump around exactly the same way every time. Complex designs like dynamic jump tables are fancy and can do a lot, but neither the compiler or CPU will predict what will be coming up, so complex code is very likely to result in stalls and mis-predictions. On the other side, keep your data simple. Keep your data in order, adjacent, and consecutive to prevent data stalls. Choosing the right data structures and data layouts can do much to encourage good performance. As long as you keep your code and data simple you can generally rely on your compiler's optimizer to do the rest.
Thanks for joining me on the ride.
updates
2013-05-17 Removed a word that bothered someone.
2020-10-21 Adjust formatting to restore paragraph breaks.










There is still a case where you can be hit having to deal with an In Order CPU in games development and this is when you are writing code for a PS3 or X360(I know these aren't intel CPU's), just wanted to mention this otherwise very good article and very informative.